In this article, I describe how Docker containers flow through the DevOps pipeline. I also cover some advanced DevOps concepts (borrowed from object-oriented programming) on how to use dependency injection and encapsulation to improve the DevOps process. And finally, I show how containerization can be useful for the development and testing process itself, rather than just as a place to serve up an application after it's written.
Containers are hot in DevOps shops, and their benefits from an operations and service delivery point of view have been covered well elsewhere. If you want to build a Docker container or deploy a Docker host, container or swarm, a lot of information is available. However, very few articles talk about how to develop inside the Docker containers that will be reused later in the DevOps pipeline, so that's what I focus on here.

Figure 1. Stages a Docker Container Moves Through in a Typical DevOps Pipeline
Two common workflows exist for developing software for use inside Docker containers:
Both workflows have advantages, but local mounting is inherently simpler. For that reason, I focus on the mounting solution as "the simplest thing that could possibly work" here.
How Docker Containers Move between Environments
A core tenet of DevOps is that the source code and runtimes that will be used in production are the same as those used in development. In other words, the most effective pipeline is one where the identical Docker image can be reused for each stage of the pipeline.
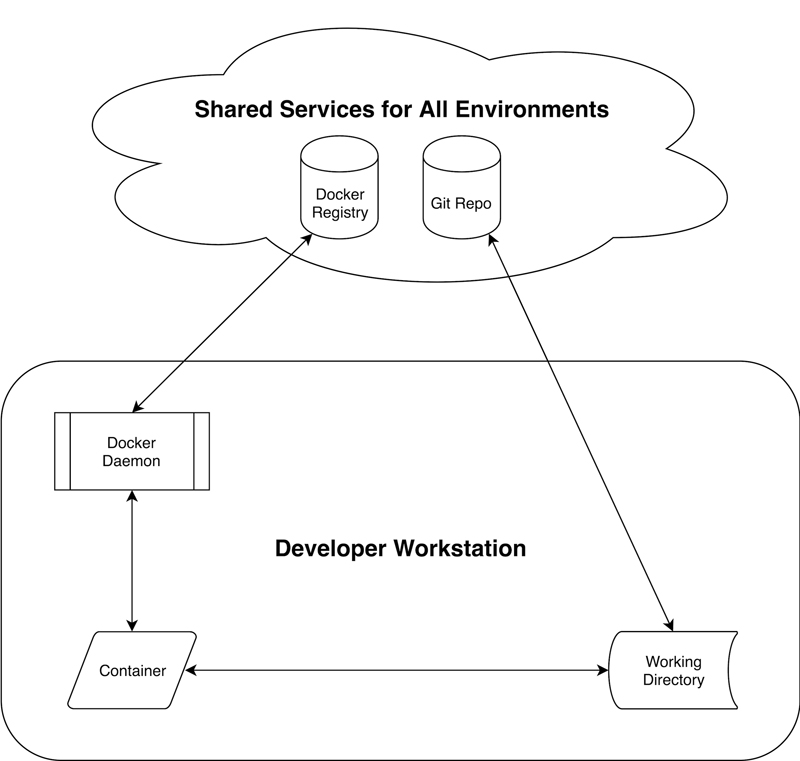
Figure 2. Idealized Docker-Based DevOps Pipeline
The notion here is that each environment uses the same Docker image and code base, regardless of where it's running. Unlike systems such as Puppet, Chef or Ansible that converge systems to a defined state, an idealized Docker pipeline makes duplicate copies (containers) of a fixed image in each environment. Ideally, the only artifact that really moves between environmental stages in a Docker-centric pipeline is the ID of a Docker image; all other artifacts should be shared between environments to ensure consistency.
