Machine Learning (ML) is driving the exploration of vast volumes of data. With the right training data, ML can outperform many traditional forms of automation and analysis in diverse industries and applications. A critical advantage of this approach is that ML can cut through human biases and protocols established over decades in some cases. ML even can be used on Linux kernel-level data streams to optimize networked activities—and to enable the system to "understand" its environment. Here, we use ML on data that is constantly generated by the Linux networking stack to provide an additional, rudimentary form of "intelligence" about networked systems that are nearby. We approach this problem by allowing ML algorithms to work on the byproducts of the Stream Control Transmission Protocol (SCTP).
SCTP is a relatively new transport protocol for IP networks. Defined originally in RFC 4960, it provides many reliability benefits, such as multi-homing, multi-streaming and path selection, which are useful in control-plane or signaling applications. SCTP is used in place of conventional transport protocols (such as TCP and UDP) in telecommunications, Smart Grid, Internet-of-Things (IoT) and Smart Cities applications, among others. We chose to use SCTP for this ML experiment because it has many useful applications and characteristics. However, the use of ML approaches in different types of kernel-level data streams also may be useful for classifying congestion patterns, forecasting data movement and providing new application-specific "intelligence".
But, before going further in the use of ML techniques inside the Linux kernel, we should discuss some background concepts. The most popular form of ML is Deep Learning (DL) Neural Network (NN) algorithms. An NN model consists of an input neural layer, hidden layers and output layer. Figure 1 shows these layers as orange, blue and black nodes, respectively. The number of inputs depends on the number of parameters that are considered to develop the model. The hidden neural layers can be configured in many forms to perform different statistical analysis using weight factors and activation functions. The number of outputs in the last neural layer provides the weighted outcomes of the model.
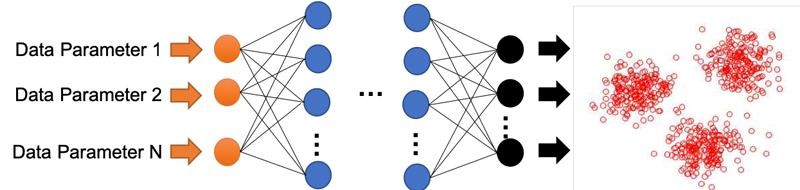
Figure 1. Deep learning neural network: orange nodes are the input layer, blue nodes are hidden layers, and black nodes are the output layer. The red circles on the far right are outputs that have been "clustered" by the network.
NN models are trained using approaches known as supervised, unsupervised and reinforcement learning, which are described briefly in the following sections.
Supervised training uses data with labels that tell the network which outputs should be produced by specific input parameters. The training process reconfigures weighting values within the hidden and output layers to ensure these outcomes. The more data presented to the network during training, the more accurate outcomes appear when inputs are not in the training data.
The trained NN model is then validated using input data that is similar to the training data but without labels or desired outputs. Validation outputs should be similar to training outputs. The training-validation cycle helps a designer understand the percentage of accuracy the network has reached after being trained. If the accuracy is too low for the design, further training is required, and different NN design parameters are tuned. The training and validation phases must be tuned iteratively until the desired or required accuracy appears.
The final step is the test phase of the NN model. At this point, the model is fed input data not presented during training or validation phases. The data set used in the test phase is often a small subset of the overall data set used for the NN model design. The test phase results are known as the real values of accuracy.
Unsupervised training uses training data that is not labeled. The network "learns" autonomously by adjusting its weights based on patterns detected in the input data. Unsupervised designs typically analyze input data that is unknown or unstructured from the designer's perspective. As a result, this approach takes longer for the NN model to be trained and requires more data if high accuracy is required.
Reinforcement learning is becoming the most robust ML training approach to manage complex problems in many industries and research fields. This approach trains the model through a reward system. Random scenarios circulate to the input, and a reward is fed to the model when reaching the desired outcome. This approach requires much computational time to train the NN model due to the learning curve. However, reinforced models have reached a high competency for solving problems and out-performing human experts in many applications. One of the most effective reinforcement learning examples was mastered by Google's AlphaGo team to win the ancient game Go. The NN model was able to beat the best Go players in the world.
