It's probably fair to say that there's more than one person out there who is worried about some version of artificial intelligence, or AI, possibly in a robot body of some kind, taking people's jobs. Anything that is repetitive or easily described is considered fair game for a robot, so driving a car or working in a factory is fair game.
Until recently, we could tell ourselves that people like yours truly—the writers and those who create things using some form of creativity, were more or less immune to the march of the machines. Then came GPT-2, which stands for Generative Pretrained Transformer 2. I think you'll agree, that isn't the sexiest name imaginable for a civilization-ending text bot. And since it's version 2, I imagine that like Star Trek's M-5 computer, perhaps GPT-1 wasn't entirely successful. That would be the original series episode titled, "The Ultimate Computer", if you want to check it out.
So what does the name "GPT-2" stand for? Well, "generative" means pretty much what it sounds like. The program generates text based on a predictive model, much like your phone suggests the next word as you type. The "pretrained" part is also quite obvious in that the model released by OpenAI has been built and fine-tuned for a specific purpose. The last word, "Transformer", refers to the "transformer architecture", which is a neural network design architecture suited for understanding language. If you want to dig deeper into that last one, I've included a link from a Google AI blog that compares it to other machine learning architecture (see Resources).
On February 14, 2019, Valentine's Day, OpenAI released GPT-2 with a warning:
Our model, called GPT-2 (a successor to GPT), was trained simply to predict the next word in 40GB of Internet text. Due to our concerns about malicious applications of the technology, we are not releasing the trained model. As an experiment in responsible disclosure, we are instead releasing a much smaller model for researchers to experiment with, as well as a technical paper.
I've included a link to the blog in the Resources section at the end of this article. It's worth reading partly because it demonstrates a sample of what this software is capable of using the full model (see Figure 1 for a sample). We already have a problem with human-generated fake news; imagine a tireless machine capable of churning out vast quantities of news and posting it all over the internet, and you start to get a feel for the dangers. For that reason, OpenAI released a much smaller model to demonstrate its capabilities and to engage researchers and developers.

Figure 1. Part of the Sample Provided in the OpenAI Blog
If you want to try this "too dangerous to release" AI for yourself, you can. Here's what you need to do. OpenAI has a GitHub page for the GPT-2 code from which you can either download via a git clone or simply pick up the latest bundle as a ZIP file:
$ git clone https://github.com/openai/gpt-2.git
Cloning into 'gpt-2'...
remote: Enumerating objects: 174, done.
remote: Total 174 (delta 0), reused 0 (delta 0), pack-reused 174
Receiving objects: 100% (174/174), 4.35 MiB | 1.72 MiB/s, done.
Resolving deltas: 100% (89/89), done.
This will create a folder called "gpt-2" from which everything else will flow. Before you can jump in and make this all work, you're likely going to need to install a few prerequisites. The biggest of these is a Python 3 environment, pip and tqdm. If you are lucky enough to have an NVIDIA GPU on-board, you'll also want to install CUDA; it's not required, but it does make things go a lot faster. On my Ubuntu system, I installed the packages like this:
sudo apt install python3-pip python3-tqdm python3-cuda
Before I continue, here's a treat. When the code was first released, it included a 117M (million) parameter model to limit the potential danger of releasing a better version into the wild. Apparently, some of those fears have been put to rest, because as of May 4, 2019, there is now a 345M parameter model. The largest model in the code base, if and when it is released, is (or will be) 1542M parameters.
You will need that 345M model on your computer, so let's download it now:
python3 download_model.py 345M
How long this step takes will depend a bit on your connection speed since you are downloading a lot of data, so this might be a good time to get yourself a snack, or a drink. As it downloads, you'll get a visual update on the various parts of the model (Figure 2).
Figure 2. Downloading the GPT-2 Language Model
Yes, there are more prerequisites to install. Luckily, you can install a number of them via a file in the gpt-2 source called requirements.txt:
pip3 install -r requirements.txt
There are only four packages, so you also can just do this:
pip3 install fire regex requests tqdm
The next step is to install tensorflow, of which there are two versions. GPT-2 will run on any system where the requirements are met, but if you happen to be lucky enough to have that NVIDIA GPU with the appropriate driver, it will all run much faster. To install the GPU version of the tensorflow code, do the following:
pip3 install tensorflow-gpu==1.12.0
To install the non-GPU version, the command looks like this:
pip3 install tensorflow-gpu==1.12.0
Once again, this is a big package, so it might take a few minutes. Once done,
several other packages, all of which make up tensorflow, also will have been
installed. By this point, a number of commands will have been installed in
your $HOME directory under .local/bin. Save yourself some pain and include
that in your .bash_profile's $PATH. If you're in a hurry, and you don't want
to log out and back in right now, you can always update your
$PATH on the
fly:
export PATH=$PATH:/home/mgagne/.local/bin
Perfect! Now you're ready to generate a textual masterpiece. In the src directory, you'll see two scripts to generate text:
src/generate_unconditional_samples.py
src/interactive_conditional_samples.py
Let's start with the unconditional script.
python3 src/generate_unconditional_samples.py --top_k 40
↪--model-name 345M
If you are running this entirely from the CPU, it may take a few seconds to
start generating text, so be patient. Before I show you a sample of what I
managed to generate on my first pass, I want you to look at a couple command-line
options. One of them is fairly obvious, and that's
the --model-name option, which selects the model should you have more than
one installed. Remember that there are now two available; one is 117M
parameters, and the other is 345M. The second option I want you to look at is
top_k, which represents the percentage of logits used in selecting
words. A lower value will tend to create text using simpler words, but it also
tends to be more repetitive. A higher top_k tends to generate more realistic
text.