Handling Differences between Environments
In the real world, environmental stages can vary. As a case point, your QA and staging environments may contain different DNS names, different firewall rules and almost certainly different data fixtures. Combat this per-environment drift by standardizing services across your different environments. For example, ensuring that DNS resolves "db1.example.com" and "db2.example.com" to the right IP addresses in each environment is much more Docker-friendly than relying on configuration file changes or injectable templates that point your application to differing IP addresses. However, when necessary, you can set environment variables for each container rather than making stateful changes to the fixed image. These variables then can be managed in a variety of ways, including the following:
Consider a Ruby microservice that runs inside a Docker container. The service accesses a database somewhere. In order to run the same Ruby image in each different environment, but with environment-specific data passed in as variables, your deployment orchestration tool might use a shell script like this one, "Example Mircoservice Deployment":
# Reuse the same image to create containers in each
# environment.
docker pull ruby:latest
# Bash function that exports key environment
# variables to the container, and then runs Ruby
# inside the container to display the relevant
# values.
microservice () {
docker run -e STAGE -e DB --rm ruby \
/usr/local/bin/ruby -e \
'printf("STAGE: %s, DB: %s\n",
ENV["STAGE"],
ENV["DB"])'
}
Table 1 shows an example of how environment-specific information for Development, Quality Assurance and Production can be passed to otherwise-identical containers using exported environment variables.
| Development | Quality Assurance | Production |
export STAGE=dev DB=db1; microservice |
export STAGE=qa DB=db2; microservice |
export STAGE=prod DB=db3; microservice |
To see this in action, open a terminal with a Bash prompt and run the commands from the "Example Microservice Deployment" script above to pull the Ruby image onto your Docker host and create a reusable shell function. Next, run each of the commands from the table above in turn to set up the proper environment variables and execute the function. You should see the output shown in Table 2 for each simulated environment.
| Development | Quality Assurance | Production |
STAGE: dev, DB: db1 |
STAGE: qa, DB: db2 |
STAGE: prod, DB: db3 |
Despite being a rather simplistic example, what's being accomplished is really quite extraordinary! This is DevOps tooling at its best: you're re-using the same image and deployment script to ensure maximum consistency, but each deployed instance (a "container" in Docker parlance) is still being tuned to operate properly within its pipeline stage.
With this approach, you limit configuration drift and variance by ensuring that the exact same image is re-used for each stage of the pipeline. Furthermore, each container varies only by the environment-specific data or artifacts injected into them, reducing the burden of maintaining multiple versions or per-environment architectures.
The previous simulation didn't really connect to any services outside the Docker container. How well would this work if you needed to connect your containers to environment-specific things outside the container itself?
Next, I simulate a Docker container moving from development through other stages of the DevOps pipeline, using a different database with its own data in each environment. This requires a little prep work first.
First, create a workspace for the example files. You can do this by cloning the examples from GitHub or by making a directory. As an example:
# Clone the examples from GitHub.
git clone \
https://github.com/CodeGnome/SDCAPS-Examples
cd SDCAPS-Examples/db
# Create a working directory yourself.
mkdir -p SDCAPS-Examples/db
cd SDCAPS-Examples/db
The following SQL files should be in the db directory if you cloned the example repository. Otherwise, go ahead and create them now.
db1.sql:
-- Development Database
PRAGMA foreign_keys=OFF;
BEGIN TRANSACTION;
CREATE TABLE AppData (
login TEXT UNIQUE NOT NULL,
name TEXT,
password TEXT
);
INSERT INTO AppData
VALUES ('root','developers','dev_password'),
('dev','developers','dev_password');
COMMIT;
db2.sql:
-- Quality Assurance (QA) Database
PRAGMA foreign_keys=OFF;
BEGIN TRANSACTION;
CREATE TABLE AppData (
login TEXT UNIQUE NOT NULL,
name TEXT,
password TEXT
);
INSERT INTO AppData
VALUES ('root','qa admins','admin_password'),
('test','qa testers','user_password');
COMMIT;
db3.sql:
-- Production Database
PRAGMA foreign_keys=OFF;
BEGIN TRANSACTION;
CREATE TABLE AppData (
login TEXT UNIQUE NOT NULL,
name TEXT,
password TEXT
);
INSERT INTO AppData
VALUES ('root','production',
'$1$Ax6DIG/K$TDPdujixy5DDscpTWD5HU0'),
('deploy','devops deploy tools',
'$1$hgTsycNO$FmJInHWROtkX6q7eWiJ1p/');
COMMIT;
Next, you need a small utility to create (or re-create) the various SQLite databases. This is really just a convenience script, so if you prefer to initialize or load the SQL by hand or with another tool, go right ahead:
#!/usr/bin/env bash
# You assume the database files will be stored in an
# immediate subdirectory named "db" but you can
# override this using an environment variable.
: "${DATABASE_DIR:=db}"
cd "$DATABASE_DIR"
# Scan for the -f flag. If the flag is found, and if
# there are matching filenames, verbosely remove the
# existing database files.
pattern='(^|[[:space:]])-f([[:space:]]|$)'
if [[ "$*" =~ $pattern ]] &&
compgen -o filenames -G 'db?' >&-
then
echo "Removing existing database files ..."
rm -v db? 2> /dev/null
echo
fi
# Process each SQL dump in the current directory.
echo "Creating database files from SQL ..."
for sql_dump in *.sql; do
db_filename="${sql_dump%%.sql}"
if [[ ! -f "$db_filename" ]]; then
sqlite3 "$db_filename" < "$sql_dump" &&
echo "$db_filename created"
else
echo "$db_filename already exists"
fi
done
When you run ./create_databases.sh, you should see:
Creating database files from SQL ...
db1 created
db2 created
db3 created
If the utility script reports that the database files already exist, or if you
want to reset the database files to their initial state, you can call
the script again with the -f flag to re-create them from the associated .sql
files.
You probably noticed that some of the SQL files contained clear-text passwords while others have valid Linux password hashes. For the purposes of this article, that's largely a contrivance to ensure that you have different data in each database and to make it easy to tell which database you're looking at from the data itself.
For security though, it's usually best to ensure that you have a properly hashed password in any source files you may store. There are a number of ways to generate such passwords, but the OpenSSL library makes it easy to generate salted and hashed passwords from the command line.
Tip: for optimum security, don't include your desired password or
passphrase as an argument to OpenSSL on the command line, as it could
then be seen in the process list. Instead, allow OpenSSL to prompt you
with Password: and be sure to use a strong passphrase.
To generate a salted MD5 password with OpenSSL:
$ openssl passwd \
-1 \
-salt "$(openssl rand -base64 6)"
Password:
Then you can paste the salted hash into /etc/shadow, an SQL file, utility script or wherever else you may need it.
Now that you have some external resources to experiment with, you're ready to simulate a deployment. Let's start by running a container in your development environment. I follow some DevOps best practices here and use fixed image IDs and defined gem versions.
DevOps Best Practices for Docker Image IDs
To ensure that you're re-using the same image across pipeline stages, always use an image ID rather than a named tag or symbolic reference when pulling images. For example, while the "latest" tag might point to different versions of a Docker image over time, the SHA-256 identifier of an image version remains constant and also provides automatic validation as a checksum for downloaded images.
Furthermore, you always should use a fixed ID for assets you're injecting into your containers. Note how you specify a specific version of the SQLite3 Ruby gem to inject into the container at each stage. This ensures that each pipeline stage has the same version, regardless of whether the most current version of the gem from a RubyGems repository changes between one container deployment and the next.
Getting a Docker Image ID
When you pull a Docker image, such as ruby:latest, Docker will report
the digest of the image on standard output:
$ docker pull ruby:latest
latest: Pulling from library/ruby
Digest:
sha256:eed291437be80359321bf66a842d4d542a789e
↪687b38c31bd1659065b2906778
Status: Image is up to date for ruby:latest
If you want to find the ID for an image you've already pulled, you can
use the inspect sub-command to extract the digest from Docker's JSON
output—for example:
$ docker inspect \
--format='{{index .RepoDigests 0}}' \
ruby:latest
ruby@sha256:eed291437be80359321bf66a842d4d542a789
↪e687b38c31bd1659065b2906778
First, you export the appropriate environment variables for development. These values will override the defaults set by your deployment script and affect the behavior of your sample application:
# Export values we want accessible inside the Docker
# container.
export STAGE="dev" DB="db1"
Next, implement a script called container_deploy.sh that will simulate deployment across multiple environments. This is an example of the work that your deployment pipeline or orchestration engine should do when instantiating containers for each stage:
#!/usr/bin/env bash
set -e
####################################################
# Default shell and environment variables.
####################################################
# Quick hack to build the 64-character image ID
# (which is really a SHA-256 hash) within a
# magazine's line-length limitations.
hash_segments=(
"eed291437be80359321bf66a842d4d54"
"2a789e687b38c31bd1659065b2906778"
)
printf -v id "%s" "${hash_segments[@]}"
# Default Ruby image ID to use if not overridden
# from the script's environment.
: "${IMAGE_ID:=$id}"
# Fixed version of the SQLite3 gem.
: "${SQLITE3_VERSION:=1.3.13}"
# Default pipeline stage (e.g. dev, qa, prod).
: "${STAGE:=dev}"
# Default database to use (e.g. db1, db2, db3).
: "${DB:=db1}"
# Export values that should be visible inside the
# container.
export STAGE DB
####################################################
# Setup and run Docker container.
####################################################
# Remove the Ruby container when script exits,
# regardless of exit status unless DEBUG is set.
cleanup () {
local id msg1 msg2 msg3
id="$container_id"
if [[ ! -v DEBUG ]]; then
docker rm --force "$id" >&-
else
msg1="DEBUG was set."
msg2="Debug the container with:"
msg3=" docker exec -it $id bash"
printf "\n%s\n%s\n%s\n" \
"$msg1" \
"$msg2" \
"$msg3" \
> /dev/stderr
fi
}
trap "cleanup" EXIT
# Set up a container, including environment
# variables and volumes mounted from the local host.
docker run \
-d \
-e STAGE \
-e DB \
-v "${DATABASE_DIR:-${PWD}/db}":/srv/db \
--init \
"ruby@sha256:$IMAGE_ID" \
tail -f /dev/null >&-
# Capture the container ID of the last container
# started.
container_id=$(docker ps -ql)
# Inject a fixed version of the database gem into
# the running container.
echo "Injecting gem into container..."
docker exec "$container_id" \
gem install sqlite3 -v "$SQLITE3_VERSION" &&
echo
# Define a Ruby script to run inside our container.
#
# The script will output the environment variables
# we've set, and then display contents of the
# database defined in the DB environment variable.
ruby_script='
require "sqlite3"
puts %Q(DevOps pipeline stage: #{ENV["STAGE"]})
puts %Q(Database for this stage: #{ENV["DB"]})
puts
puts "Data stored in this database:"
Dir.chdir "/srv/db"
db = SQLite3::Database.open ENV["DB"]
query = "SELECT rowid, * FROM AppData"
db.execute(query) do |row|
print " " * 4
puts row.join(", ")
end
'
# Execute the Ruby script inside the running
# container.
docker exec "$container_id" ruby -e "$ruby_script"
There are a few things to note about this script. First and foremost, your real-world needs may be either simpler or more complex than this script provides for. Nevertheless, it provides a reasonable baseline on which you can build.
Second, you may have noticed the use of the tail command when creating the
Docker container. This is a common trick used for building containers that
don't have a long-running application to keep the container in a running
state. Because you are re-entering the container using multiple
exec commands,
and because your example Ruby application runs once and exits,
tail sidesteps a
lot of ugly hacks needed to restart the container continually or keep it
running while debugging.
Go ahead and run the script now. You should see the same output as listed below:
$ ./container_deploy.sh
Building native extensions. This could take a while...
