Kubernetes has taken the world by storm. In just a few years, Kubernetes (aka k8s) has gone from an interesting project to a driver for technology and innovation. One of the easiest ways to illustrate this point is the difference in attendance in the two times KubeCon North America has been in Seattle. Two years ago, it was in a hotel with less than 20 vendor booths. This year, it was at the Seattle Convention Center with 8,000 attendees and more than 100 vendors!
Just as with any other complex system, k8s has its own security model and needs to interact with both users and other systems. In this article, I walk through the various authentication options and provide examples and implementation advice as to how you should manage access to your cluster.
The first thing to ask is "what is an identity?" in k8s. K8s is very different from most other systems and applications. It's a set of APIs. There's no "web interface" (I discuss the dashboard later in this article). There's no point to "log in". There is no "session" or "timeout". Every API request is unique and distinct, and it must contain everything k8s needs to authenticate and authorize the request.
That said, the main thing to remember about users in k8s is that they don't exist in any persistent state. You don't connect k8s to an LDAP directory or Active Directory. Every request must ASSERT an identity to k8s in one of multiple possible methods. I capitalize ASSERT because it will become important later. The key is to remember that k8s doesn't authenticate users; it validates assertions.
Service Accounts
Service accounts are where this rule bends a bit. It's true that k8s doesn't store information about users. It does store service accounts, which are not meant to represent people. They're meant to represent anything that isn't a person. Everything that interacts with something else in k8s runs as a service account. As an example, if you were to submit a very basic pod:
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh', '-c', 'echo Hello Kubernetes!
↪&& sleep 3600']
And then look at it in k8s after deployment by running kubectl get pod
myapp-pod -o yaml:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: 2018-12-25T19:17:53Z
labels:
app: myapp
name: myapp-pod
namespace: default
resourceVersion: "12499217"
selfLink: /api/v1/namespaces/default/pods/myapp-pod
uid: c6dd5181-0879-11e9-a289-525400616039
spec:
containers:
- command:
- sh
- -c
- echo Hello Kubernetes! && sleep 3600
image: busybox
imagePullPolicy: Always
name: myapp-container
.
.
.
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: default-token-bjzd4
readOnly: true
.
.
.
serviceAccount: default
serviceAccountName: default
.
.
.
You'll notice that there's a serviceAccount and
serviceAccountName attribute,
both of which are default. This service account is injected for
you by the admission controller chain. You can set your own service
account on pods, but that's for a later article on authorization in k8s.
For now, I want to cover what a service account is to distinguish it
from a user account.
It's tempting to use service accounts to represent people. They're simple to create and easy to use. They suffer from multiple drawbacks, however:
If your application runs in a pod and needs to talk to the API server, you can retrieve the pod's service account via a secret that is mounted to your pod. If you look at the above yaml, you'll see a volume mount was added to /var/run/secrets/kubernetes.io/serviceaccount where there's a token file that contains the pod's service account token. Do not embed service account tokens as secrets or configuration for a pod running in the cluster, as it makes it more difficult to use rotating tokens and generally is harder to manage.
User Accounts
I mentioned before that k8s doesn't connect to any kind of user store (not directly at least). This means that on each request, you must provide enough information for k8s to validate the caller. K8s doesn't care how you establish the identity, it cares only how it can prove the identity is valid. Multiple mechanisms exist for doing this; I cover the most popular here.
OpenID Connect
This is the option you should be using (with the exception of a cloud provider-based solution for a managed distribution) to authenticate users.
Before diving into how to work with OpenID Connect, let me explain the protocol. There are two core concepts to understand with OpenID Connect:
There's a word in those two points that seems to be missing: authentication! That's because OpenID Connect is not an authentication protocol. It doesn't care how you authenticate. It doesn't matter if the user logged in with a user name and password, a smart card or just looked really trustworthy. OpenID Connect is a protocol for generating, retrieving and refreshing assertions about a user. There are also some standards about what the assertion looks like, but how the user authenticates is ultimately up to the OpenID Connect implementation.
The second point about OAuth2 is important because these two protocols often are confused with one another or misrepresented. OAuth2 is a protocol for transferring tokens. It doesn't define what the token is or how it should be used. It simply defines how the token is passed between bearers and relying parties.
Figure 1 shows the graphic from the k8s' authentication page.
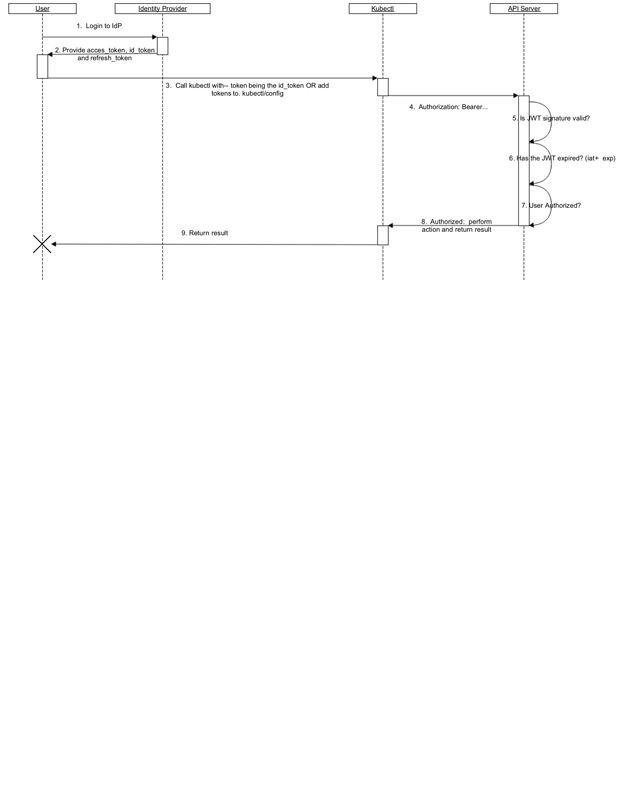
Figure 1. k8s OpenID Connect Flow
I won't repeat the exact words from the site, but here's the basics:
id_token and a
refresh_token.id_token is used to assert the user's identity to k8s.id_token has expired, the refresh_token is used to
generate a new id_token.
