Kubernetes (aka K8s) is now the de facto container orchestration framework. Like other popular open-source technologies, Kubernetes has amassed a considerable ecosystem of complementary tools to address everything from storage to security. And although it was first created for running stateless applications, more and more organizations are interested in using Kubernetes for stateful applications.
However, while Kubernetes has advanced significantly in many areas during the past couple years, there still are considerable gaps when it comes to running complex stateful applications. It remains challenging to deploy and manage distributed stateful applications consisting of a multitude of co-operating services (such as for use cases with large-scale analytics and machine learning) with Kubernetes.
I've been focused on this space for the past several years as a co-founder of BlueData. During that time, I've worked with many teams at Global 2000 enterprises in several industries to deploy distributed stateful services successfully, such as Hadoop, Spark, Kafka, Cassandra, TensorFlow and other analytics, data science, machine learning (ML) and deep learning (DL) tools in containerized environments.
In that time, I've learned what it takes to deploy complex stateful applications like these with containers while ensuring enterprise-grade security, reliability and performance. Together with my colleagues at BlueData, we've broken new ground in using Docker containers for big data analytics, data science and ML/DL in highly distributed environments. We've developed new innovations to address requirements in areas like storage, security, networking, performance and lifecycle management.
Now we want to bring those innovations to the Open Source community—to ensure that these stateful services are supported in the Kubernetes ecosystem. BlueData's engineering team has been busy working with Kubernetes, developing prototypes with Kubernetes in our labs and collaborating with multiple enterprise organizations to evaluate the opportunities (and challenges) in using Kubernetes for complex stateful applications.
To that end, we recently introduced a new Kubernetes open-source initiative: BlueK8s. The BlueK8s initiative will be composed of several open-source projects that each will bring enterprise-level capabilities for stateful applications to Kubernetes.
Kubernetes Director (or KubeDirector for short) is the first open-source project in this initiative. KubeDirector is a custom controller designed to simplify and streamline the packaging, deployment and management of complex distributed stateful applications for big data analytics and AI/ML/DL use cases.
Of course, other existing open-source projects address various requirements for both stateful and stateless applications. The Kubernetes Operator framework, for instance, manages the lifecycle of a particular application, providing a useful resource for building and deploying application-specific Operators. This is achieved through the creation of a simple finite state machine, commonly known as a reconciliation loop:
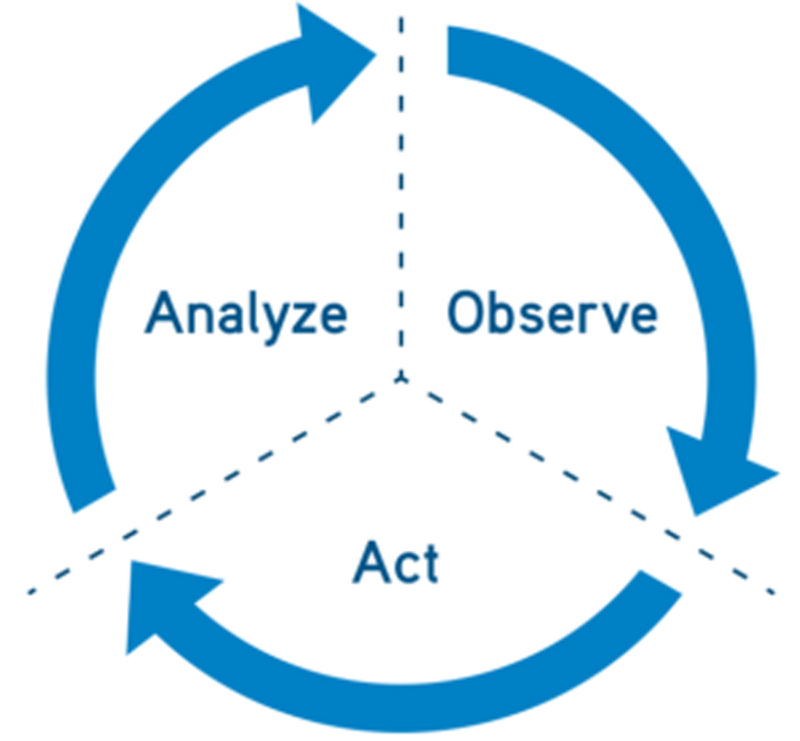
Figure 1. Reconciliation Loop
It's pretty straightforward to use a Kubernetes Operator to manage a cloud native stateless application, but that's not the case for all applications. Most applications for big data analytics, data science and AI/ML/DL are not implemented in a cloud native architecture. And, these applications often are stateful. In addition, a distributed data pipeline generally consists of a variety of different services that all have different characteristics and configuration requirements.
As a result, you can't easily decompose these applications into self-sufficient and containerizable microservices. And, these applications are often a mishmash of tightly integrated processes with complex interdependencies, whose state is distributed across multiple configuration files. So it'd be challenging to create, deploy and integrate an application-specific Operator for each possible configuration.
The KubeDirector project is aimed at solving this very problem. Built upon the Kubernetes custom resource definition (CRD) framework, KubeDirector does the following:
KubeDirector makes it unnecessary to create and implement multiple Kubernetes Operators in order to manage a cluster composed of multiple complex stateful applications. You simply can use KubeDirector to manage the entire cluster. All communication with KubeDirector is performed via kubectl commands. The anticipated state of a cluster is submitted as a request to the API server and stored in the Kubernetes etcd database. KubeDirector will apply the necessary application-specific workflows to change the current state of the cluster into the expected state of the cluster. Different workflows can be specified for each application type, as illustrated in Figure 2, which shows a simple example (using KubeDirector to deploy and manage containerized Hadoop and Spark application clusters).
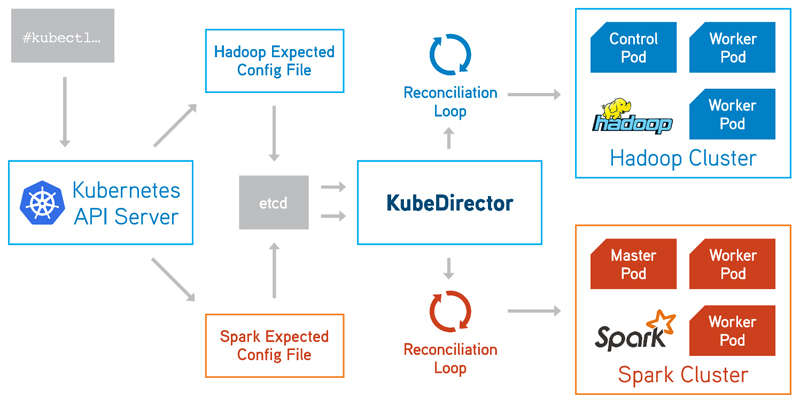
Figure 2. Using KubeDirector to Deploy and Manage Containerized Hadoop and Spark Application Clusters
If you're interested, we'd love for you to join the growing community of KubeDirector developers, contributors and adopters. The initial pre-alpha version of KubeDirector was recently released at https://github.com/bluek8s/kubedirector. For an architecture overview, refer to the GitHub project wiki. You can also read more about how it works in this technical blog post on the Kubernetes site.
—Tom Phelan, co-founder and chief architect, BlueData