If you've read the first two articles in this series, you now should be familiar with Linux kernel control groups, Linux Containers and Docker. But, here's a quick recap: once upon a time, data-center administrators deployed entire operating systems, occupying entire hardware servers to host a few applications each. This was a lot of overhead with a lot to manage. Now scale that across multiple server hosts, and it increasingly became more difficult to maintain. This was a problem—a problem that wasn't easily solved. It would take time for technological evolution to reach the moment where you are able to shrink the operating system and launch these varied applications as microservices hosted across multiple containers on the same physical machine.
In the final part of this series, I explore the method most people use to create, deploy and manage containers. The concept is typically referred to as container orchestration. If I were to focus on Docker, on its own, the technology is extremely simple to use, and running a few images simultaneously is also just as easy. Now, scale that out to hundreds, if not thousands, of images. How do you manage that? Eventually, you need to step back and rely on one of the few orchestration frameworks specifically designed to handle this problem. Enter Kubernetes.
Kubernetes, or k8s (k + eight characters), originally was developed by Google. It's an open-source platform aiming to automate container operations: "deployment, scaling and operations of application containers across clusters of hosts". Google was an early adopter and contributor to the Linux Container technology (in fact, Linux Containers power Google's very own cloud services). Kubernetes eliminates all of the manual processes involved in the deployment and scaling of containerized applications. It's capable of clustering together groups of servers hosting Linux Containers while also allowing administrators to manage those clusters easily and efficiently.
Kubernetes makes it possible to respond to consumer demands quickly by deploying your applications within a timely manner, scaling those same applications with ease and seamlessly rolling out new features, all while limiting hardware resource consumption. It's extremely modular and can be hooked into by other applications or frameworks easily. It also provides additional self-healing services, including auto-placement, auto-replication and auto-restart of containers.
There also exists Docker's own platform called Swarm. It accomplishes much of the same tasks and boasts a lot of the same features. The primary difference between the two is that Swarm is centralized around the use of Docker, while Kubernetes tends to adopt a more generalized container support model.
Sometimes production applications will span across multiple containers, and those containers may be deployed across multiple physical server machines. Both Kubernetes and Swarm give you the orchestration and management capabilities required to deploy and scale those containers to accommodate the always changing workload requirements.
Kubernetes runs on top of an operating system (such as Ubuntu Server, Red Hat Enterprise Linux, SUSE Linux Enterprise Server and so on) and takes a master-slave approach to its functionality. The master signifies the machine (physical or virtual) that controls the Kubernetes nodes. This is where all tasks originate. It is the main controlling unit of the cluster and will take the commands issued by an administrator or DevOps team and, in turn, relay them to the underlying nodes. The master node can be configured to run on a single machine or across multiple machines in a high-availability cluster. This is to ensure fault-tolerance of the cluster and reduce the likelihood of downtime. The nodes are the machines that perform the tasks assigned by the master. The node is sometimes referred to as a Worker or Minion.
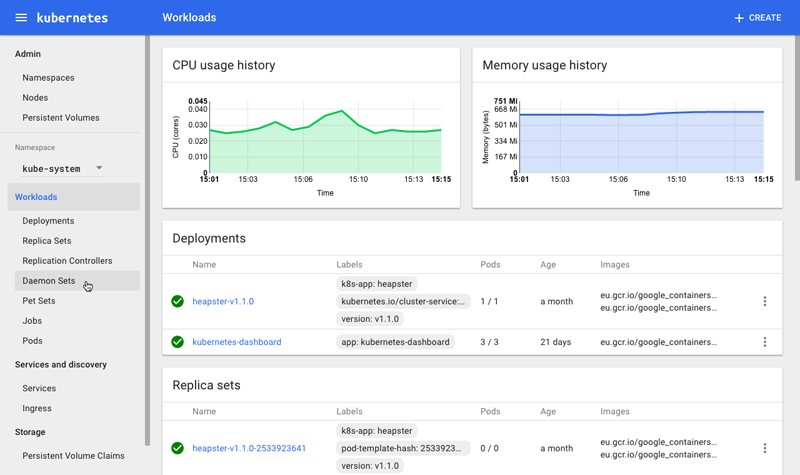
Figure 1. The Kubernetes Web UI Dashboard (Source: kubernetes.io)
Kubernetes is broken down into a set of components, some of which manage individual nodes, while the rest are part of the control plane.
