Cloud computing is a powerful tool. Learn how cluster computing concepts can be applied to deploy an instant cluster in the cloud.
High-performance computing currently typically uses clusters, but its future is in the cloud. System administrators now find themselves in the middle of a transition period, maintaining old clusters while porting software to cloud environments.
There are many reasons to migrate to the compute cloud. For starters, there is zero upfront cost and no physical hardware to maintain. The cloud is exceptionally reliable, often with better than 99.95% uptime. The cloud provides an extremely convenient environment, as you can create, use, shut down, restart, snapshot and delete cloud instances from the comfort of your web browser. The cloud is also relatively secure—if you trust the cloud provider, of course.
One of the most attractive features of the cloud is dynamic scalability, meaning that one can increase or decrease the amount of resources used in real time. Coupled with the cloud's utility model of pricing, this makes it cost efficient to spin up a cloud instance to perform a task and then shut it down when that task completes.
Early in the learning curve of utilizing the compute cloud, one often creates a snapshot of a cloud instance configured with appropriate software. A typical workflow experience might then be:
Launch a new cloud instance from the snapshot.
ssh in.
Run the software.
Accidentally close the laptop lid, breaking the SSH session.
Reconnect and restart the job using nohup.
scp the output back to the laptop.
At 3:00 am, realize the instance is still running and frantically shut it down.
Life would be much easier if this process were streamlined and automated. Ideally, one simply could submit a job to a software package that automatically launches a cloud instance, executes the job, saves the results and deletes the cloud instance. This vision suggests a project that automatically creates and uses cloud computing resources.
Several open-source projects have a similar trajectory. Unfortunately, the stable ones require one to containerize or hadoopize all application software. This is a fine standard to impose, but if the software already works perfectly well in a cluster, why rework it on a per-application basis for a new environment? A more general solution would be to replicate a cluster environment in the cloud and run the cluster software unmodified. Of course, that cluster should be one that resizes itself, and the software to automate that task had to be written—and everyone knows how automating tasks tends to work (Figure 1).

Figure 1. https://xkcd.com/1319
The central goal of CLuster In the Cloud (CLIC) is to replicate a physical cluster as a virtual cluster in the cloud, so that any application software that's designed for clusters doesn't know the difference. Just like a physical cluster, there are a head node and some compute nodes. However, because of the dynamic scalability of the cloud, the compute nodes are created only when they are needed and are deleted once they no longer are needed.
To ensure the longevity of this project, it must be versatile in as many dimensions as possible. Ideally these include:
Linux distro.
Cloud node architecture.
Location of head node (in cloud or physical).
Cloud service provider.
Job scheduler.
The final goal is to make CLIC easy to install. Cloud computers, being virtual machines, are by nature disposable. It would be undesirable to have to configure the head node manually every time it gets deleted or if one wants to try something different.
In order to understand what building a virtual cluster in the cloud entails, it is worth describing the process. For this purpose, we're using the Google Compute Engine (GCE), as it provides both graphical and API controls. GCE handles a number of the required elements of building a cluster out of the box:
OS installation.
Firewall.
dhcp.
Hostname resolution.
ntp.
Monitoring (via the console).
This leaves the setup task deceptively simple:
SSH keys.
NFS.
Job scheduler (SLURM).
To create a cluster manually, spin up two CentOS instances on GCE, one designated as the head node and the other as the compute node. The first task is to set up passwordless SSH. However, the standard procedure of generating an SSH key pair on the head node and copying the public key to the compute node does not work.
No documentation confirms this, but through experimentation we discovered that there are two layers of SSH key enforcement in GCE: the host OS and GCE itself. In order to install new keys, instead of copying them to the cloud instances, GCE needs to be made aware of them, either via the graphical console or the API. GCE then propagates the keys to the cloud instances.
The next task is to NFS-mount the home directory. Of course, this mounts over users' .ssh directories, breaking passwordless SSH. The solution should have been to add the head node's keys to the head node's .ssh, but this messes up GCE's redundant security. The underlying mechanism for GCE is undocumented and probably subject to change, but to satisfy it, one has to keep NFS from mounting over ~/.ssh. The following script uses mount --bind to access the original ~/.ssh:
mount -t nfs4 -o rw $HEAD_IP:/home /home
mount --bind / /bind-root
for user in `ls /home`; do
mount --bind /bind-root/home/$user/.ssh /home/$user/.ssh
done
The final component is the job scheduler, SLURM. It is built from source using SSL authentication from the instructions at https://slurm.schedmd.com. At this point, one has a functional two-node cluster in the cloud! The CLIC installer automates and generalizes this process.
In designing CLIC, the first structural decision is how to handle job scheduling. One possibility is to make CLIC be the job scheduler. The proposed process of operation is so simple that any dedicated job scheduler would be overpowered:
User submits job.
Node is created.
Job is run on node.
Node is deleted.
Notice that the scheduler doesn't actually do any scheduling. Because an unlimited number of compute nodes are potentially available, one simply can spin up additional compute nodes in a virtual cluster instead of deferring jobs to run on the next available node in a physical cluster. Under this cloud computing paradigm, the scheduler is just a glorified remote execution platform, coming into play only for steps 1 and 3. Why should a heavy-powered suite be required for such a simple task?