An id_token is a JSON Web Token (JWT) that says:
The user's id attribute, sub, is typically the user's unique identifier.
It's common to use Active Directory's login ID (aka samAccountName), or
many implementers prefer to use an email address. In general, this isn't
the best practice. A user's ID should be both unique and immutable.
Although an email address is unique, it isn't always immutable (for instance, sometimes
names
change).
The JWT is passed on every request from kubectl to k8s. The
id_token
is referred to as a "Bearer Token", because it grants the bearer access
without any additional checks. This means if a system in the
flow of an API call—such as a service mesh proxy, validating webhook
or mutating webhook—were to leak this token, it could be abused by an
attacker. Because these tokens are so easily abused, they should have
very short life spans. I recommend one minute. That way, if a token
is exfiltrated by the time someone sees it, knows what it is and is
able to use it, the token has expired and so is useless. When using
such short-lived tokens, it's important to configure a
refresh_token
to update your id_token after it expires.
kubectl knows how to refresh the id_token token by using the
refresh_token to call the identity provider's authorization service URL.
The refresh_token is a token that the k8s' API server never uses and
should be treated as a secret by the user. This token is used to get a
new JWT, at which point a new refresh_token is available. Where the
id_token should have a very short life time, the
refresh_token
timeout should be similar to an inactivity timeout, usually 15–20
minutes. That way, your k8s implementation will comply with
policies in your enterprise focused on inactivity timeouts. Using a
refresh_token to get a new id_token is more secure
than a longer-lived
id_token because the refresh_token means the
following:
The Kubernetes Dashboard
The dashboard doesn't have its own login system. All it can do it use an
existing token acting on the user's behalf. This often means putting a
reverse proxy in front of the dashboard that will inject the
id_tokenL
on each request. The reverse proxy is then responsible for refreshing
the token as needed.
When choosing an identity provider, k8s really has only two requirements:
That's pretty much it! The discovery is important, because it keeps you from having to tell k8s where different URLs are manually, what keys are used for signing and so on. It's much easier to point k8s to a discovery URL that has all that information. This is a common standard, and most identity providers support it out of the box.
Point #2 is where things get interesting. There are different schools of thought as to how to get your token information from your login point (usually a web browser) into your ~/.kube/config.
Web Browser Injection
In this model, everything is focused on your web browser. You
authenticate via your browser and then are provided commands to
set up your kubectl client properly. As an example, OpenUnison (our own project)
provides you with a single command to set your cluster configuration
once authenticated (Figure 2).

Figure 2. Browser Token
You use kubectl's built-in ability to configure the config file from
the command line to complete the setup.
This method has several advantages:
kubectl commands, so there's nothing more to deploy to
workstations.
The kubectl Plugin
You can extend the kubectl command using plugins.
Using a plugin, you can collect a user's credentials and then generate
a token. I've seen plugins that will collect your credentials from
the CLI, and other plugins that will launch a browser to prompt you for
a login. This method is good from a CLI perspective as it lets your CLI
drive your user experience. The major drawback to this approach is it
requires installing the plugin on each workstation.
Download Config
With this method, the identity provider (or a custom-built application) provides you with a fully generated configuration file you can download. This can create a support issue if something isn't saved to the right place.
Once you've chosen an identity provider, follow its instructions for integration. The key items of importance are the discovery URL, the identifier "claim" and the group's "claim".
X509 Certificates
Certificate authentication leverages the TLS handshake between the
client (generally the kubectl command) and the the k8s API server
to assert an identity by presenting a certificate to the API server.
With the exception of one use case, this method is not a "best practice"
and should be discouraged for several reasons:
The only situation where you should use X509 certificates for
authentication is when you are bootstrapping your cluster or in case of
emergency and your identity provider isn't available. Most distributions
deploy a keypair to each master, so if you ssh into that master, you can
use kubectl to manage the cluster. This means that you need to lockdown
access to the master (I plan to cover this in a future article).
Webhooks
This method lets you integrate a third-party login or token system via a webhook. Instead of telling k8s how to validate an identity, k8s calls a webhook and asks "who is this?"
Don't do this unless you are a cloud provider and have your own identity solution. Just about every implementation I've seen of this turns into "let's pass passwords" or a poorly thought out OpenID Connect.
Reverse Proxy with Impersonation
Here the client (kubectl or otherwise) doesn't communicate with the API server directly. It instead communicates with a reverse proxy, which then injects headers into the request to represent the user. This is often pointed to as a way to handle advanced authentication scenarios, since it requires the least amount of work from the API server's perspective. The steps for implementation are:
This solution provides these issue plus the same pitfalls as Webhooks. Chances are existing standards will suit your needs and be easier to manage and maintain.
To integrate identity into k8s, follow this basic checklist:
Follow these rules, and you'll find that your developers are happy to have one less password to remember, and your security team will be happy you're following best practices and compliance requirements.