For those fortunate enough to not be stuck in the weeds of Amazon Web Services (AWS), CloudWatch is, and I quote from the official AWS description, "a monitoring and management service built for developers, system operators, site reliability engineers (SRE), and IT managers." This is all well and good, except for the part where there isn't a single named constituency who enjoys working with the product. Allow me to dispense some monitoring heresy.
Better, let me describe this in the context of the 14 Amazon Leadership Principles that reportedly guide every decision Amazon makes. When you take a hard look at CloudWatch's complete failure across all 14 Leadership Principles, you wonder how this product ever made it out the door in its current state.
I'll start with billing. Normally left for the tail end of articles like this, the CloudWatch billing paradigm is so terrible, I'm leading with it instead. You get billed per metric, per month. You get billed per thousand metrics you request to view via the API. You get billed per dashboard per month. You get billed per alarm per month. You get charged for logs based upon data volume ingested, data volume stored and "vended logs" that get published natively by AWS services on behalf of the customer. And, you get billed per custom event. All of this can be summed up best as "nobody on the planet understands how your CloudWatch metrics and logs get billed", and it leads to scenarios where monitoring vendors can inadvertently cost you thousands of dollars by polling CloudWatch too frequently. When the AWS charges are larger than what you're paying your monitoring vendor, it's not a wonderful feeling.
CloudWatch Logs, CloudWatch Events, Custom Metrics, Vended Logs and Custom Dashboards all mean different things internally to CloudWatch from what you'd expect, compared to metrics solutions that actually make some fathomable level of sense. There are, thus, multiple services that do very different things, all operating under the "CloudWatch" moniker. For example, it's not particularly intuitive to most people that scheduling a Lambda function to invoke once an hour requires a custom CloudWatch Event. It feels overly complicated, incredibly confusing, and very quickly, you find yourself in a situation where you're having to build complex relationships to monitor things that are themselves far simpler.
All business people, when asked what they want from a monitoring platform, will respond with something that resembles "a dashboard" or "a single pane of glass view". CloudWatch offers minutia up the wazoo, but it categorically offers no global view, no green/yellow/red status indicator that gives you even a glimmer of the overall health of your site. Want a graph of each core in your instance's CPU for the past 30 seconds? Easy! Want to know if your entire company should be putting out the burning fire that is the current production state of your website? Keep looking—CloudWatch has nothing to offer you.
By its very nature, CloudWatch feels like small thinking. The entire experience, start to finish, smacks of "what's the absolute least we could do and get away with it?" They built their MVP, and then just sorta...stopped, frozen in amber. They created a set of building blocks, except they didn't solve the problem of "how do I monitor my AWS resources?" Instead, it feels like the entire team phoned it in and let a large market of monitoring vendors develop as a result. None of those vendors have the level of access to the raw data that CloudWatch does; all of them have built better products. You'd think the CloudWatch team would take a clue from the innovation that's rapidly happening in this space, but that'd require someone to Learn and Be Curious.
Recent data is "eventually consistent", so you always get graphs like the one shown in Figure 1.
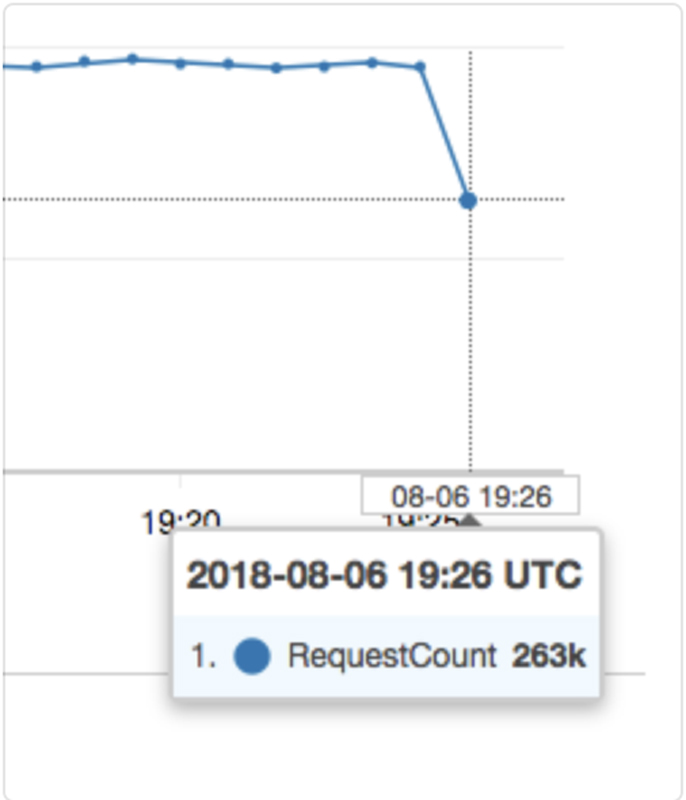
Figure 1. Example CloudWatch Graph
Here in reality, that would be a terrifying thing to see on an accurate dashboard—something is obviously very wrong with your site! For better or worse, the "accurate" description doesn't apply to CloudWatch, and that's just how your graphs always look. "Your metrics will be eventually consistent" is very nearly the last thing you want to hear about your monitoring platform, second only to "what metrics?" This ties directly to...
