In William Shakespeare's Hamlet, one of my favorite plays, Prince Hamlet is approached by Polonius, chief counselor to Claudius, King of Denmark, who happens to be Hamlet's stepfather, and uncle, and the new husband of his mother, Queen Gertrude, whose recently deceased last husband was the previous King of Denmark. That would be Hamlet's biological father for those who might be having trouble following along. He was King Hamlet. Polonius, I probably should mention, is also the father of Hamlet's sweetheart, Ophelia. Despite this hilarious sounding setup, Hamlet is most definitely not a comedy. (Note: if you need a refresher, you can read Hamlet here.)
For reasons I won't go into here, Hamlet is doing a great job of trying to convince people that he's completely lost it and is pretending to be reading a book when Polonius approaches and asks, "What do you read, my lord?"
Hamlet replies by saying, "'Words, words, words." In other words, ahem, nothing of any importance, you annoying little man.
Shakespeare wrote a lot of words. In fact, writers, businesses and organizations of any size tend to amass a lot of words in the form of countless documents, many of which seem to contain a great deal of importance at the time they are written and subsequently stored on some lonely corporate server. There, locked in their digital prisons, these many texts await the day when somebody will seek out their wisdom. Trouble is, there are so many of them, in many different formats, often with titles that tell you nothing about the content inside. What you need is a search engine.
Google is a pretty awesome search engine, but it's not for everybody, especially if the documents in question aren't meant for consumption by the public at large. For those times, you need your own search engine, combined with a crawler that will index all sorts of documents, from OpenDocument format, to old Microsoft Docs, to PDFs and even plain text. That's where OpenSearchServer comes into play. OpenSearchServer is, as the name implies, an open-source project designed to perform the function of crawling through and indexing large collections of documents, such as you would find on a website.
I'm going to show you how to go about getting this documentation site set up from scratch so that you can see all the steps. You may, of course, already have a web server up and running, and that's fine. I've gone ahead and spun up a Linode server running Ubuntu 18.04 LTS. This is a great way to get a server up and running quickly without spending a lot of money if you don't want to, and if you've never done this, it's also kind of fun.
First, you're going to need a web server, and since I usually install Apache, today I'm going to go with nginx for a change:
sudo apt install nginx
This is going to be a fairly simple setup, since you'll be running only one website on this server. You still need to make sure the configuration for the server is correct, since you'll have a whole collection of documents to store on this server. In the spirit of this article, I created a DNS entry for my server, which I've called "thebard", and placed it under my domain. So, to get this server up and running, I create a host configuration file, referred to as a "server block" under the /etc/nginx/conf.d directory, called thebard.marcelgagne.com.conf.
Using your favorite text editor (for example, vim), edit the file to look something like this:
server {
listen 80;
listen [::]:80;
server_name thebard.marcelgagne.com;
root /var/www/thebard;
index index.html;
gzip on;
gzip_comp_level 3;
gzip_types text/plain text/css application/javascript
image/*;
}
If you're following along, you're obviously going to assign server_name something other than what I did. Furthermore, you can use any folder you want for your files. I created a directory called thebard to store my documents under the classic /var/www. Nginx's default user, on Ubuntu anyhow, is www-data, so you'll want to change ownership of whatever directory you chose, so that the files belong to that user and group:
chown -R www-data:www-data /var/www/thebard
One last thing and you're ready to go. To make sure everything works, create a tiny index.html file for the default directory:
<html>
<head>
<title>My Shakespearean Site</title>
</head>
<body>
<H1>You are here and so am I.</H1>
</body>
</html>
And now, let's start/restart the nginx server:
service nginx restart
If all has gone well up to this point, you can visit your server using your favorite web browser (Figure 1).

Figure 1. So for so good
You're going to want a place for all these documents to live. For that, I've created a directory under the root of this server called "Documents". I know; it's original. In that folder, I've transferred a number of classic documents in various formats. To view the files under the directory, you're going to add a small paragraph to the server block created above. Just before the final bracket, add this paragraph:
location /Documents {
autoindex on;
}
Save the file and restart the nginx process, then point your browser to http://yourserver.dom/Documents. You should see a directory listing like the one shown in Figure 2.
