The first time I heard about hash tables was after taking a compilers course during my BSc. The truth is, I was not able to understand and appreciate their usefulness fully back then. Now that I know more about hash tables, I decided to write about them so others will see their importance as well.
Hash tables can be implemented in any programming language, including Awk. However, the choice of programming language is not the most important thing compared to other critical choices. Hash tables are used in compilers, databases, caching, associative arrays and so on. Hash tables are one of the most important data structures in computer science.
The problem that will serve as an example for this article is finding out how many words from one text file appear in another text file. All programs in this article use a text file (Pride and Prejudice) for populating the hash table. Another text file (The Adventures of Tom Sawyer) will be used for testing the performance of the hash table. You can download both text files from Project Gutenberg.
The following output shows how many words each file contains:
$ wc AofTS.txt
9206 73845 421884 AofTS.txt
$ wc PandP.txt
13426 124589 717573 PandP.txt
As you can see, both text files are relatively large, which is good for benchmarking. Your real-life hash tables may not be as big. In order to remove various control characters, as well as punctuation marks and numbers, both text files were processed further:
$ strings PandP.txt > temp.INPUT
$ awk '{for (i = 1; i <= NF; i++) print $i}' temp.INPUT > new.INPUT
$ cat new.INPUT | tr -cd '![a-zA-Z]\n' > INPUT
$ strings AofTS.txt > temp.CHECK
$ awk '{for (i = 1; i <= NF; i++) print $i}' temp.CHECK > new.CHECK
$ cat new.CHECK | tr -cd '![a-zA-Z]\n' > empty.CHECK
$ sed '/!/d' empty.CHECK > temp.CHECK
$ sed '/^\s*$/d' temp.CHECK > CHECK
The reason for simplifying both files is that some control characters made the C programs crash. As the purpose of this article is to showcase hash tables, I decided to simplify the input instead of spending time trying to figure out the problem and modifying the C code.
After constructing the hash table using the first file (INPUT) as input, the second one (CHECK) will be used for testing the hash table. This will be the actual use of the hash table.
Let me start with the definition of a hash table. A hash table is a data structure that stores one or more key and value pairs. A hash table can store keys of any type.
A hash table uses a hash function to compute an index into an array of buckets or slots, from which the correct value can be found. Ideally, the hash function will assign each key to a unique bucket. Unfortunately, this rarely happens. In practice, more than one of the keys will hash to the same bucket. The most important characteristic of a hash table is the number of buckets. The number of buckets is used by the hashing function. The second most important characteristic is the hash function used. The most crucial feature of the hash function is that it should produce a uniform distribution of the hash values.
You can say that the search time is now O(n/k), where n is the number of keys, and k is the size of the hash array. Although the improvement looks small, you should realize that for a hash array with 20 buckets, the search time is now 20 times smaller.
It is important for the hash function to behave consistently and output the same hash value for identical keys. A collision happens when two keys are hashing to the same index—that's not an unusual situation. There are many ways to deal with a collision.
A good solution is to use separate chaining. The hash table is an array of pointers, each one pointing to the next key with the same hash value. When a collision occurs, the key will be inserted in constant time to the head of a linked list. The problem now is that when you have to search a hash value for a given key, you will have to search the whole linked list for this key. In the worst case, you might need to traverse the entire linked list—that's the main reason the linked list should be moderately small, giving the requirement for a large number of buckets.
As you can imagine, resolving collisions involves some kind of linear search; therefore, you need a hash function that minimizes collisions as much as possible. Other techniques for resolving collisions include open addressing, Robin Hood hashing and 2-choice hashing.
Hash tables are good at the following:
In a hash table with the “correct” number of buckets, the average cost for each lookup is independent of the number of elements stored in the table.
Hash tables are particularly efficient when the maximum number of entries can be predicted in advance so that the bucket array can be allocated once with the optimum size and never resized.
If the set of key-value pairs is fixed and known ahead of time (so insertions and deletions are not allowed), you can reduce the average lookup cost by a careful choice of the hash function, bucket table size and internal data structures.
Hash tables also have some disadvantages:
They are not good at keeping sorted data. It is not efficient to use a hash table if you want your data sorted.
Hash tables are not effective when the number of entries is very small, because despite the fact that operations on a hash table take constant time on average, the cost of a good hash function can be significantly higher than the inner loop of the lookup algorithm for a sequential list or search tree.