Control plane management:
Node management:
Controllers
A controller drives the state of the cluster by managing a set of pods. The Replication Controller handles pod replication and scaling by running a specified number of copies of a given pod across the entire cluster of nodes. It also can handle the creation of replacement pods in the event of a failing node. The DaemonSet Controller is in charge of running exactly one pod per node. The Job Controller runs pods to completion (that is, as part of a batch job).
Services
In Kubernetes terms, a service consists of a set of pods working together (a one-tier or multi-tier application). As Kubernetes provides service discovery and request routing (by assigning the appropriate static networking parameters), it ensures that all service requests get to the right pod, regardless of where it moves across the cluster. Some of this movement may be a result of pod or node failure. In the end, Kubernetes' self-healing capabilities will get those ailing services back to a pristine state automatically.
Pods
When a Kubernetes master deploys a group of one or more containers to a single node, it does so by creating a pod. Pods abstract the networking and storage from the container, and all of the containers within a pod will share the same IP address, hostname and more, allowing it to be moved around in the cluster without complication.
The kubelet will monitor each and every pod. If it's not in a good state, it will redeploy that pod to the same node. Apart from this, a heartbeat messaging mechanism will relay the node status to the master every few seconds. As soon as the master detects a node failure, the Replication Controller will launch the now affected pods onto another healthy node.
So, how does Docker fit into all of this? Docker still functions as it was meant to function. When a Kubernetes master schedules a pod to a node, the kubelet running on that node will direct Docker in launching the desired containers. The kubelet will continue by monitoring those containers while also collecting information for the master. Docker still will be in full control of the containers running on the node and also will be responsible for starting and stopping them. The only difference here is that you now have an automated system sending these requests to Docker instead of the system administrator running the same tasks manually.
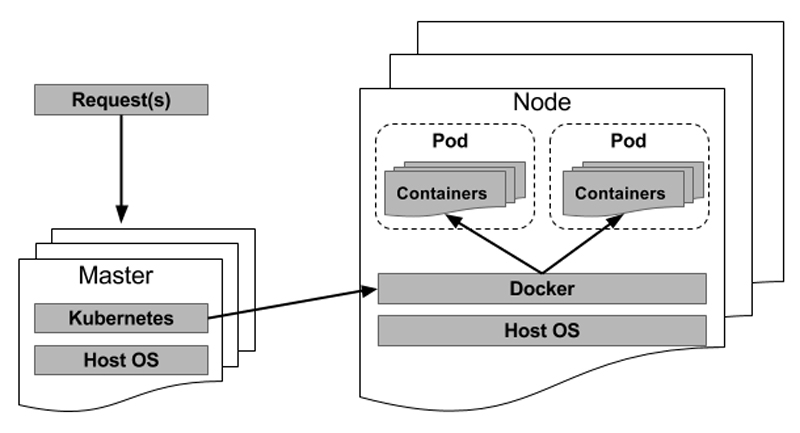
Figure 2. A General Model of Pod Creation/Management
Modern Linux distributions have made the installation and configuration of a Kubernetes host quite simple. I use Ubuntu Server 16.04 for the following example. Note: you'll need a substantial amount of memory and storage to run with this example properly.
To begin, install conjure-up:
$ sudo snap install conjure-up --classic
conjure-up is a neat wrapper around Juju, MAAS and LXD. It's advertised as a
turnkey solution to enable big and complicated software stacks—Kubernetes
included. conjure-up essentially processes a collection of scripts leveraging
the previously named technologies.
Next, install lxd:
$ sudo snap install lxd
LXD is Canonical's (Ubuntu's) homegrown container technology. Whereas Docker is more focused on deploying applications, LXD specializes in deploying Linux virtual machines.