Let me be very clear here—the real issue isn't the ingestion problem. Absolutely every vendor on the planet has the same issue—you can't display data you don't have. Where CloudWatch drops the ball is in exposing this behavior to the end user without explanation as to what's going on. Thus, until you grow accustomed to it, you have a heart-stopping moment of "what the hell just happened to the site" whenever you glance at a dashboard. This conditions you to be entirely too calm when looking at sensible dashboards when a disaster just happened. If you trust what the CloudWatch dashboards show you, you're making a terrible mistake.
If you're using Lambda or Fargate, you have no choice but to use CloudWatch Logs, wherein searching for everything is absolutely terrible. If you're using CloudWatch Logs to diagnose anything, congratulations: you're diving so deep, you may drown before making it back to the surface. For example, if I have a Lambda function that throws an error, in order to diagnose the problem, I must:
All of your metrics, all of your logs—they're locked away inside CloudWatch's various components. You're not going to find a "page me when this threshold is exceeded" option in CloudWatch; your options are relegated to "design an alert delivery pipeline with baling wire and SNS" or pay a non-AWS vendor for another monitoring product.
CloudWatch keeps all of your metrics. It keeps your logs. It lets you build custom dashboards to view your metrics all in one place. The building blocks of a great service are already here—it's the expression of that utility that falls short, sometimes drastically. The fact that large monitoring vendors are premier sponsors of AWS events would be laughable if CloudWatch ever were to get its act together. You'd not need a third party to make sense of a pure AWS environment, and many of them would starve to death as they grow too weak to interrupt your conversation to ask if they can scan your badge. Choosing to use CloudWatch vs. literally anything else is like buying a car. "Why yes, I would like to buy the Yugo instead of the Honda. After all, it checks all the boxes of technically being a car, so it's fine, right?"
It may very well be that the root cause of many of CloudWatch's failings comes from the product engineers who built it misunderstanding this (admittedly slippery!) Leadership Principle. It's envisioned as passionately expressing your reservations about a decision, but once it's reached that, you commit to the decision that was made. Unfortunately, it appears that the engineering teams responsible for CloudWatch decided to "Disagree in Commits" and inflict their arguments upon the world in the form of the product.
If I were to go on the internet and post about how terrible virtually any other AWS service was, people would rally to that service's defense. It's the internet; people will do that. But when these and many more similar comments about CloudWatch appear, and nobody from AWS pipes in to say "wow, I'm sorry, why do you feel that way?", it's abundantly clear that if any people on the CloudWatch team really care about the product, they've been locked in a malfunctioning bathroom stall for the better part of a decade. These comments go back at least that far, but Amazon is totally on it, rocking the company's "Bias for Action" principle.
The people who build CloudWatch aren't terrible at their jobs; I genuinely believe they don't quite grasp how their product is perceived. Given that it's poor form to write a rant like this and not offer suggestions for positive improvement, here are some product enhancements I'd like to see:
Please don't misunderstand me. I use, enjoy and promote AWS services, and I'm considered to be "an authentic voice" largely because in addition to praising things that are wonderful, I'll call out things that aren't, as I've just done. I've built my career and business on working within that ecosystem. I find AWS employees to be intelligent and well-intentioned, and most of their services quite good. CloudWatch could get there with some work, but it's got a number of very painful usability issues that keep it from being good, let alone great.
Corey Quinn is a Cloud Economist at the Quinn Advisory Group. He has a history as an engineering director, public speaker and cloud architect. Corey specializes in helping companies address horrifying AWS bills and curates LastWeekinAWS.com, a weekly newsletter summarizing the latest in AWS news, blogs and tips, sprinkled with snark. He has never worked at Amazon, for reasons that should be obvious.