To make things more interesting, you'll want to give the AI writer a place to start by providing it an opening line, and that means you'll want to use the interactive script:
python3 src/interactive_conditional_samples.py --top_k 40
↪--model-name 345M
When you run this, it will take a few seconds (or more if you are using the
CPU version of tensorflow), at which point it will give you a Model prompt
>>> prompt. This is where you type in your line of text. When you press
Enter, the magic begins. Again, be patient. I decided to give it a simple
one-line prompt of "Once upon a time, there was a beautiful princess."
Everyone likes a fairy tale, right?
With a top_k of 10, the AI writer produced the following (I'm including
only the first two paragraphs):
The princess was a princess of the land of the moon. The moon was her favorite. She was born a princess, but she was not a princess in her own right. She was called a princess by the people of the moon, but they didn't know what it meant or what it meant to be a princess.
The princess had the same name as her father.
Let's try dropping that top_k to 1 using the same prompt. I'll show you the
first five paragraphs because they're so short:
She had a beautiful face, a beautiful smile.
Her eyes, her hair, her body were all beautiful.
Her hair was long and beautiful.
Her eyes, her hair, her body, her body was all beautiful.
Her hair was long and beautiful.
Ouch! I think the books my kids read when they were five years old had more
depth. Okay, one last pass before visiting some of the other command-line
options you can use. I've gone back to the default of a top_k of
40:
At the age of seven, she learned to read and write, became a famous author, gave birth to a handsome prince (in other words, she was just about to enter the Royal Family). At age twenty she reached puberty. At seventeen she gave birth to a prince of the same class as her own. At twenty-four she had already entered her second period, and was then named Countess. What happened to her?
That's when I realized that I was living a story, that was told on both sides of every age-related phenomenon. There's always a second gender, a third gender, a fourth gender. And when someone falls into any of those different, the gender they are inside of can change in accordance with their situation. As it turns out, the "male" aspect in life may actually be the opposite of the "female" aspect of reality.
So, fiction writers are probably okay for a little while, or at least until OpenAI releases the full model, but it does give you an interesting example of where this is all going.
Some of other command-line options hidden in the code include the following:
--nsamples
--length
--temperature
I've been experimenting with these to see how they affect results.
Temperature is interesting in that it affects the "creativity" of the program
in that it decreases the likelihood that the AI writer will take the safe
road. If you want more than one sample generated each time, set the
--nsamples number. The --length option is measured in words. So, let's
say I want two samples of 150 words each, I might issue the following
command (note that the whole command is actually one line):
python3 src/interactive_conditional_samples.py --top_k 40
↪--temperature 5 --length 150 --nsamples 2
↪--model-name 345M
As a starting point, I used the first line of Tolkien's The Hobbit: "In a hole in the ground there lived a hobbit." Figure 3 shows the results. Let's just say that Tolkien, if he were still alive, would be safe as a novelist—for now.
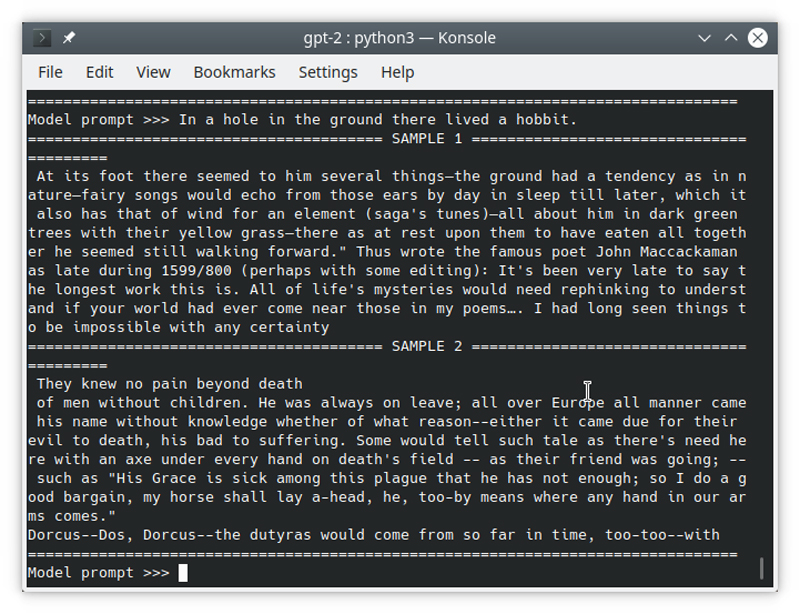
Figure 3. Tolkien is safe—for now.
For a more complete list of command-line options to GPT-2, use the following command
(pay attention to the two hyphens before the --help):
python3 src/interactive_conditional_samples.py -- --help
I've been making fun of the output, but there's something amazing happening here that can't be completely ignored. The model I'm forced to work with is better than the original that was released, but it's nowhere near what OpenAI still has sitting out there. This also is still in development, so it has a way to go. In addition, as I mentioned in the opening, there is a dark side to this that can't be ignored, beyond even the potential career-ending aspect that writers like myself may be facing, and that's the spectre of just what these tireless AI writers may be releasing into the world.
One sample I did not include in this article made me cringe with horror. I submitted the first line of Jane Austen's Pride and Prejudice: "It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife."
The result was hateful, misogynistic, homophobic and included made-up but plausible quotes from the Bible. This is fascinating technology and well worth your time and exploration. The more we all understand these forays into machine learning and artificial intelligence, the better prepared we will be when Jane Austen turns into Alex Jones.