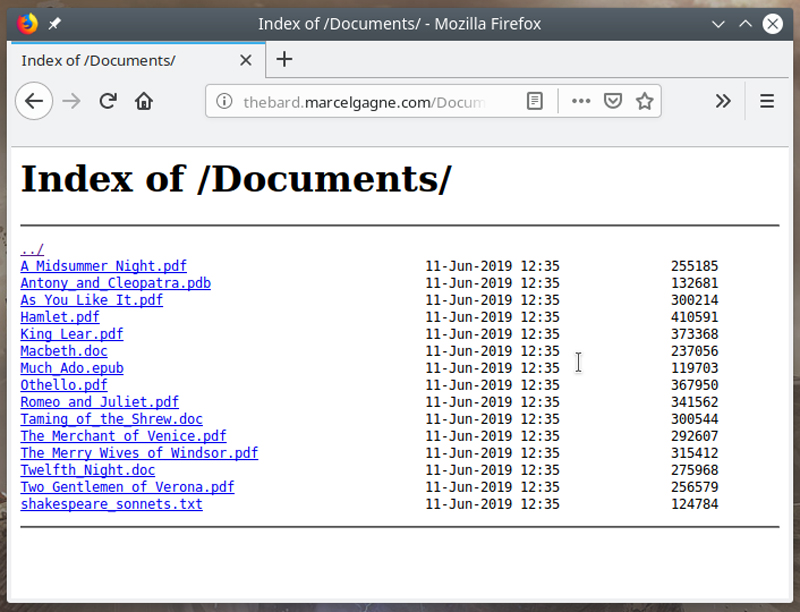
Figure 2. The Bard's Documents
Pretend for a moment, that you have the entire catalog of Shakespeare's works here instead of the handful I added for demonstration. Add to that a few thousand other documents, and it starts to look like a good reason for a search engine that can index all of those things. Your own organization or company (or yourself, if you're a writer) may have hundreds and even several thousand documents. Furthermore, those documents likely will be in a variety of formats, which is why I uploaded versions in PDF, Microsoft Word and plain-old text for my demonstration.
So let's install that search engine, shall we?
From the OpenSearchServer site at http://www.opensearchserver.com, download the latest package for your particular distribution. The code for OpenSearchServer is written in Java, so to make it all work, you're also going to need a recent JDK. Let's install both now:
sudo apt install openjdk-8-jdk
sudo dpkg -i opensearchserver-1.5.14-d0d167e.deb
Once installed, you can just start the server like this:
sudo service opensearchserver start
It does take a few seconds for the server to start up, so you might want to grab something to drink here. By default, OpenSearchServer runs on port 9090, but you can change that default by editing /etc/opensearchserver and changing SERVER_PORT=9090 to something that suits your particular network. If you do, make sure you restart the opensearchserver before you try connecting. Assuming the default port, pointing your browser to http://yourserver.dom:9090 should give you something that looks like Figure 3.
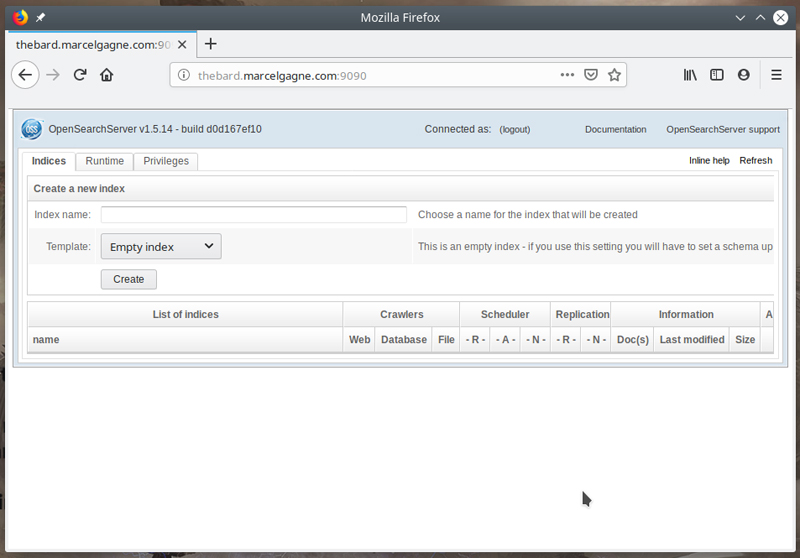
Figure 3. The Default OpenSearchServer Front Page
This is where things get even more exciting. On that first page, notice where it says "Index name", where you are invited to "Create a new index" (see close up Figure 4). You can call your index whatever you like, but I'm calling mine "ManyWords", not to be confused with ManyWorlds, which I'd use if I were creating an index of all the documents written about the Many World Interpretation (MWI) of quantum mechanics. But, I digress.