Successfully installed sqlite3-1.3.13
1 gem installed
DevOps pipeline stage: dev
Database for this stage: db1
Data stored in this database:
1, root, developers, dev_password
2, dev, developers, dev_password
Simulating Deployment across Environments
Now you're ready to move on to something more ambitious. In the preceding example, you deployed a container to the development environment. The Ruby application running inside the container used the development database. The power of this approach is that the exact same process can be re-used for each pipeline stage, and the only thing you need to change is the database to which the application points.
In actual usage, your DevOps configuration management or orchestration engine
would handle setting up the correct environment variables for each stage of
the pipeline. To simulate deployment to multiple environments, populate an
associative array in Bash with the values each stage will need and then run
the script in a for loop:
declare -A env_db
env_db=([dev]=db1 [qa]=db2 [prod]=db3)
for env in dev qa prod; do
export STAGE="$env" DB="${env_db[$env]}"
printf "%s\n" "Deploying to ${env^^} ..."
./container_deploy.sh
done
This stage-specific approach has a number of benefits from a DevOps point of view. That's because:
STAGE and DB (or other values) injected into the container at runtime.
Imagine for a moment that you have a more complex application than the one you've been working with here. Maybe your QA or staging environments have large data sets that you don't want to re-create on local hosts, or maybe you need to point at a network resource that may move around at runtime. You can handle this by using a well known name that is resolved by a external resource instead.
You can show this at the filesystem level by using a symlink. The benefit of this approach is that the application and container no longer need to know anything about which database is present, because the database is always named "db". Consider the following:
declare -A env_db
env_db=([dev]=db1 [qa]=db2 [prod]=db3)
for env in dev qa prod; do
printf "%s\n" "Deploying to ${env^^} ..."
(cd db; ln -fs "${env_db[$env]}" db)
export STAGE="$env" DB="db"
./container_deploy.sh
done
Likewise, you can configure your Domain Name Service (DNS) or a Virtual IP (VIP) on your network to ensure that the right database host or cluster is used for each stage. As an example, you might ensure that db.example.com resolves to a different IP address at each pipeline stage.
Sadly, the complexity of managing multiple environments never truly goes away—it just hopefully gets abstracted to the right level for your organization. Think of your objective as similar to some object-oriented programming (OOP) best practices: you're looking to create pipelines that minimize things that change and to allow applications and tools to rely on a stable interface. When changes are unavoidable, the goal is to keep the scope of what might change as small as possible and to hide the ugly details from your tools to the greatest extent that you can.
If you have thousands or tens of thousands of servers, it's often better to change a couple DNS entries without downtime rather than rebuild or redeploy 10,000 application containers. Of course, there are always counter-examples, so consider the trade-offs and make the best decisions you can to encapsulate any unavoidable complexity.
I've spent a lot of time explaining how to ensure that your development containers look like the containers in use in other stages of the pipeline. But have I really described how to develop inside these containers? It turns out I've actually covered the essentials, but you need to shift your perspective a little to put it all together.
The same processes used to deploy containers in the previous sections also
allow you to work inside a container. In particular, the previous examples have
touched on how to bind-mount code and artifacts from the host's filesystem
inside a container using the -v or --volume flags. That's how
the container_deploy.sh script mounts database files on /srv/db inside the container. The
same mechanism can be used to mount source code, and the Docker
exec command
then can be used to start a shell, editor or other development process inside
the container.
The develop.sh utility script is designed to showcase this ability. When you run it, the script creates a Docker container and drops you into a Ruby shell inside the container. Go ahead and run ./develop.sh now:
#!/usr/bin/env bash
id="eed291437be80359321bf66a842d4d54"
id+="2a789e687b38c31bd1659065b2906778"
: "${IMAGE_ID:=$id}"
: "${SQLITE3_VERSION:=1.3.13}"
: "${STAGE:=dev}"
: "${DB:=db1}"
export DB STAGE
echo "Launching '$STAGE' container..."
