A way to give individuals root for themselves in a world of administrative silos.
I believe the best and worst thing about Linux is its hard distinction between kernel space and user space.
Without that distinction, Linux never would have become the most leveraged operating system in the world. Today, Linux has the largest range of uses for the largest number of users—most of whom have no idea they are using Linux when they search for something on Google or poke at their Android phones. Even Apple stuff wouldn't be what it is (for example, using BSD in its computers) were it not for Linux's success.
Not caring about user space is a feature of Linux kernel development, not a bug. As Linus put it on our 2003 Geek Cruise (www.linuxjournal.com/article/6427), “I only do kernel stuff...I don't know what happens outside the kernel, and I don't much care. What happens inside the kernel I care about.” After Andrew Morton gave me additional schooling on the topic a couple years later on another Geek Cruise (www.linuxjournal.com/article/8664), I wrote:
Kernel space is where the Linux species lives. User space is where Linux gets put to use, along with a lot of other natural building materials. The division between kernel space and user space is similar to the division between natural materials and stuff humans make out of those materials.
A natural outcome of this distinction, however, is for Linux folks to stay relatively small as a community while the world outside depends more on Linux every second. So, in hope that we can enlarge our number a bit, I want to point us toward two new things. One is already hot, and the other could be.
The first is blockchain (https://en.wikipedia.org/wiki/Block_chain_%28database%29), made famous as the distributed ledger used by Bitcoin, but useful for countless other purposes as well. At the time of this writing, interest in blockchain is trending toward the vertical (https://www.google.com/trends/explore#q=blockchain).
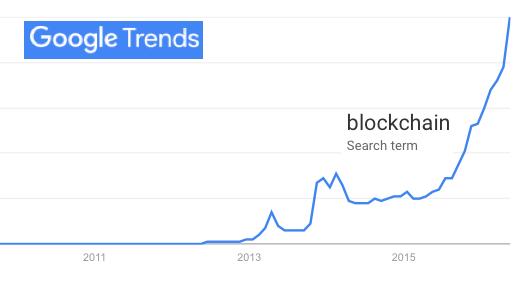
Figure 1. Google Trends for Blockchain
The second is self-sovereign identity. To explain that, let me ask who and what you are.
If your answers come from your employer, your doctor, the Department of Motor Vehicles, Facebook, Twitter or Google, they are each administrative identifiers: entries in namespaces each of those organizations control, entirely for their own convenience. As Timothy Ruff of Evernym (evernym.com) explains, “You don't exist for them. Only your identifier does.” It's the dependent variable. The independent variable—the one controlling the identifier—is the organization.
If your answer comes from your self, we have a wide-open area for a new development category—one where, finally, we can be set fully free in the connected world.
The first person to explain this, as far as I know, was Devon Loffreto (https://twitter.com/nzn). He wrote “What is 'Sovereign Source Authority'?” in February 2012, on his blog, The Moxy Tongue (www.moxytongue.com/2012/02/what-is-sovereign-source-authority.html). In “Self-Sovereign Identity” (www.moxytongue.com/2016/02/self-sovereign-identity.html), published in February 2016, he writes:
Self-Sovereign Identity must emit directly from an individual human life, and not from within an administrative mechanism...self-Sovereign Identity references every individual human identity as the origin of source authority. A self-Sovereign identity produces an administrative trail of data relations that begin and resolve to individual humans. Every individual human may possess a self-Sovereign identity, and no person or abstraction of any type created may alter this innate human Right. A self-Sovereign identity is the root of all participation as a valued social being within human societies of any type.
To put this in Linux terms, only the individual has root for his or her own source identity. In the physical world, this is a casual thing. For example, my own portfolio of identifiers includes:
David Allen Searls, which my parents named me.
David Searls, the name I tend to use when I suspect official records are involved.
Dave, which is what most of my relatives and old friends call me.
Doc, which is what most people call me.
As the sovereign source authority over the use of those, I can jump from one to another in different contexts and get along pretty well. But, that's in the physical world. In the virtual one, it gets much more complicated. In addition to all the above, I am @dsearls (my Twitter handle) and dsearls (my handle in many other net-based services). I am also burdened by having my ability to relate contained within hundreds of different silos, each with their own logins and passwords.