For certain string processing applications, such as spell-checking, hash tables may be less efficient than trees or finite automata.
Although the average cost per operation is constant and fairly small, the cost of a single operation may be fairly high. In particular, if the hash table uses dynamic resizing, inserting or deleting a key may, once in a while, take time proportional to the number of entries. This can be a serious drawback in applications where you want to get results fast.
Hash tables become quite inefficient when there are many collisions.
As I'm sure you understand, not every problem can be solved equally well with the help of a hash table. You always should consider and examine all your options before deciding what to use.
Figure 1 shows a simple hash table with keys and values shown. The hash function is the modulo 10 function; therefore, ten buckets are needed because only ten results can come from a modulo 10 calculation. Having only ten buckets is not considered very good, especially if the number of values grows large, but it is fine for illustrative purposes.
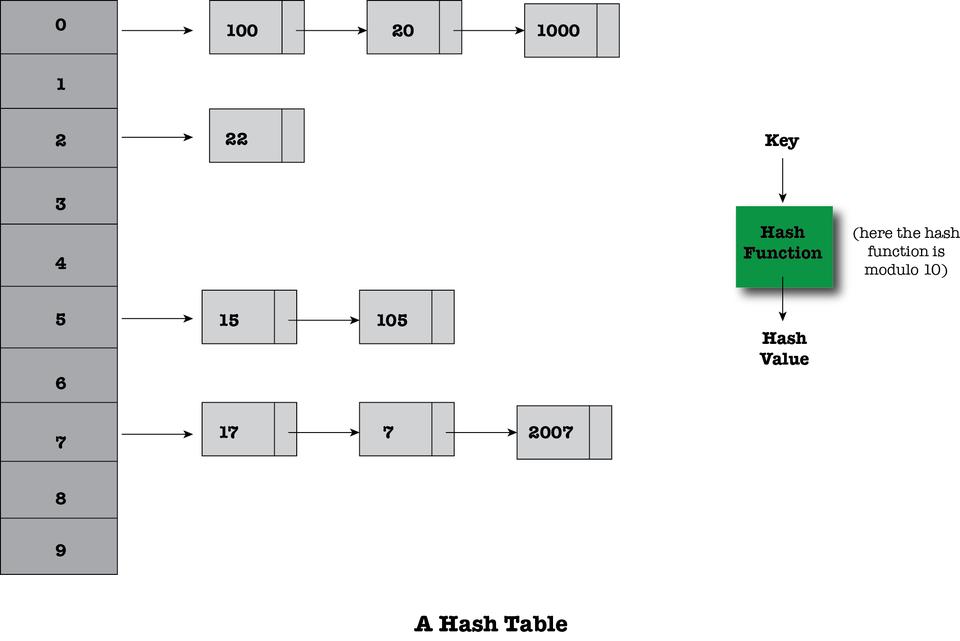
Figure 1. A Simple Hash Table
To summarize, a hash table should follow these principles:
Do not have too many buckets, just as many as needed.
It is good for the hash function to take into account as much information provided by the key as possible. This is not a trivial task.
The hash function must be able to hash similar keys to different hash values.
Each bucket should have the same number of keys or at least as close to being equal as possible (this is a very desirable property).
Following some principles will make collisions less likely. First, you should use a prime number of buckets. Second, the bigger the size of the array, the smaller the probability of collisions. Finally, you should make sure that the hash function is smart enough to distribute its return values as evenly as possible.
The main operations on a hash table are insertion, deletion and lookup. You use the hash value to determine where in the hash table to store a key. Later, you use the same hash function to determine where in the hash table to search for a given key.
Once the hash table is populated, searching is the same as doing an insertion. You hash the data you are searching for, go to that place in the array, look down the list that starts from that location, and see if what you are looking for is in the list. The number of steps is O(1). The worst-case search time for a hash table is O(n), which can happen when all keys are stored in the same bucket. Nevertheless, the probability of that happening is so small that both the best and average cases are considered to be O(1).
You can find many hash table implementations on the Internet or in several books on the topic. The tricky part is using the right number of buckets and choosing an efficient hash function that will distribute values as uniformly as possible. A distribution that is not uniform definitely will increase the number of collisions and the cost of resolving them.
The first implementation will be stored in a file named ht1.c. The implementation uses separate chaining, because separate chaining is a reasonable choice. For simplicity, both input and output filenames are hard-coded inside the program. After finishing with the input and building the hash table, the program starts reading the second file, word by word, and starts checking whether a word can be found in the hash table.
