When you run a program as setuid, it runs with all the permissions of that user. And if the program spawns new processes, they inherit the same permissions. Not so with filesystem capabilities. When you run a program with a set of capabilities, the processes it spawns do not have those capabilities by default; they must be given explicitly.
This seemed unintuitive to Christoph Lameter, who posted a patch to change capability inheritance to match the behavior of setuid inheritance. This turned out to inspire some controversy.
For one thing, filesystem capabilities never were defined fully in the POSIX standard and appear only in a draft version of POSIX that later was withdrawn, so there can't really be any discussion of whether one form of capabilities is “more compliant” than another.
There are other problems, such as the need to make sure that any changes to capabilities don't break existing code and the need to make sure that any ultimate solution remains secure.
One problem with Christoph's idea was that it tied capability inheritance to the file itself, but as Serge Hallyn pointed out, capabilities were tied to both the file and the user executing the file. Ultimately, Christoph decided to adapt his code to that constraint, introducing a new capability that would list the inheritable capabilities available for the user to apply to a given file.
Yalin Wang recently made an abortive effort to have /proc/stat list all CPUs on a given system, not just the on-line ones. This would be a very useful feature, because many modern systems bring CPUs on- and off-line at a rapid pace. Often the number of CPUs actually in use is less important than the number available to be used.
He posted a patch to change /proc/stat accordingly, and David Rientjes pointed out that the /sys/devices/cpu file would be a better location for this. Andrew Morton also pointed out that /proc/cpuinfo would be a good location for this kind of data as well. So, there definitely was some support for Yalin's idea.
Unfortunately, it turned out that some existing code in the Android kernel relied on the current behavior of those files—specifically desiring the number of on-line CPUs as opposed to the total number of CPUs on the system. With an existing user dependent on the existing behavior, it became a much harder sell to get the change into the kernel. Yalin would have to show a real need as opposed to just a sensible convenience, so his patch went nowhere.
John Stultz has been maintaining some timekeeping test patches on GitHub for several years now, and he finally wanted to get them into the kernel, so he could stop porting them forward continually. The test would do a variety of things, involving changing the system time in some way designed to induce a problem. He asked what he should do to make the patches acceptable to the kernel folks.
There were a bunch of generally supportive comments from folks like Richard Chochran and Shuah Khan, but Shuah requested some fairly invasive changes that would tie John's code to other testing code in the kernel. John said he'd be happy to do that if it was required, but that one of his goals had been to keep the test files isolated, so any one of them could run independently of anything else on the system. In light of that, Shuah withdrew her suggestion.
Overall, it's not a controversial set of patches, and they'll undoubtedly get into the kernel soon.
One problem with making backups that guarantee filesystem consistency is that files on the system may change while they're being backed up. There are various ways to prevent this, but if another process already has an open file descriptor for a file, backup software just has to wait or risk copying an inconsistent version of the file.
Namjae Jeon posted some patches to address this problem by implementing file freezing. This would allow backup software to block writes to a given file temporarily, even if that file already had been opened by another process.
In addition to backup software, other tools like defragmenting software would benefit from Namjae's patches by preventing any changes to a file that was being reorganized on disk.
As Jan Kara pointed out, however, Namjae's code had some potential race conditions as well as other technical problems. Dave Chinner described the code as “terribly racy”.
It's not clear what will happen with these patches. They seem to offer features that folks want, but the race conditions need to be resolved, and the code needs to be clean and clear enough that future fixes and enhancements will not be too likely to introduce new problems.
Although the title might sound like some new-fangled tech jargon, I'm actually referring to a fairly simple Android app called "Unclouded." If you're a Dropbox user who also has things stored in Google Drive, Unclouded is a single interface to multiple file syncing backends. Sure, it's not horribly difficult to open multiple apps to work with your cloud-based files, but it can be inconvenient.

Unclouded also has some neat features like locating duplicate files taking up precious space in your cloud storage, and it can do previews for most media types. Unfortunately, the free version limits the number of accounts you can connect to, and it also disables useful things like sharing, moving, renaming and deleting files. Thankfully, the premium features are a few bucks at the most, and even without them, the app is elegant and useful. Check it out today at the Google Play Store: https://play.google.com/store/apps/details?id=com.cgollner.unclouded.