In order to meet all requirements for installation to the localhost, you'll need to create at least one LXD storage pool:
$ sudo /snap/bin/lxc storage create kube-test dir source=/mnt
Storage pool kube-test created
You can view the newly created pool with the following command:
$ sudo /snap/bin/lxc storage list
+-----------+-------------+--------+--------+---------+
| NAME | DESCRIPTION | DRIVER | SOURCE | USED BY |
+-----------+-------------+--------+--------+---------+
| kube-test | | dir | /mnt | 0 |
+-----------+-------------+--------+--------+---------+
You'll also need to create a networking bridge:
$ /snap/bin/lxc network create lxdbr0 ipv4.address=auto
↪ipv4.nat=true ipv6.address=none ipv6.nat=false
Network lxdbr0 created
Run conjure-up:
$ conjure-up
You'll see a menu, where you can select the Canonical distribution of Kubernetes.
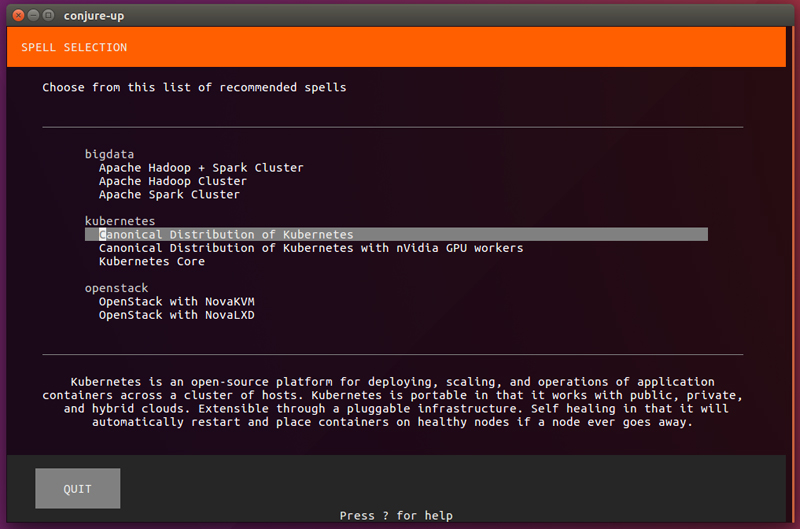
Figure 3. The conjure-up Framework Selection Menu
Then you'll be prompted with the option to install various and useful add-on packages to your Kubernetes deployment.
A few more options will be presented, such as where to deploy (for example,
the cloud or locally). For the purpose of this example, let's install and
deploy to the localhost, so in the following menu, select
the network bridge you created earlier (lxdbr0) and the storage pool
(kube-test). A couple simple questions later, and the installation process
begins. The entire process will take quite a while.
Hopefully, installing the Kubernetes main components doesn't take too long, but let's assume that by this point, everything is completed. As part of the post-install process, the kubectl client application will be installed, and then the host system will capture the Kubernetes cluster status. You will be provided with an installation summary.
When everything has completed, run the following kubectl command:
$ ~/kubectl cluster-info
You'll see a short display of the cluster's running components, including addresses to various dashboards and services.
Cloud native computing, often referred to as serverless computing, is not only the latest trending buzzword in the data center, but it also offers a new way of hosting applications. The idea challenges what traditionally has been the norm and puts more power into the application itself while abstracting away everything underneath it. But before getting into the details of serverless computing, here's a crash course in cloud computing.
Going Serverless
Cloud native computing is a relatively recent term describing the more-modern trend of deploying and managing applications. The idea is pretty straightforward. Each application or process is packaged into its own container, which in turn is dynamically orchestrated (that is, scheduled and managed) across a cluster of nodes. This approach moves applications away from physical hardware and operating system dependency and into their own self-contained and sandboxed environment, which can run anywhere within the data center transparently and seamlessly. The cloud native approach is about separating the various components of application delivery.
The Evolution of Containers in the Cloud
As you would expect, container technology has helped accelerate cloud adoption. Think about it. You have these persistent containerized application images that within seconds are spun up or down as needed and balanced across multiple nodes or data-center locations to achieve the best in quality of service (QoS). Even the big-time public cloud providers make use of the same container technologies and for the same reason: rapid application deployment. For instance, Amazon, Microsoft and Google provide their container services with Docker. And as it applies to the greater serverless ecosystem, the applications hosted in those containers are stateless and event-triggered. This means that a third-party component will manage access to this application, as it is needed and invoked.