To incorporate ML techniques into Linux networking processes, we use Round-Trip Times (RTT) and Retransmission Timeouts (RTO) values as input values for a layered NN model trained via unsupervised and supervised learning. In this approach, RTT/RTO values from a network interaction based on SCTP are collected, then used to train the NN model. Using this data, the trained model produces outcomes that create new insights (or "inferences") into the networking context of the system. The objective is to see if the ML system can differentiate between various known network scenarios, or if the ML system can produce new information about network activities. In our results, the RTT and RTO values already exist inside the Linux kernel, and the insights/outcomes that result from the ML process are unique and useful.
The approach developed to integrate an NN model to devices is known as an inference model. An inference model is an optimized NN model code engine that can run on a computer device. A useful inference model generator comes from NVIDIA's TensorRT Programmable Inference Accelerator application. This way, inference models through TensorRT then can be imported to the Linux kernel for networking modules, scheduling of processes, priority calculations or other kernel functionalities that can provide a smarter execution flow for application-specific implementations.
The goal here is to obtain a smarter network flow using the SCTP protocol and an ML-based evaluation of related kernel-level data. The results of our experiments clearly show that it's possible to optimize network activities by using an inference model to digest the current state and select the right processing or subsequent state. Figure 2 shows the inference model implementation situated between reading metrics from the SCTP module in the Linux kernel and the selection of outcomes. The inference model reads input parameters from the current state of network activities, then processes the data to determine an outcome that better "understands" the state of the network. Given that the implementation may be application-specific, the inference model also may be trained to have different outcomes biased to the application.
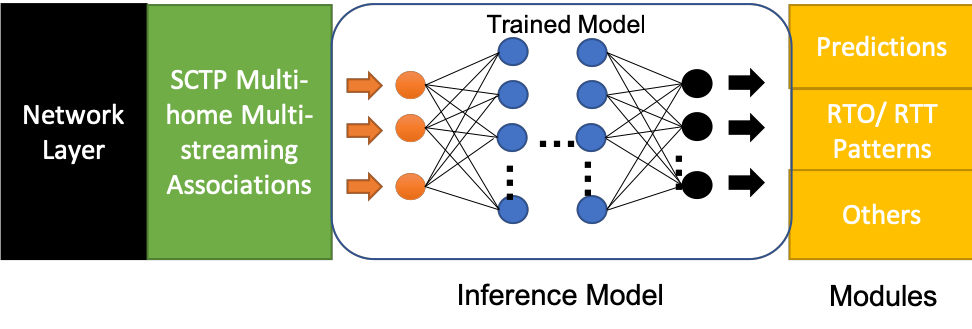
Figure 2. Inference model implementation: RTT/RTO values from SCTP are fed to an inference model to produce smarter congestion handling.
We created four different scenarios to test several ML implementations in the Linux kernel. These scenarios are detailed below, and they represent a wireless device moving away from or toward a wireless access point with a few variations, including the access point being in signal over-saturation. In our experiments, 2,500 samples were recorded for each scenario and left unlabeled. Each data set collected was normalized against its maximum value. By normalizing the data, patterns become more pronounced, which improves the ML analysis. Here are the scenarios:
Congestion due to other devices is a common phenomenon in a wireless network. To model this issue, we included a collection of cross traffic in the network to evoke congestion. Figure 3 shows the system designations, where A/B systems provided cross traffic and are connected via wired Ethernet, and Host/Client systems provided test data and are connected via wireless. In this scenario, 5,000 15-second samples were collected from the Client node as it sent SCTP-Test packets to the Host node, while A-to-B traffic consisted of 1MB, 512KB, 256KB, 128KB and 1KB chunk size FTP traffic.