It turns out that the job scheduler is required to replicate the cluster environment. A design goal of CLIC is that the cluster software doesn't know the difference between a physical cluster and a CLuster In the Cloud. The scheduler—whether it schedules or not—plays a vital role in this regard by providing a known interface for job submission. Therefore, short of re-implementing an incredibly complex interface, the job scheduler is necessary. We chose SLURM for this purpose because its popularity in cluster computing is increasing, and it can handle changes in node availability.
Now that jobs are submitted with SLURM and slated to be run on GCE, the job of CLIC is to bridge the gap. There are a few ways to go about doing this. A project called SLURM Elastic Computing started to integrate similar functionality into SLURM itself, although this particular project seems to have stalled. CLIC certainly could do something like that and integrate directly into SLURM. However, this would prevent swapping out job schedulers in the future, making it unversatile. Alternatively, it's possible to integrate tightly with the cloud provider, but that often requires the containerization of application software, which goes against the initial design goal of being able to run unmodified. Therefore, CLIC is a standalone dæmon that monitors the SLURM queue for resources needed and manipulates GCE accordingly.
Next, the structure of the cluster must be addressed. Since it is a cluster, it needs a head node and compute nodes. The head node is a running instance with the CLIC dæmon installed on it. Because the number of compute nodes can vary, they collectively take the form of a single image from which CLIC can create them as needed. The compute nodes have mostly the same software as the head node, so the image can simply be taken of an already configured head node.
The CLIC dæmon is the central point of the project. It implements the algorithm that monitors the job queue and manipulates the cloud API to expand and contract the cluster.
The main loop in CLIC collects data on the length of the SLURM queue, the number of nodes sitting idle and the number of nodes that are currently booting. A naive algorithm would be to create as many nodes as jobs that are in the queue, minus the number of idle nodes and the number of nodes currently booting. Alternatively, if the queue length is zero, delete the idle nodes.
This algorithm is naive because GCE instances take 1–2 minutes to allocate resources and boot. The state of the queue when the boot process starts may not be the same as when it ends, often resulting in CLIC overshooting the required adjustment.
Instead of spinning up the same number of nodes as queued jobs, a better approach is to create nodes for half of the queued jobs, rounded up. Similarly, we delete half of the idle nodes, rounded up:
nodesToCreate = ceil(queueLength / 2) - nodesIdle - nodesBooting nodesToDelete = ceil(nodesIdle / 2) when queueLength = 0
Using this method, instead of resizing the virtual cluster to the instantaneous demand of two minutes ago, it approaches that demand geometrically. The benefit is that the size of the cluster converges rapidly to computational power demanded when they differ substantially, but slows down as they approach, thus keeping it from overshooting.
Up to this point in CLIC's description, we assumed that all compute nodes are single CPU machines with 3.75GB of RAM and 10GB hard disks (this is the default instance configuration in GCE). Those specs actually describe a smartphone quite well, but they are inadequate for most cluster applications!
To allow for variability in compute instance architectures, we added fields in CLIC's configuration file for CPUs, memory and disk size, each of which may take multiple values. CLIC then can create nodes for each combination of values, and SLURM can run jobs on the appropriately sized machines.
A minor complication is that SLURM was developed under the assumption that the cluster would remain static. It does clever things that are useful in that context, such as packing, where it runs multiple jobs with small resource demands on larger machines if smaller machines aren't available. However, packing prevents the deletion of large nodes in the virtual cluster.
To illustrate the problem, if the cluster has a single 16-CPU compute node when a 1-CPU job is submitted, then SLURM will run that job on the 16-CPU node, leaving 15 CPUs unutilized. Perhaps additional jobs might be submitted so that a greater portion of that machine is utilized, but there likely will be significant periods of time that it is wastefully sitting mostly empty.
Instead of packing small jobs onto large machines, in a cloud environment, it is better to partition out architectures so that jobs are run only on same-sized machines. This is more economical and allows nodes with unused cores to be deleted.
To implement this, CLIC gives SLURM a partition for each architecture, and CLIC keeps track of each partition separately when creating and deleting nodes. Since there is potentially a large number of partitions, each referred to by a unique name, such as “1cpu10diskstandard”, CLIC generates a job submission plugin written in Lua that places jobs in the best partitions given their requirements.
So far in this description of CLIC, the head node has been in the cloud with all the compute nodes. It's nice to have it in the same aethereal location as the compute nodes, because it can communicate with them over a private low-latency LAN. However, there are several reasons why a physical head node may be more desirable:
If the head node runs 24/7, there is no opportunity for cost savings from dynamic scalability.
Storing results of calculations on a cloud head node can be expensive, and if you don't trust big data companies, unsettling.
Transferring large amounts of data from the cloud all at once is time-consuming.
I already have a web server. Why do I need another?
For these reasons, CLIC also allows for a local head node. Some issues associated with a local head node are trivial to fix. The firewall for GCE has to be modified to allow SLURM traffic through. Additionally, the GCE API has to be installed and authenticated. The installation process differs because an image can't be generated from the head node.