Now, when I think of a true serverless solution, one of the first things that comes to mind is Amazon's AWS Lambda. Amazon takes serverless to the next level with Lambda by spinning up a container to host the applications you need, ensuring access and availability for your business or service. Under this model, there is no need to provision or manage physical or virtual servers. Assuming it is in a stable or production state, you just deploy your code, and you're done. With Lambda, you don't manage the container (further reducing your overhead). Your code is just deployed within an isolated containerized environment. It's pretty straightforward. AWS Lambda enables user-defined code functions to be triggered directly via a user-defined HTTPS request. The way Lambda differs from traditional containerized deployment is that Amazon has provided a framework for developers to upload their event-driven application code (written in Node.js, Python, Java or C#) and respond to events, such as website clicks, within milliseconds. All libraries and dependencies to run the bulk of your code are provided for within the container. Lambda scales automatically to support the exact needs of your application.
As for the types of events (labeled an event source) on which to trigger your application, or code handlers, Amazon has made it so you can trigger on website visits or clicks, a REST HTTP request to its API gateway, a sensor reading on your Internet of Things (IoT) device, or even an upload of a photograph to an S3 bucket. This API gateway forms the bridge that connects all parts of AWS Lambda. For example, a developer can write a handler to trigger on HTTPS request events.
Let's say you need to enable a level of granularity to your code. Lambda accommodates this by allowing developers to write modular handlers. For instance, you can write one handler to trigger for each API method, and each handler can be invoked, updated and altered independently of the others.
Lambda allows developers to combine all required dependencies (that is, libraries, native binaries or even external web services) to your function into a single package, giving a handler the freedom to reach out to any of those dependencies as it needs them.
Now, how does this compare to an Amazon AWS Elastic Cloud Computing (EC2) instance? Well, the short answer is that it's a lot more simplified, and by simplified, I mean that there's zero to no overhead on configuring or maintaining your operating environment. If you need more out of your environment that requires access to a full-blown operating system or container, you can spin up an EC2 virtual instance. EC2 provides users the flexibility to customize their virtual machine with both the hardware and software it will host. If you only need to host a function or special-purpose application, that's where Lambda becomes the better choice. With Lambda, there isn't much to customize—and sometimes, less is good.
The Cloud Native Computing Foundation
Formed in 2015, the Cloud Native Computing Foundation (CNCF) was assembled to help standardize these recent paradigm shifts in hosting Cloud services—that is, to unify and define the cloud native era. Although the primary goal of the foundation is to be the best place to host cloud native software projects. The foundation is home to many cloud-centric projects, including the Kubernetes orchestration framework.
To help standardize this new trend of computing, the foundation has divided the entire architecture into a set of subsystems, each with its own set of standardized APIs for inter-component communication. Subsystems include orchestration, resource scheduling and distributed systems services.
You can learn more about the foundation by visiting the foundation's official website.
Kubernetes expands beyond the management of the traditional container and allows you to scale to meet consumer demands effectively and efficiently. And with modern and major Linux distributions, deploying a Kubernetes cluster is as simple as running a script and answering a few questions.
As you explore this wonderful technology further, know that you are not alone. There are companies that provide services and solutions centered around Kubernetes. One such company is Heptio, which was founded by Kubernetes co-creators Craig McLuckie and Joe Beda. Centered around both developers and system administrators, Heptio's products and services simplify and scale the Kubernetes ecosystem.
There is also the need to maintain both security and compliance of your container images within that same ecosystem. Again, when you scale to the thousands, management of such things is near impossible. That's where companies like Twistlock do the heavy-lifting for you. Twistlock develops and distributes a product of the same name focusing on nothing but Docker image security and compliance. It also can be operated from and managed by orchestration platforms including Kubernetes.
Kubernetes main website is here.
Further reading on Kubernetes from Linux Journal:
Petros Koutoupis, LJ Editor at Large, is currently a senior platform architect at IBM for its Cloud Object Storage division (formerly Cleversafe). He is also the creator and maintainer of the RapidDisk Project. Petros has worked in the data storage industry for well over a decade and has helped pioneer the many technologies unleashed in the wild today.