If you're a cord cutter (and a nerd), you most likely have a server or two dedicated to serving and possibly retrieving videos from the Internet. Programs like Kodi and Plex are awesome for media delivery; however, there's more to a complete system than just playing the videos. Although the ethical and legal ramifications vary from country to country (and conscious to conscious), the unfortunate truth is that programs like Sickbeard and NZBDrone can be difficult to install and maintain.
The folks over at www.htpcbeginner.com created a set of Bash scripts designed to make the installation of media-related HTPC software painless. If applied to a freshly installed Ubuntu machine, the AtoMiC Toolkit installs the appropriate dependencies and software for most of the media-related software out there.

Like I always say when this topic comes up, using torrents and Usenet to download television episodes may not be legal where you live. Regardless of where you live, it might be ethically wrong to download them. Even if you just use programs like Sickbeard to organize the television shows you record with your own DVR, however, the AtoMiC Toolkit is a great way to get them up and running in short order. Check out the scripts at https://github.com/htpcBeginner/AtoMiC-ToolKit and learn how to install them at www.htpcbeginner.com/atomic-toolkit.
Although the technology itself has been around for a while, RSS is still the way most people consume Web content. When Google Reader was ended a few years back, there was a scramble to find the perfect alternative. You may remember my series of articles on Tiny Tiny RSS, Comma Feed and a handful of other Google Reader wannabes. I don't mention standalone RSS readers very often, however, because I don't like being tied to a single computer for reading Web sites. That's where syncing comes into play.
Vienna (www.vienna-rss.org) is an open-source RSS feed reader for OS X. Because it's written in Cocoa, it's available only for Macs. There are many alternatives for Linux and Windows, but the RSS reader options for OS X are surprisingly few.
The interface for Vienna is about like what you'd expect from an RSS reader. The view is customizable, and you can open complete stories in tabs to see the original Web site if you so desire. The real beauty of Vienna, however, is under the hood.
The Open Reader API (rss-sync.github.io/Open-Reader-API/rssconsensus) is a protocol that aims to be vendor-neutral and completely open. Google Reader used to be the back end that everyone used for RSS feed syncing, and since its demise, people sort of re-invented the wheel in their own way. The Open Reader API is one solution that may catch on. It's already supported by BazQux (bazqux.com) and FeedHQ (feedhq.org), and although adoption has been slow, hopefully it becomes the standard protocol for RSS syncing.
Luckily, if you're an OS X user, you can take advantage of the protocol right now with Vienna. Thanks to its great interface and open attitude, Vienna gets this month's Editors' Choice award. I think it's the first time we've given a non-Linux program the Editors' Choice honor, but its great interface and commitment to open standards makes us proud.
CERN is the European Laboratory for Particle Physics. It has been in the news quite a bit lately with the discovery of the Higgs Boson at the Large Hadron Collider. Something that many people may not know is that it also has a long tradition of developing software for scientific use. The HTML document format and the first browser both were developed there as a way of using rich documents that could include links between many different sources of information. It was so useful, it ended up sparking the World Wide Web. Along with such widespread software, CERN has been responsible for quite a bit of scientific software, especially physics software.
In this article, I take a look at a fairly large group of modules and libraries called the Physics Analysis Workstation (PAW, paw.web.cern.ch/paw). PAW contains several thousand subroutines and programs that are written in FORTRAN, C and even some assembly language code, which is built on top of a library called the CERN Program Library (CERNLIB).
You can download and install the code from the source located at the main Web site if you have any special needs, but considering the long list of required external libraries, I suggest you avoid that if possible. Packages should be available for your distribution. For Debian-based distros, you can install everything you need with the command:
sudo apt-get install paw
PAW also includes a large series of graphing and data visualization routines to help in data analysis. Sometimes you need to see what your data looks like in order to figure out what further analysis you need to investigate.
PAW actually is an interactive system, where you can apply commands against your data set. The original interface was a command-line one, but it now has collected several other interfaces that you can try out. If you open a terminal, type the command paw and press Enter, you are presented with a question as to which terminal type you want to use (Figure 1). The default is to use type 1, which opens an HIGZ graphic window where your plots will be displayed (Figure 2). If you are using PAW on a remote machine, you probably will want to use a different type. You can get a list by typing ?. For a regular xterm, enter 7879.
