So, you want a cool dynamic desktop wallpaper without dodgy programs and a million viruses? The good news is, this is Linux, and anything is possible. I started this project because I was bored of my standard OS desktop wallpaper, and I have slowly created a plethora of scripts to pull images from several sites and set them as my desktop background. It's a nice little addition to my day—being greeted by a different cat picture or a panorama of a country I didn't know existed. The great news is that it's easy to do, so let's get started.
BAsh (The Bourne Again shell) is standard across almost all *NIX systems and provides a wide range of operations "out of the box", which would take time and copious lines of code to achieve in a conventional coding or even scripting language. Additionally, there's no need to re-invent the wheel. It's much easier to use somebody else's program to download webpages for example, than to deal with low-level system sockets in C.
The concept is simple. Choose a site with images you like and "scrape" the page for those images. Then once you have a direct link, you download them and set them as the desktop wallpaper using the display manager. Easy right?
To start off, let's venture to every programmer's second-favorite page after Stack Overflow: xkcd. Loading the page, you should be greeted by the daily comic strip and some other data.
Now, what if you want to see this comic without venturing to the xkcd site? You need a script to do it for you. First, you need to know how the webpage looks to the computer, so download it and take a look. To do this, use wget, an easy-to-use, commonly installed, non-interactive, network downloader. So, on the command line, call wget, and give it the link to the page:
user@LJ $: wget https://www.xkcd.com/
--2018-01-27 21:01:39-- https://www.xkcd.com/
Resolving www.xkcd.com... 151.101.0.67, 151.101.192.67,
↪151.101.64.67, ...
Connecting to www.xkcd.com|151.101.0.67|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 2606 (2.5K) [text/html]
Saving to: 'index.html'
index.html 100%
[==========================================================>]
2.54K --.-KB/s in 0s
2018-01-27 21:01:39 (23.1 MB/s) - 'index.html' saved [6237]
As you can see in the output, the page has been saved to index.html in your current directory. Using your favourite editor, open it and take a look (I'm using nano for this example):
user@LJ $: nano index.html
Now you might realize, despite this being a rather bare page, there's a lot of code in that file. Instead of going through it all, let's use grep, which is perfect for this task. Its sole function is to print lines matching your search. Grep uses the syntax:
user@LJ $: grep [search] [file]
Looking at the daily comic, its current title is "Night Sky". Searching for "night" with grep yields the following results:
user@LJ $: grep "night" index.html
<img src="//imgs.xkcd.com/comics/night_sky.png"
↪title="There's a mountain lion nearby, but it
↪didn't notice you because it's
↪reading Facebook." alt="Night Sky"
↪srcset="//imgs.xkcd.com/comics/night_sky_2x.png 2x"/>
Image URL (for hotlinking/embedding):
↪https://imgs.xkcd.com/comics/night_sky.png
The grep search has returned two image links in the file each related to "night". Looking at those two lines, one is the image in the page, and the other is for hotlinking and is already a usable link. You'll be obtaining the first link, however, as it is more representative of other pages that don't provide an easy link, and it serves as a good introduction to the use of grep and cut.
To get the first link out of the page, you first need to identify it in the file programmatically. Let's try grep again, but this time instead of using a string you already know ("night"), let's approach as if you know nothing about the page. Although the link will be different, the HTML should remain the same; therefore, <img src= always should appear before the link you want:
user@LJ $: grep "img src=" index.html
<span><a href="/"><img src="/s/0b7742.png" alt="xkcd.com logo"
↪height="83" width="185"/></a></span>
<img src="//imgs.xkcd.com/comics/night_sky.png"
↪title="There's a mountain lion nearby, but it
↪didn't notice you because it's reading Facebook."
↪alt="Night Sky" srcset="//imgs.xkcd.com/comics/
↪night_sky_2x.png 2x"/>
<img src="//imgs.xkcd.com/s/a899e84.jpg" width="520"
↪height="100" alt="Selected Comics" usemap="#comicmap"/>
It looks like there are three images on the page. Comparing these results from the first grep, you'll see that <img src="//imgs.xkcd.com/comics/night_sky.png" has been returned again. This is the image you want, but how do you separate it from the other two? The easiest way is to pass it through another grep. The other two links contain "/s/"; whereas the link we want contains "/comics/". So, you need to grep the output of the last command for "/comics/". To pass along the output of the last command, use the pipe character (|):
user@LJ $: grep "img src=" index.html | grep "/comics/"
<img src="//imgs.xkcd.com/comics/night_sky.png"
↪title="There's a mountain lion nearby, but it
↪didn't notice you because it's reading Facebook."