Listing 1 shows the full C code of the ht1.c file.
The second implementation will be stored in a file named ht2.c. This implementation uses separate chaining as well. Most of the C code is the same as in ht1.c except for the hash function. The C code for the modified hash function is the following:
int hash(char *str, int tablesize)
{
int sum = 0;
// Is it a valid string?
if(str == NULL)
{
return -1;
}
// Calculate the sum of all characters in the string
for( ; *str; str++)
{
sum += *str;
}
// Return the sum mod the table size
return (sum % tablesize);
}
What this hash function does better than the other one is that it takes into account all the letters of the string instead of just the first one. Therefore, the produced number, which corresponds to the position of the key in the hash table, is bigger, and this results in being able to take advantage of hash tables with a larger number of buckets.
The presented benchmarks are far from accurate or scientific. They are just an indication of what is better, what works and what doesn't and so on. Keep in mind that finding the optimal hash table size is not always easy.
All programs were compiled as follows:
$ gcc -Wall program.c -o program
The trusty time command produced the following output after executing ht1 with four different hash table sizes:
$ grep define ht1.c #define TABLESIZE 101 $ time ./ht1 The hash table is ready! Found 59843 words in the hash table! real 0m0.401s user 0m0.395s sys 0m0.004s $ grep define ht1.c #define TABLESIZE 10 $ time ./ht1 The hash table is ready! Found 59843 words in the hash table! real 0m0.794s user 0m0.788s sys 0m0.004s $ grep define ht1.c #define TABLESIZE 1001 $ time ./ht1 The hash table is ready! Found 59843 words in the hash table! real 0m0.410s user 0m0.404s sys 0m0.004s $ grep define ht1.c #define TABLESIZE 5 $ time ./ht1 The hash table is ready! Found 59843 words in the hash table! real 0m1.454s user 0m1.447s sys 0m0.004s
Figure 2 shows a plot of the execution times from the four different values of the TABLESIZE variable of the ht1.c program. The bad thing about ht1.c is that its performance with a hash table of 101 buckets is almost the same as with one with 1,001 buckets!
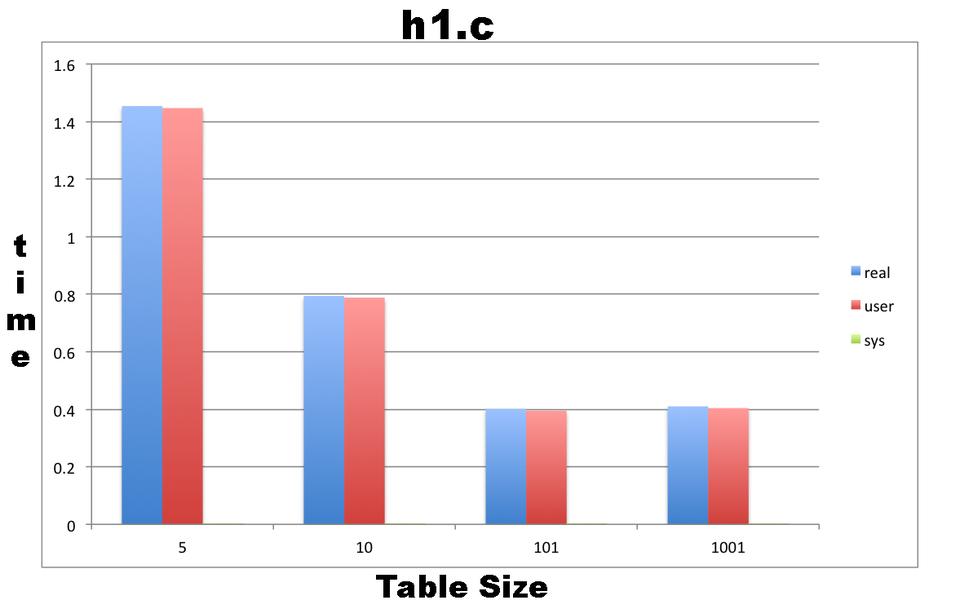
Figure 2. Execution Times from the Four Different Vales of the TABLESIZE Variable of the ht1.c Program
Next, here are the results from the execution of the ht2.c program:
$ grep define ht2.c #define TABLESIZE 19 $ time ./ht2 INPUT CHECK The hash table is ready! Found 59843 words in the hash table! real 0m0.439s user 0m0.434s sys 0m0.003s $ grep define ht2.c #define TABLESIZE 97 $ time ./ht2 INPUT CHECK The hash table is ready! Found 59843 words in the hash table! real 0m0.116s user 0m0.111s sys 0m0.003s $ grep define ht2.c #define TABLESIZE 277 $ time ./ht2 INPUT CHECK The hash table is ready! Found 59843 words in the hash table! real 0m0.072s user 0m0.067s sys 0m0.003s $ grep define ht2.c #define TABLESIZE 997 $ time ./ht2 INPUT CHECK The hash table is ready! Found 59843 words in the hash table! real 0m0.051s user 0m0.044s sys 0m0.003s $ grep define ht2.c #define TABLESIZE 22397 $ time ./ht2 INPUT CHECK The hash table is ready! Found 59843 words in the hash table! real 0m0.049s user 0m0.044s sys 0m0.003s
Figure 3 shows a plot of the execution times from the five different values of the TABLESIZE variable used in the ht2.c program. All hash table sizes are prime numbers. The reason for using prime numbers is that they behave better with the modulo operation. This is because a prime number has no positive divisors other than one and itself. As a result, the product of a prime number with another integer has fewer positive divisors than the product of a non-prime number with another integer.