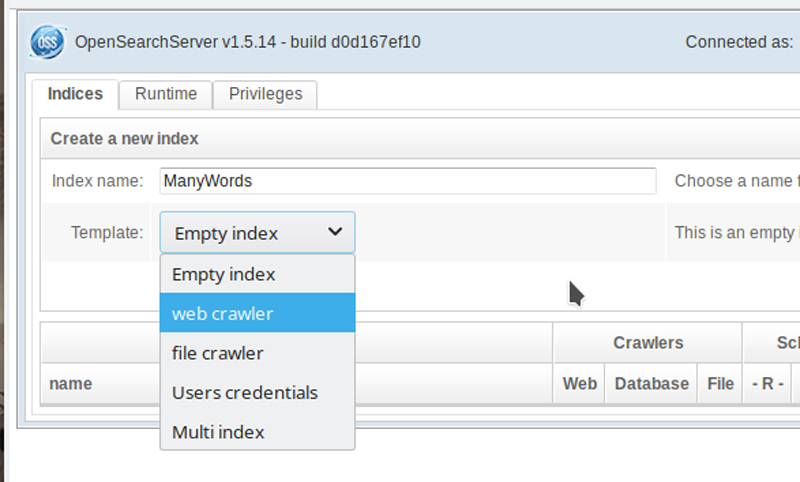
Figure 4. Creating an Index
Directly under the Index name, there's a drop-down from which you can define the type of index you are creating. Select "web crawler" as the type. Click Create, and in a few seconds, you'll have an empty index on which to start building your search database. You also may notice that there are now a number of additional tabs running along the top that were not there before (Figure 5).

Figure 5. Tabs, tabs, tabs—once created, the new index generates many new options.
Go ahead and click the "Crawler" tab. Doing this will once again open up another large group of tabs. It's at this point that you are probably starting to think there's an awful lot to this OpenSearchServer, and you would be right. I'm going to concentrate on just the basics here so you can get your search engine up and running quickly.
Front and center, there's a tab labeled "Pattern list", and this is where you're going to tell the crawler how and where to crawl. Several examples are included as a guide, but the simplest thing to do is tell the system to crawl everything from the domain root on down. You do that by entering http://yourdomain.dom/* where the "*" means "index everything" (Figure 6). Now, click "Add". If you don't want to index the entire site, or you want to index more than one site, specify only the paths you want. Keep adding paths until you've defined everything you want. I should point out that since, in my terribly simple website, my Documents directory isn't linked to any HTML file in my root, I also need to add that to the pattern list.
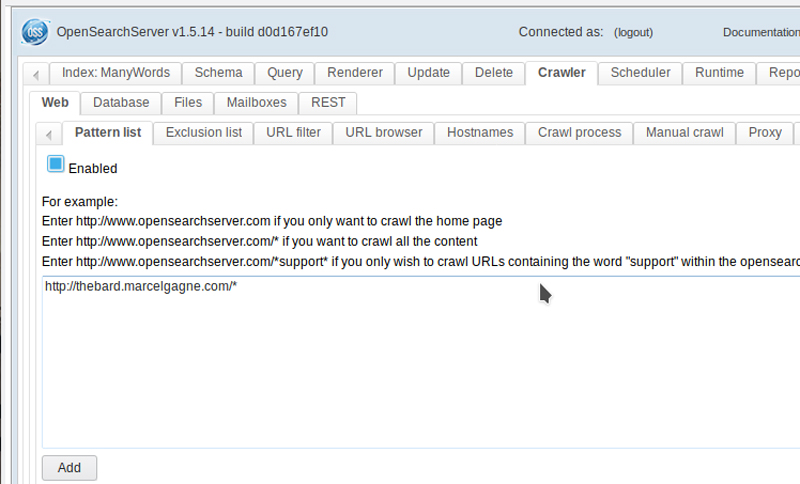
Figure 6. Defining the Search Pattern for the Index
As soon as you do this, you're ready to start the magic. Click the "Crawl process" tab where you'll see a number of parameters that define how the web crawler will do its job. Here you can specify a name for your user agent (what you'll see in server logs), the number of URLs to crawl, the number of simultaneous threads to use, the maximum depth in terms of website subdirectories, how long to wait in between each access to the site, and much more. For now, let's just go with the defaults as shown in Figure 7.