↪alt="Night Sky" srcset="//imgs.xkcd.com/comics/
↪night_sky_2x.png 2x"/>
And, there's the line! Now you just need to separate the image link from the rest of it with the cut command. cut uses the syntax:
user@LJ $: cut [-d delimeter] [-f field] [-c characters]
To cut the link from the rest of the line, you'll want to cut next to the quotation mark and select the field before the next quotation mark. In other words, you want the text between the quotes, or the link, which is done like this:
user@LJ $: grep "img src=" index.html | grep "/comics/" |
↪cut -d\" -f2
//imgs.xkcd.com/comics/night_sky.png
And, you've got the link. But wait! What about those pesky forward slashes at the beginning? You can cut those out too:
user@LJ $: grep "img src=" index.html | grep "/comics/" |
↪cut -d\" -f 2 | cut -c 3-
imgs.xkcd.com/comics/night_sky.png
Now you've just cut the first three characters from the line, and you're left with a link straight to the image. Using wget again, you can download the image:
user@LJ $: wget imgs.xkcd.com/comics/night_sky.png
--2018-01-27 21:42:33-- http://imgs.xkcd.com/comics/night_sky.png
Resolving imgs.xkcd.com... 151.101.16.67, 2a04:4e42:4::67
Connecting to imgs.xkcd.com|151.101.16.67|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 54636 (53K) [image/png]
Saving to: 'night_sky.png'
night_sky.png 100%
[===========================================================>]
53.36K --.-KB/s in 0.04s
2018-01-27 21:42:33 (1.24 MB/s) - 'night_sky.png'
↪saved [54636/54636]
Now you have the image in your directory, but its name will change when the comic's name changes. To fix that, tell wget to save it with a specific name:
user@LJ $: wget "$(grep "img src=" index.html | grep "/comics/"
↪| cut -d\" -f2 | cut -c 3-)" -O wallpaper
--2018-01-27 21:45:08-- http://imgs.xkcd.com/comics/night_sky.png
Resolving imgs.xkcd.com... 151.101.16.67, 2a04:4e42:4::67
Connecting to imgs.xkcd.com|151.101.16.67|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 54636 (53K) [image/png]
Saving to: 'wallpaper'
wallpaper 100%
[==========================================================>]
53.36K --.-KB/s in 0.04s
2018-01-27 21:45:08 (1.41 MB/s) - 'wallpaper' saved [54636/54636]
The -O option means that the downloaded image now has been saved as "wallpaper". Now that you know the name of the image, you can set it as a wallpaper. This varies depending upon which display manager you're using. The most popular are listed below, assuming the image is located at /home/user/wallpaper.
GNOME:
gsettings set org.gnome.desktop.background picture-uri
↪"File:///home/user/wallpaper"
gsettings set org.gnome.desktop.background picture-options
↪scaled
Cinnamon:
gsettings set org.cinnamon.desktop.background picture-uri
↪"file:///home/user/wallpaper"
gsettings set org.cinnamon.desktop.background picture-options
↪scaled
Xfce:
xfconf-query --channel xfce4-desktop --property
↪/backdrop/screen0/monitor0/image-path --set
↪/home/user/wallpaper
You can set your wallpaper now, but you need different images to mix in. Looking at the webpage, there's a "random" button that takes you to a random comic. Searching with grep for "random" returns the following:
user@LJ $: grep random index.html
<li><a href="//c.xkcd.com/random/comic/">Random</a></li>
<li><a href="//c.xkcd.com/random/comic/">Random</a></li>
This is the link to a random comic, and downloading it with wget and reading the result, it looks like the initial comic page. Success!
Now that you've got all the components, let's put them together into a script, replacing www.xkcd.com with the new c.xkcd.com/random/comic/:
#!/bin/bash
wget c.xkcd.com/random/comic/
wget "$(grep "img src=" index.html | grep /comics/ | cut -d\"
↪-f 2 | cut -c 3-)" -O wallpaper
gsettings set org.gnome.desktop.background picture-uri
↪"File:///home/user/wallpaper"
gsettings set org.gnome.desktop.background picture-options
↪scaled
All of this should be familiar except the first line, which designates this as a bash script, and the second wget command. To capture the output of commands into a variable, you use $(). In this case, you're capturing the grepping and cutting process—capturing the final link and then downloading it with wget. When the script is run, the commands inside the bracket are all run producing the image link before wget is called to download it.