You can get a sense of how bad this is by checking the list of logins and passwords on your browser. On Firefox alone, I have hundreds of them. Many are defunct (since my collection dates back to Netscape days), but I would guess that I still have working logins to hundreds of companies I need to deal with from time to time. For all of them, I'm the dependent variable. It's not the other way around. Even the term “user” testifies to the subordinate dependency that has become a primary fact of life in the connected world.
Today, the only easy way to bridge namespaces is via the compromised convenience of “Log in with Facebook” or “Log in with Twitter”. In both of those cases, each of us is even less ourselves or in any kind of personal control over how we are known (if we wish to be knowable at all) to other entities in the connected world.
What we have needed from the start are personal systems for instantiating our sovereign selves and choosing how to reveal and protect ourselves when dealing with others in the connected world. For lack of that ability, we are deep in a metastasized mess that Shoshana Zuboff calls “surveillance capitalism” (www.faz.net/aktuell/feuilleton/debatten/the-digital-debate/shoshana-zuboff-secrets-of-surveillance-capitalism-14103616.html?printPagedArticle=true#pageIndex_2), which she says is:
...unimaginable outside the inscrutable high velocity circuits of Google's digital universe, whose signature feature is the Internet and its successors. While the world is riveted by the showdown between Apple and the FBI, the real truth is that the surveillance capabilities being developed by surveillance capitalists are the envy of every state security agency.
Then she asks, “How can we protect ourselves from its invasive power?”
I suggest self-sovereign identity. I believe it is only there that we have both safety from unwelcome surveillance and an Archimedean place to stand in the world. From that place, we can assert full agency in our dealings with others in society, politics and business.
I came to this provisional conclusion during ID2020 (www.id2020.org), a gathering at the UN on May. It was gratifying to see Devon Loffreto there, since he's the guy who got the sovereign ball rolling in 2013. Here's what I wrote about it at the time (blogs.harvard.edu/doc/2013/10/14/iiw-challenge-1-sovereign-identity-in-the-great-silo-forest), with pointers to Devon's earlier posts (such as one sourced above).
Here are three for the field's canon:
“Self-Sovereign Identity” by Devon Loffreto: www.moxytongue.com/2016/02/self-sovereign-identity.html.
“System or Human First” by Devon Loffreto: www.moxytongue.com/2016/05/system-or-human.html.
“The Path to Self-Sovereign Identity” by Christopher Allen: www.lifewithalacrity.com/2016/04/the-path-to-self-soverereign-identity.html.
A one-pager from Evernym (evernym.com), digi.me (https://get.digi.me), iRespond (irespond.com) and Respect Network (https://www.respectnetwork.com) also was circulated there, contrasting administrative identity (which it calls the “current model”) with the self-sovereign one. In it is the graphic shown in Figure 2.
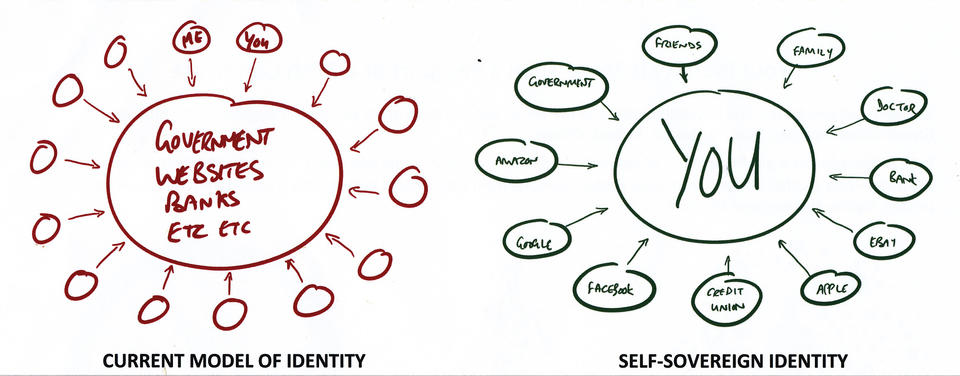
Figure 2. Current Model of Identity vs. Self-Sovereign Identity
The platform for this is Sovrin, explained as a “Fully open-source, attribute-based, sovereign identity graph platform on an advanced, dedicated, permissioned, distributed ledger” (evernym.com/technology). There's a white paper too: evernym.com/assets/doc/Identity-System-Essentials.pdf?v=167284fd65. The code is called plenum (https://github.com/evernym/plenum), and it's at GitHub.
Here—and places like it—we can do for user space what we've done for the last quarter century for kernel space.