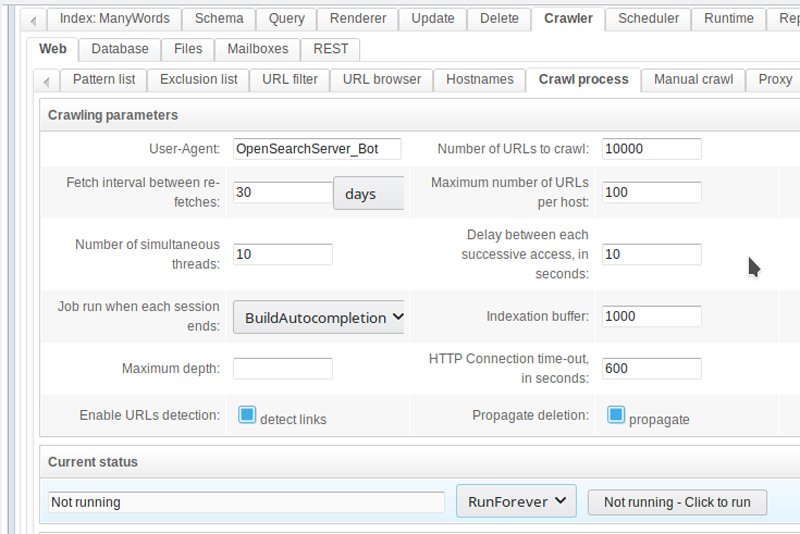
Figure 7. Define the parameters for your Web crawler, then click to run.
Notice the section near the bottom labeled "Current status". If this is your first index, the crawler isn't yet running. Look to the right of that section, and you'll see a drop box with the words, "Run Forever", which is what you want if the content on your site is likely to change. When you're happy with the choices, click the "Click to run" button.
Once crawling starts, it may take some time to run. The OpenSearchServer engine does need to parse every one of the various files it finds as it goes, and the bigger your site, the longer that will take. You can keep an eye on how things are doing by scrolling below the "Current status" section shown in Figure 7 to where the crawler statistics are displayed (Figure 8).
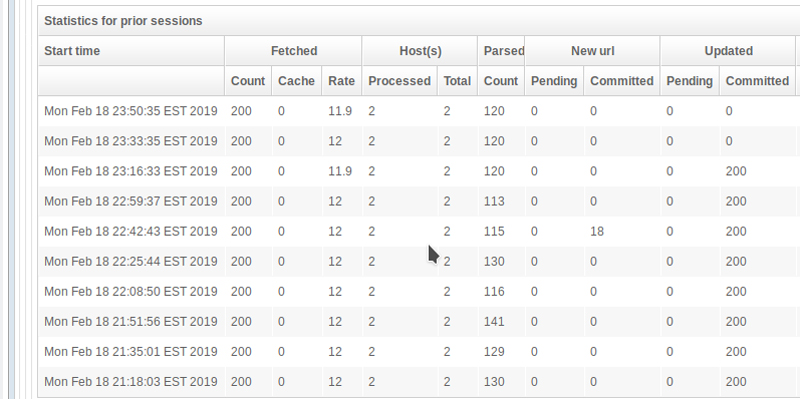
Figure 8. Watching the Progress of Index-Building
Eventually, the crawler will finish its job and you'll want to search your site, and this is where I need to discuss renderers. Click back on the main tab near the top, the one that bears the name of the index you created. (In my case, that's "ManyWords".) This will collapse several tab bars and take you back to the top to the options specific to that index. Click the tab labeled "Renderer". OpenSearchServer helpfully creates a "default" renderer for "search" (Figure 9).

Figure 9. A Default Search Renderer Already Exists
As you'll see shortly, the default renderer is quite plain. It's basically an empty search box with a button labeled "Search" to the right of it. To dress up the search form, you can click the "Edit" button, and I'll give you an example of what you can do there in a moment. For now, click on the View button to bring up the default search form (Figure 10) where you'll ask the engine to search for the word, "words".
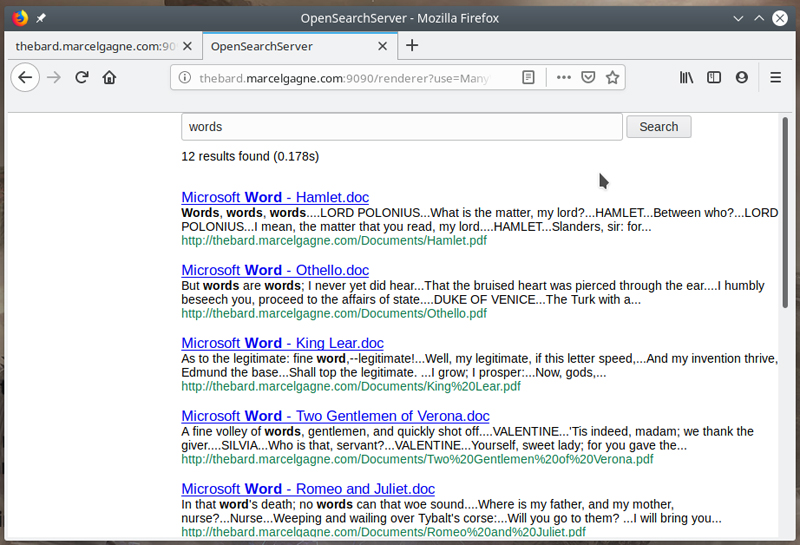
Figure 10. It works! The search engine renders results, but they're plain.