There you have it—a simple example of a dynamic wallpaper that you can run anytime you want.
If you want the script to run automatically, you can add a cron job to have cron run it for you. So, edit your cron tab with:
user@LJ $: crontab -e
My script is called "xkcd", and my crontab entry looks like this:
@reboot /bin/bash /home/user/xkcd
This will run the script (located at /home/user/xkcd) using bash, every restart.
The script above shows how to search for images in HTML code and download them. But, you can apply this to any website of your choice—although the HTML code will be different, the underlying concepts remain the same. With that in mind, let's tackle downloading images from Reddit. Why Reddit? Reddit is possibly the largest blog on the internet and the third-most-popular site in the US. It aggregates content from many different communities together onto one site. It does this through use of "subreddits", communities that join together to form Reddit. For the purposes of this article, let's focus on subreddits (or "subs" for short) that primarily deal with images. However, any subreddit, as long as it allows images, can be used in this script.
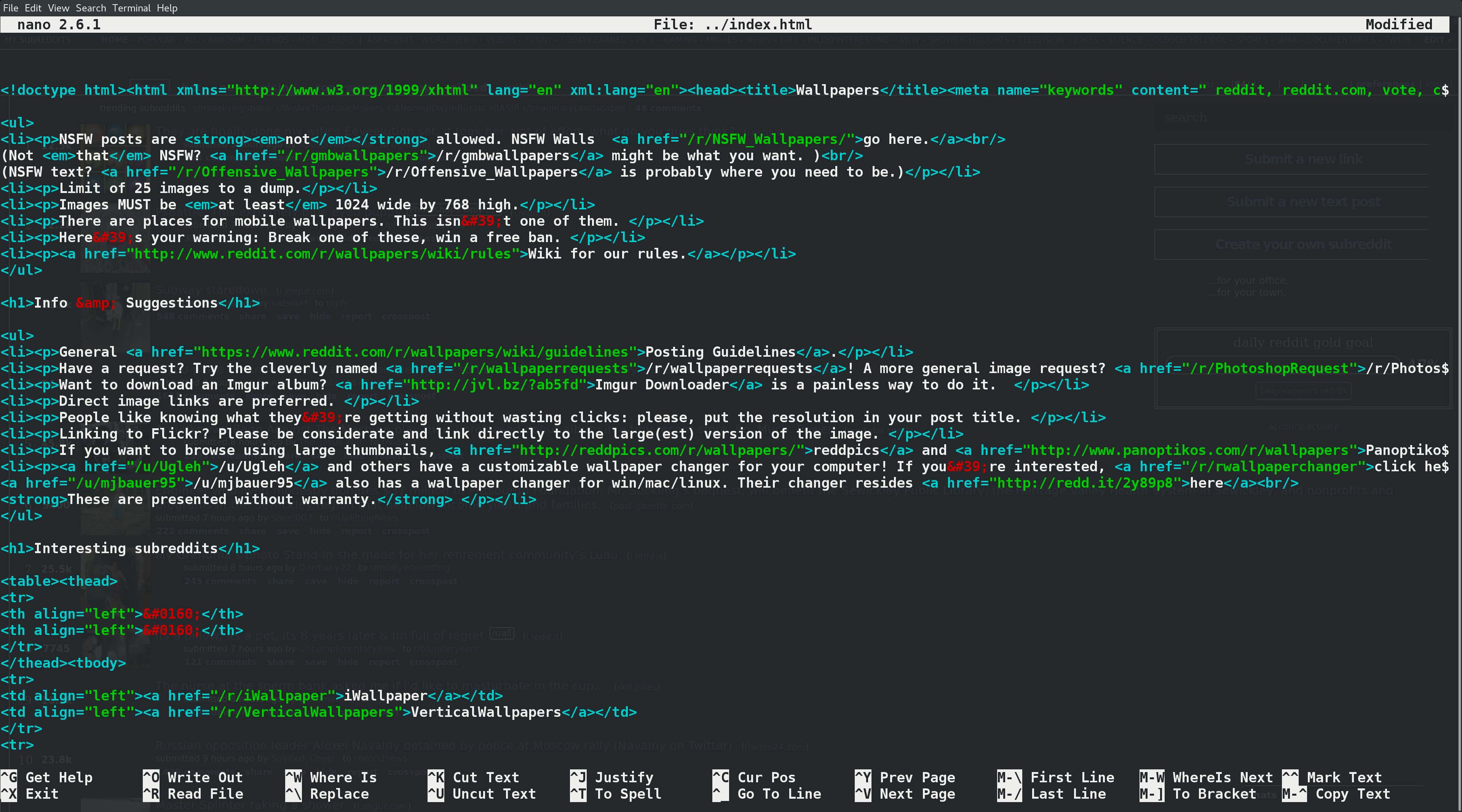
Figure 1. Scraping the Web Made Simple-Analysing Web Pages in a Terminal
Just like the xkcd script, you need to download the web page from a subreddit to analyse it. I'm using reddit.com/r/wallpapers for this example. First, check for images in the HTML:
user@LJ $: wget https://www.reddit.com/r/wallpapers/ && grep
↪"img src=" index.html
--2018-01-28 20:13:39-- https://www.reddit.com/r/wallpapers/
Resolving www.reddit.com... 151.101.17.140
Connecting to www.reddit.com|151.101.17.140|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 27324 (27K) [text/html]
Saving to: 'index.html'
index.html 100%
[==========================================================>]
26.68K --.-KB/s in 0.1s
2018-01-28 20:13:40 (270 KB/s) - 'index.html' saved [169355]
</div></form><div class="bottom"><span class="age">a community
↪for <time title="Thu May 1 16:17:13 2008 UTC"
↪datetime="2008-05-01T16:17:13+00:00">9 years</time></span>
↪....Forever and ever......