A few things are more complex. First is compute node hostname resolution. When the head node was in the cloud, GCE provided hostname resolution for the compute nodes in the form of a DNS. One could ignore the IP addresses of the nodes completely, referring to them only by name. This becomes a problem when the head node is no longer able to resolve the names of the compute nodes because it can't access GCE's DNS, and the compute nodes can't resolve the hostname of the head node because GCE's DNS isn't aware of it.
To resolve this issue, /etc/hosts on both the head and compute nodes must contain address/name pairings for the cluster. Every time CLIC boots a compute node, it uses the GCE API to obtain the compute node's IP address and adds it to /etc/hosts on the head node. Then it ssh's in to the compute node and adds the head node's address/name pairing there.
Because the head and compute nodes no longer are generated from the same image, the UIDs and GIDs of users don't necessarily match between the head and compute nodes. This is an issue, because NFS identifies users and groups by ID, not by name, resulting in filesystem permission problems. The solution is to change the UIDs and GIDs for users on the compute nodes. CLIC provides a script for this process that is run on compute nodes when they boot up.
Another benefit when the head and compute nodes were in the cloud was that all intra-cluster communication occurred over a private LAN, so unencrypted NFS is just fine. When the head node is separated from the compute nodes by a wide expanse of the dangerous internet, unencrypted anything is really bad. The solution to this issue is to direct all NFS traffic through an SSH tunnel.
CLIC can be added on top of any standard system to enable the creation of a virtual cluster. The cluster can be entirely in the cloud, or the head node can be a local computer and the compute nodes can be in the cloud.
When installing a pure cloud cluster, one needs to generate only a single image, which can serve as both the head and compute nodes.

Figure 2. Pure cloud cluster installation: create a single cloud image with all necessary software, and use this image for the head and compute nodes.
The installation of a hybrid cluster isn't as convenient as the pure cloud cluster, because it's not possible to create a physical head node from a cloud image. After configuring the head and compute node separately, the CLIC installation software syncs the physical head node with the compute node to create a compute node image.
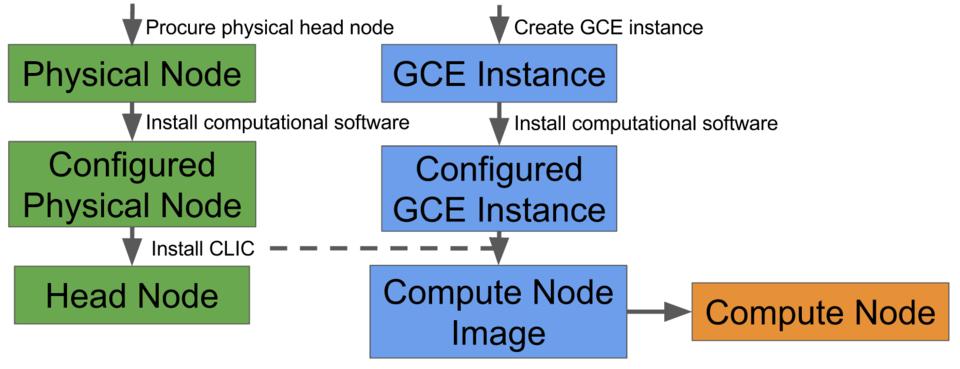
Figure 3. Hybrid cluster installation: the physical head node and cloud compute node are configured separately, and CLIC syncs them.
The CLIC installation code is available at https://github.com/nathanrvance/clic.
Installing CLIC requires only a single command that installs cloud APIs, the CLIC dæmon, SLURM and other cluster software. The user is prompted for local sudo access and cloud API access when needed.
At this point, it's possible to run a stress test on CLIC. A simple test is to submit a random number of sleep X jobs to SLURM every ten minutes, where X is a random value between 500 and 1000 seconds. CLIC automatically spins up needed nodes to accommodate the demand. No jobs waited longer than 12 minutes.

Figure 4. Job Submission Rate and Queue Length
CLIC also shut down nodes that no longer were needed. The total node runtime was 54 hours, including startup and shutdown times. The total job runtime was 41 hours. Therefore, 41 out of 54 hours paid for were spent running jobs, which is an efficiency of 76% for the 193 jobs submitted over four wall-clock hours.

Figure 5. Jobs and Nodes Running
The real test of CLIC is to run unmodified cluster software on it. We installed several computational chemistry engines, such as Gaussian and NWChem, and WebMO, which is a computational chemistry front end that utilizes a cluster environment to submit jobs and retrieve results. These packages were all installed using their standard installation procedures and without any modifications to the software itself. It all just worked. Mission accomplished.
At this point, CLIC is able to run unmodified cluster software on a virtual, dynamic cluster in the cloud. It allows for pure clusters in the cloud or on-demand usage of cloud resources to augment physical hardware.
There is still development opportunity for CLIC. CLIC is currently dependent on GCE and SLURM. CLIC could support a more general and standardized cloud API so that it can support other cloud platforms. It also could generalize job scheduler calls so that users can access a variety of job schedulers. But regardless, CLIC serves as a useful and proven model for deploying a CLuster In the Cloud.