As I write this, my crawler is still doing its job, so I'm getting only a handful of results, but the index will build over time. Let's take that time to dress up the renderer by clicking the Edit button and filling in something for the header and footer (Figure 11).
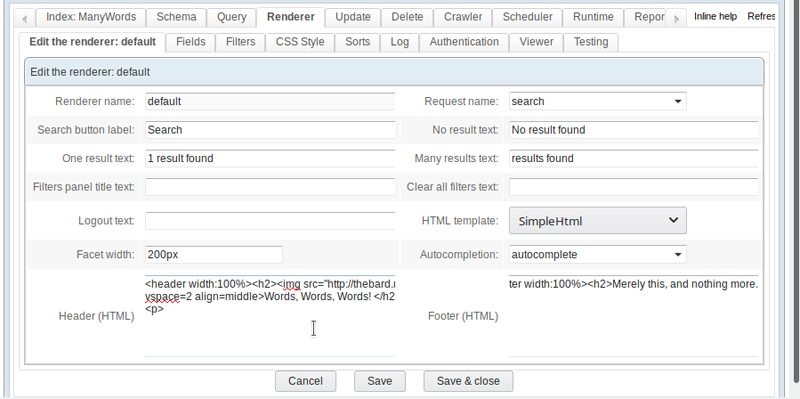
Figure 11. Editing the renderer HTML to create a better-looking search page.
At the bottom, on the main Edit tab, there's a section for "Header HTML" and for "Footer HTML". I won't pretend to be the world's best (or thousandth best) website creator, so forgive my rather simple attempts at dressing up my web search form. Starting with the header, I might do the following:
<header width:100%><h2>%nbsp;</h2></header>
<img src="http://proman-erp.com/sites/default/files/
↪ProMan_logo_150.png" hspace=5 vspace=2>
<p>
The HTML footer, much simpler, looks like this:
<footer width:100%><h2>Merely this, and nothing
↪more.</h2></footer>
That's it. And yes, I know that last line is Poe and not Shakespeare.
What does the search form look like now? Take a look at Figure 12 for the finished product.
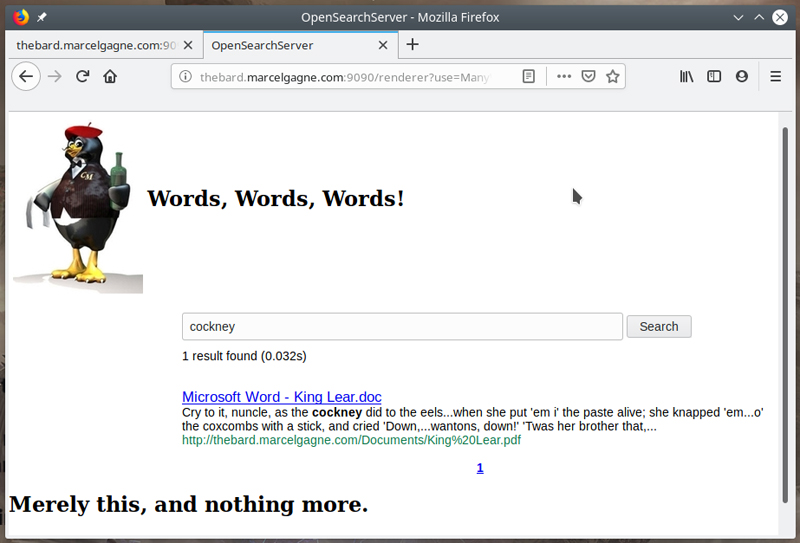
Figure 12. The Finished Search Form
Not bad, if I do say so myself. And, this is where I will leave you. As the Bard, William Shakespeare, might have said, I bid you good night, sweet Princes and Princesses. May flights of penguins sing you to sleep with their sweet songs.
What? Penguins don't fly? This video from the BBC disagrees with you.

Next thing you know, you'll be telling me penguins don't sing and dance either. Until next time!