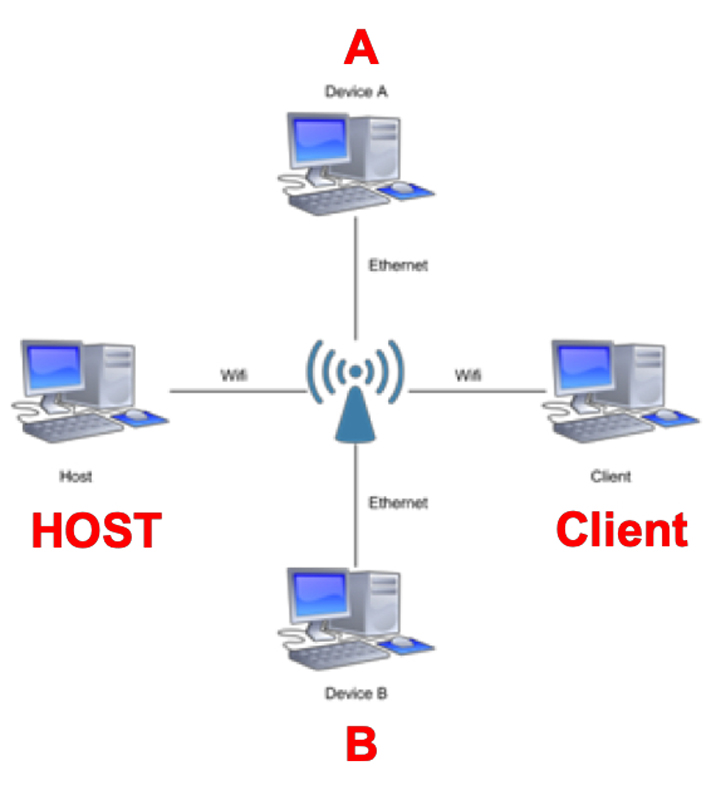
Figure 3. Congestion Experiment Setup
To create additional cross-traffic variation, we also used the VLC media player to stream a file over UDP from A-to-B. In this scenario, we collected 5,000 15-second samples from the Client device as it sent SCTP-Test packets to the Host device. Since the bitrate of the UDP stream changed continuously due to compression algorithms, further adjustments in chunk sizes were unnecessary.
To classify the data obtained from our network scenarios, we used four ML classification algorithms that were trained using unsupervised or supervised learning techniques. These ML techniques are briefly described below.
K-Means Clustering:
Support Vector Machine (SVM):
Decision Trees (DT):
Nearest Neighbor Classifier (NCC):
As an example of the outcomes of our testing, Figure 4 shows the results of classifying the normalized network data using K-Means clustering. Note from Figure 4 that four differentiated outcomes are clearly present: 1) systems "moving toward" or 2) "moving away" from each other, as well as systems experiencing 3) "signal saturation" and (4) "network congestion". Note that regardless of the test scenario, the ML algorithm can discern valuable information about the networked systems. Although additional analysis can produce more information, these outcomes may be quite useful in certain applications.
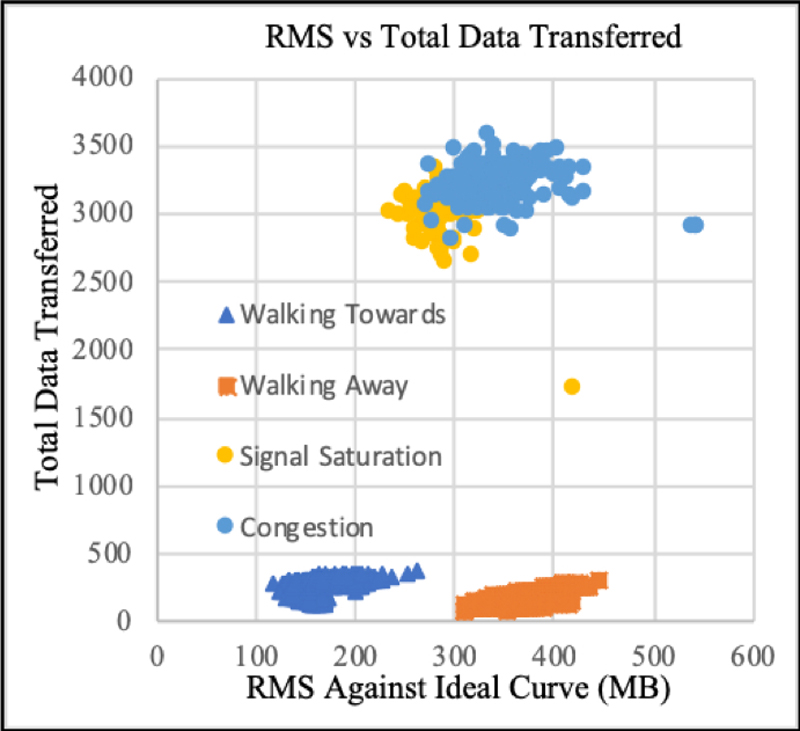
Figure 4. ML classification outcomes of Linux kernel network data using the K-Means algorithm. The classified data clearly indicates four different outcomes for external networked systems.