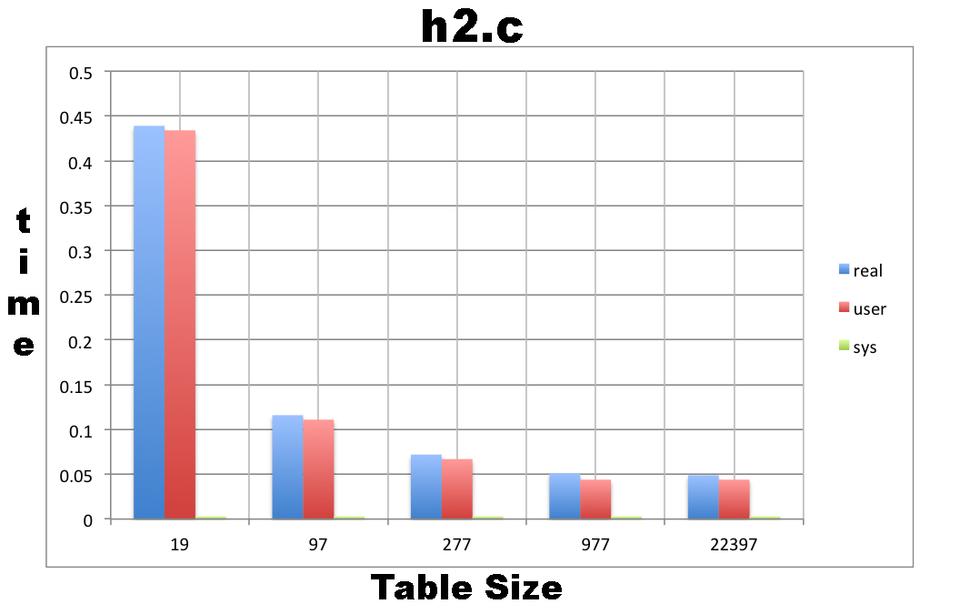
Figure 3. A Plot of the Execution Times from the Five Different Values of the TABLESIZE Variable Used in the ht2.c Program
As you can see, the new hash function performs much better than the hash function found in ht1.c. As a result, the use of more buckets greatly improves the performance of the hash table. Nevertheless, as long as the words in the text files are finite, there is no point in using more buckets than the number of unique words in the input file.
It is useful to examine the distribution of keys in the hash table for the ht2 implementation using two different number of buckets. The following C function prints the number of keys in each bucket:
void printHashTable(node *table[], const unsigned int tablesize)
{
node *e;
int i;
int length = tablesize;
printf("Printing a hash table with %d buckets.\n", length);
for(i = 0; i<length; i++)
{
// printf("Bucket: %d\n", i);
// Get the first node of the linked list
// for the given bucket.
e = table[i];
int n = 0;
if (e == NULL)
{
// printf("Null bucket %d\n", i);
}
else
{
while( e != NULL )
{
n++;
e = e->next;
}
}
printf("Bucket %d has %d keys\n", i, n);
}
}
Figure 4 shows the number of keys in each bucket for two hash tables: one with 97 buckets and the other with 997 buckets. The hash table with 997 buckets appears to follow a pattern on how it fills its buckets, whereas the hash table with the 97 buckets is more evenly distributed. Nevertheless, the bigger hash table has a lower number of keys in each bucket which is what you really want because less keys in each linked list means less time searching it.