docker run \
-d \
-e DB \
-e STAGE \
-v "${SOURCE_CODE:-$PWD}":/usr/local/src \
-v "${DATABASE_DIR:-${PWD}/db}":/srv/db \
--init \
"ruby@sha256:$IMAGE_ID" \
tail -f /dev/null >&-
container_id=$(docker ps -ql)
show_cmd () {
enter="docker exec -it $container_id bash"
clean="docker rm --force $container_id"
echo -ne \
"\nRe-enter container with:\n\t${enter}"
echo -ne \
"\nClean up container with:\n\t${clean}\n"
}
trap 'show_cmd' EXIT
docker exec "$container_id" \
gem install sqlite3 -v "$SQLITE3_VERSION" >&-
docker exec \
-e DB \
-e STAGE \
-it "$container_id" \
irb -I /usr/local/src -r sqlite3
Once inside the container's Ruby read-evaluate-print loop (REPL), you can develop your source code as you normally would from outside the container. Any source code changes will be seen immediately from inside the container at the defined mountpoint of /usr/local/src. You then can test your code using the same runtime that will be available later in your pipeline.
Let's try a few basic things just to get a feel for how this works. Ensure that you have the sample Ruby files installed in the same directory as develop.sh. You don't actually have to know (or care) about Ruby programming for this exercise to have value. The point is to show how your containerized applications can interact with your host's development environment.
example_query.rb:
# Ruby module to query the table name via SQL.
module ExampleQuery
def self.table_name
path = "/srv/db/#{ENV['DB']}"
db = SQLite3::Database.new path
sql =<<-'SQL'
SELECT name FROM sqlite_master
WHERE type='table'
LIMIT 1;
SQL
db.get_first_value sql
end
end
source_list.rb:
# Ruby module to list files in the source directory
# that's mounted inside your container.
module SourceList
def self.array
Dir['/usr/local/src/*']
end
def self.print
puts self.array
end
end
At the IRB prompt (irb(main):001:0>), try the following code to make
sure everything is working as expected:
# returns "AppData"
load 'example_query.rb'; ExampleQuery.table_name
# prints file list to standard output; returns nil
load 'source_list.rb'; SourceList.print
In both cases, Ruby source code is being read from /usr/local/src, which is bound to the current working directory of the develop.sh script. While working in development, you could edit those files in any fashion you chose and then load them again into IRB. It's practically magic!
It works the other way too. From inside the container, you can use any tool or feature of the container to interact with your source directory on the host system. For example, you can download the familiar Docker whale logo and make it available to your development environment from the container's Ruby REPL:
Dir.chdir '/usr/local/src'
cmd =
"curl -sLO " <<
"https://www.docker.com" <<
"/sites/default/files" <<
"/vertical_large.png"
system cmd
Both /usr/local/src and the matching host directory now contain the vertical_large.png graphic file. You've added a file to your source tree from inside the Docker container!

Figure 3. Docker Logo on the Host Filesystem and inside the Container
When you press Ctrl-D to exit the REPL, the develop.sh script informs you how to reconnect to the still-running container, as well as how to delete the container when you're done with it. Output will look similar to the following:
Re-enter container with:
docker exec -it 9a2c94ebdee8 bash
Clean up container with:
docker rm --force 9a2c94ebdee8
As a practical matter, remember that the develop.sh script is setting Ruby's
LOAD_PATH and requiring the sqlite3 gem for you when launching the first
instance of IRB. If you exit that process, launching another instance of IRB
with docker exec or from a Bash shell inside the container may not do what
you expect. Be sure to run irb -I /usr/local/src -r sqlite3 to
re-create that
first smooth experience!
I covered how Docker containers typically flow through the DevOps pipeline, from development all the way to production. I looked at some common practices for managing the differences between pipeline stages and how to use stage-specific data and artifacts in a reproducible and automated fashion. Along the way, you also may have learned a little more about Docker commands, Bash scripting and the Ruby REPL.
I hope it's been an interesting journey. I know I've enjoyed sharing it with you, and I sincerely hope I've left your DevOps and containerization toolboxes just a little bit larger in the process.