--- SNIP ---
All the images have been returned in one long line, because the HTML for the images is also in one long line. You need to split this one long line into the separate image links. Enter Regex.
Regex is short for regular expression, a system used by many programs to allow users to match an expression to a string. It contains wild cards, which are special characters that match certain characters. For example, the * character will match every character. For this example, you want an expression that matches every link in the HTML file. All HTML links have one string in common. They all take the form href="LINK". Let's write a regex expression to match:
href="([^"#]+)"
Let's break it down:
href=" — simply states that the first characters should match these.
() — forms a capture group.
[^] — forms a negated set. The string shouldn't match any of the characters inside.
+ — the string should match one or more of the preceding tokens.
Altogether the regex matches a string that begins href=", doesn't contain any quotation marks or hashtags and finishes with a quotation mark.
This regex can be used with grep like this:
user@LJ $: grep -o -E 'href="([^"#]+)"' index.html
href="/static/opensearch.xml"
href="https://www.reddit.com/r/wallpapers/"
href="//out.reddit.com"
href="//out.reddit.com"
href="//www.redditstatic.com/desktop2x/img/favicon/
↪apple-icon-57x57.png"
--- SNIP ---
The -e options allow for extended regex options, and the -o switch means grep will print only patterns exactly matching and not the whole line. You now have a much more manageable list of links. From there, you can use the same techniques from the first script to extract the links and filter for images. This looks like the following:
user@LJ $: grep -o -E 'href="([^"#]+)"' index.html | cut -d'"'
↪-f2 | sort | uniq | grep -E '.jpg|.png'
https://i.imgur.com/6DO2uqT.png
https://i.imgur.com/Ualn765.png
https://i.imgur.com/UO5ck0M.jpg
https://i.redd.it/s8ngtz6xtnc01.jpg
//www.redditstatic.com/desktop2x/img/favicon/
↪android-icon-192x192.png
//www.redditstatic.com/desktop2x/img/favicon/
↪apple-icon-114x114.png
//www.redditstatic.com/desktop2x/img/favicon/
↪apple-icon-120x120.png
//www.redditstatic.com/desktop2x/img/favicon/
↪apple-icon-144x144.png
//www.redditstatic.com/desktop2x/img/favicon/
↪apple-icon-152x152.png
//www.redditstatic.com/desktop2x/img/favicon/
↪apple-icon-180x180.png
//www.redditstatic.com/desktop2x/img/favicon/
↪apple-icon-57x57.png
//www.redditstatic.com/desktop2x/img/favicon/
↪apple-icon-60x60.png
//www.redditstatic.com/desktop2x/img/favicon/
↪apple-icon-72x72.png
//www.redditstatic.com/desktop2x/img/favicon/
↪apple-icon-76x76.png
//www.redditstatic.com/desktop2x/img/favicon/
↪favicon-16x16.png
//www.redditstatic.com/desktop2x/img/favicon/
↪favicon-32x32.png
//www.redditstatic.com/desktop2x/img/favicon/
↪favicon-96x96.png
The final grep uses regex again to match .jpg or .png. The | character acts as a boolean OR operator.