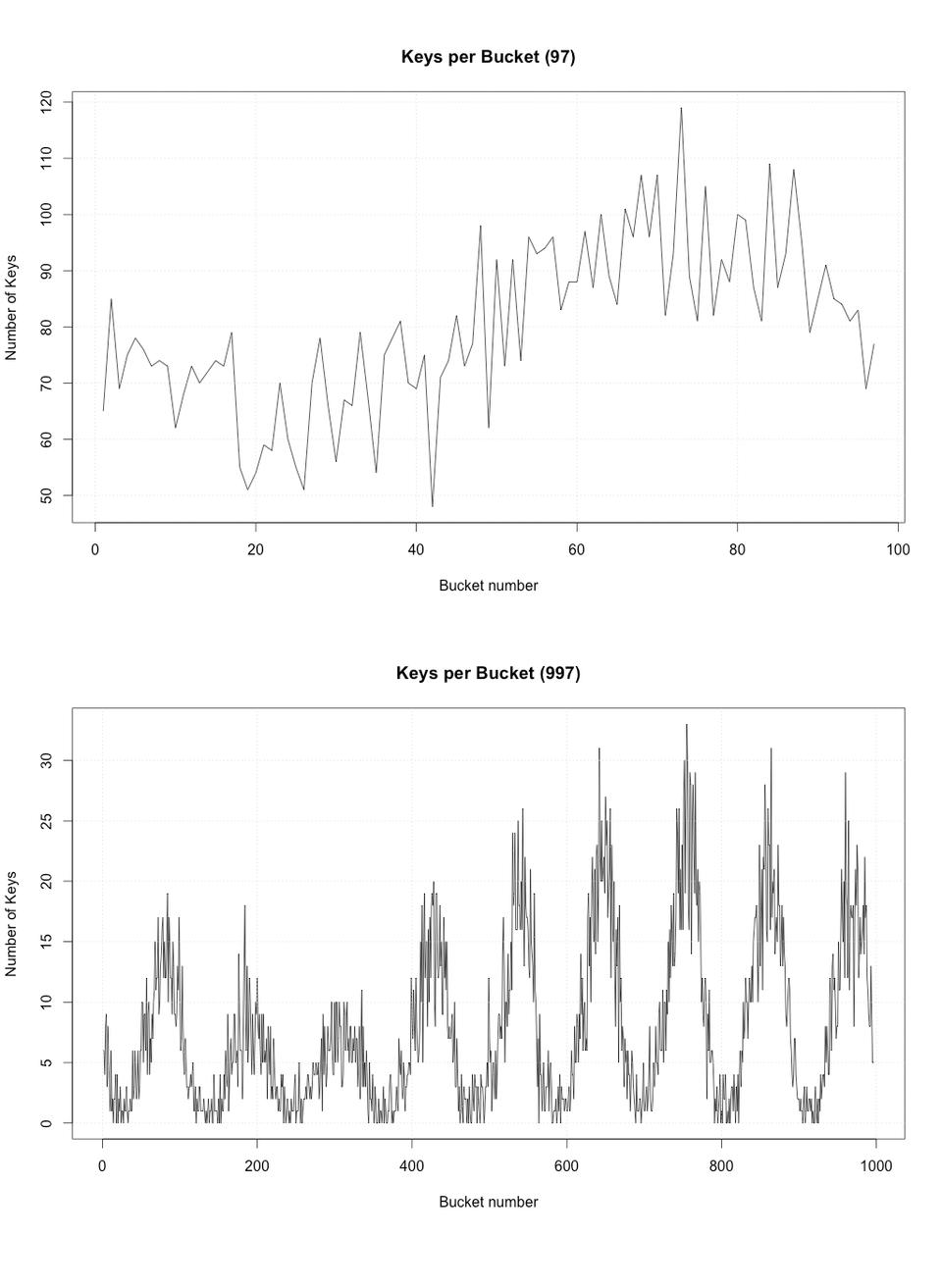
Figure 4. The Number of Keys in Each Bucket for Two Hash Tables with Different Numbers of Buckets
Hash tables are an important part of computer science and programming. I hope this article helps you understand their importance and clarifies some things about them.