The ideal outcome or classification for the different network testing scenarios is a clear separation between the four groups, as shown in Figure 4. Two of the cases are clearly and individually separated from the group. However, in the cases of congestion and signal over-saturation, the classification overlaps without a clear separation. This lowers the accuracy of the ML model. To improve the classification, we would need to include another parameter in the analysis that helps to discriminate between congestion and saturation.
In all cases, the ML techniques analyzed data that is consistently produced internal to the Linux kernel to gain new insights about the external network context. However, since these algorithms are operating on kernel-level data, the issue of efficiency is also important.
Figure 5 summarizes the accuracy and efficiency of classifying the network data using ML algorithms. From Figure 5, it's clear that the SVM approach is most efficient: it achieves the highest accuracy using the least number of training samples. This means that the SVM classifier can quickly distinguish differences in the kernel data and can produce useful outcomes efficiently. It is also an excellent practice to realize a large number of examples to see the convergence of accuracy for each classifier. However, NN models that reach 100% accuracy may produce large failure rates due to overfitting.
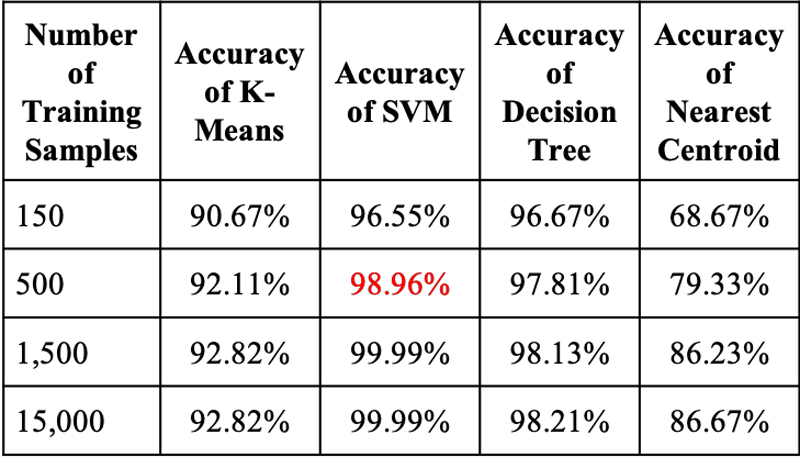
Figure 5. Accuracy and speed of classification algorithms when using normalized data from different networking scenarios.
Accurate and fast classification of network data using ML techniques may result in Linux systems that can autonomously react based on external network conditions. These reactions may include modifying kernel data, selecting alternate retransmission or transport protocols, or adjusting other internal parameters based on external context. This form of "inference" is a fundamental problem in systems communicating via a network. In our experiments, network data was collected directly from the existing kernel processes and used to train the four ML classifiers to produce interesting and useful inferences.
Our results suggest that the SVM approach may be a promising ML technique for inferring results from kernel networking data. The SVM approach reduces the number of nodes per layer, adjusts precision of the data without losing accuracy and reduces the latency of computation. The output of the inference layer provides the networking stack with additional information to handle different scenarios. The inference development represents a form of customizing network communication between endpoints for a variety of applications. Other network conditions may benefit from inference models that utilize different data produced by the networking stack.
As ML techniques are included in new designs and applications, they have become a valuable tool and part of the implementation process for smarter networks. Concepts related to "machine learning" and "artificial intelligence" even may be implemented inside the Linux kernel to improve networking performance.