As you can see, there are four matches for actual images: two .jpgs and two .pngs. The others are Reddit default images, like the logo. Once you remove those images, you'll have a final list of images to set as a wallpaper. The easiest way to remove these images from the list is with sed:
user@LJ $: grep -o -E 'href="([^"#]+)"' index.html | cut -d'"'
↪-f2 | sort | uniq | grep -E '.jpg|.png' | sed /redditstatic/d
https://i.imgur.com/6DO2uqT.png
https://i.imgur.com/Ualn765.png
https://i.imgur.com/UO5ck0M.jpg
https://i.redd.it/s8ngtz6xtnc01.jpg
sed works by matching what's between the two forward slashes. The d on the end tells sed to delete the lines that match the pattern, leaving the image links.
The great thing about sourcing images from Reddit is that every subreddit contains nearly identical HTML; therefore, this small script will work on any subreddit.
To create a script for Reddit, it should be possible to choose from which subreddits you'd like to source images. I've created a directory for my script and placed a file called "links" in the directory with it. This file contains the subreddit links in the following format:
https://www.reddit.com/r/wallpapers
https://www.reddit.com/r/wallpaper
https://www.reddit.com/r/NationalPark
https://www.reddit.com/r/tiltshift
https://www.reddit.com/r/pic
At run time, I have the script read the list and download these subreddits before stripping images from them.
Since you can have only one image at a time as desktop wallpaper, you'll want to narrow down the selection of images to just one. First, however, it's best to have a wide range of images without using a lot of bandwidth. So you'll want to download the web pages for multiple subreddits and strip the image links but not download the images themselves. Then you'll use a random selector to select one image link and download that one to use as a wallpaper.
Finally, if you're downloading lots of subreddit's web pages, the script will become very slow. This is because the script waits for each command to complete before proceeding. To circumvent this, you can fork a command by appending an ampersand (&) character. This creates a new process for the command, "forking" it from the main process (the script).
Here's my fully annotated script:
#!/bin/bash
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
↪# Get the script's current directory
linksFile="links"
mkdir $DIR/downloads
cd $DIR/downloads
# Strip the image links from the html
function parse {
grep -o -E 'href="([^"#]+)"' $1 | cut -d'"' -f2 | sort | uniq
↪| grep -E '.jpg|.png' >> temp
grep -o -E 'href="([^"#]+)"' $2 | cut -d'"' -f2 | sort | uniq
↪| grep -E '.jpg|.png' >> temp
grep -o -E 'href="([^"#]+)"' $3 | cut -d'"' -f2 | sort | uniq
↪| grep -E '.jpg|.png' >> temp
grep -o -E 'href="([^"#]+)"' $4 | cut -d'"' -f2 | sort | uniq
↪| grep -E '.jpg|.png' >> temp
}
# Download the subreddit's webpages
function download {
rname=$( echo $1 | cut -d / -f 5 )
tname=$(echo t.$rname)
rrname=$(echo r.$rname)
cname=$(echo c.$rname)
wget --load-cookies=../cookies.txt -O $rname $1
↪&>/dev/null &
wget --load-cookies=../cookies.txt -O $tname $1/top
↪&>/dev/null &
wget --load-cookies=../cookies.txt -O $rrname $1/rising
↪&>/dev/null &
wget --load-cookies=../cookies.txt -O $cname $1/controversial
↪&>/dev/null &
wait # wait for all forked wget processes to return
parse $rname $tname $rrname $cname
}
# For each line in links file
while read l; do
if [[ $l != *"#"* ]]; then # if line doesn't contain a
↪hashtag (comment)
download $l&
fi
done < ../$linksFile
wait # wait for all forked processes to return
sed -i '/www.redditstatic.com/d' temp # remove reddit pics that
↪exist on most pages from the list
wallpaper=$(shuf -n 1 temp) # select randomly from file and DL
echo $wallpaper >> $DIR/log # save image into log in case
↪we want it later
wget -b $wallpaper -O $DIR/wallpaperpic 1>/dev/null # Download
↪wallpaper image
gsettings set org.gnome.desktop.background picture-uri
↪file://$DIR/wallpaperpic # Set wallpaper (Gnome only!)
rm -r $DIR/downloads # cleanup
Just like before, you can set up a cron job to run the script for you at every reboot or whatever interval you like.
And, there you have it—a fully functional cat-image harvester. May your morning logins be greeted with many furry faces. Now go forth and discover new subreddits to gawk at and new websites to scrape for cool wallpapers.
Patrick Whelan is a first-year student at Edge Hill University in the UK. He is an aspiring developer, blogger and all-round hacker.