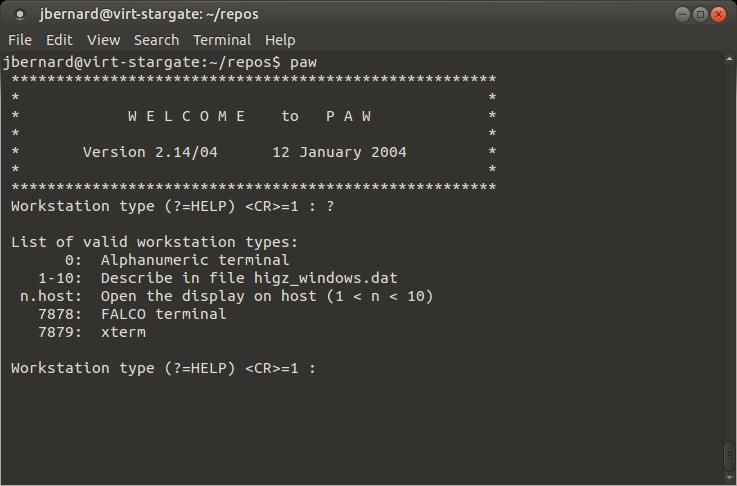
Figure 1. You can select the terminal type to use when you start PAW.
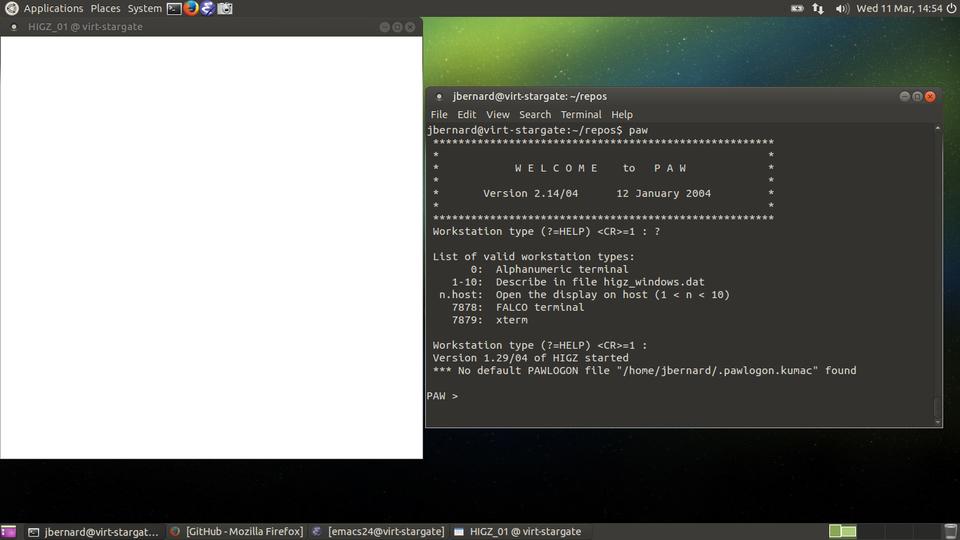
Figure 2. The default is to open a graphics window to draw your plots into, along with a command interface.
Once everything has finished loading, you are presented with a prompt that looks like this:
PAW >
Now you can start typing commands and doing data analysis. But, what commands can you use? Luckily, PAW includes a help system within the program that you can access by typing the help command, which pops up a list of topics.
Commands in PAW are grouped together in a tree structure, with the top-most level being the topics that pop up when you start the help system. There is also quite a bit of documentation available on the main Web site, including tutorials and a very large FAQ.
Because PAW is used for data analysis, let's start with what kinds of data you can use. PAW has three main data types: VECTORS, HISTOGRAMS and NTUPLES. VECTORS store arrays of reals or integers. PAW can handle up to three dimensions, or indexes, for these VECTORS. They can be manipulated by the group of VECTOR commands. Commands in PAW are not case-sensitive, but in most documentation, they are shown in uppercase. You also can use abbreviations for commands, as long as they can be matched uniquely to the full command text. So, you can create a new VECTOR of 20 elements with the command:
VECTOR/CREATE vec1(20)
This new VECTOR is named “vec1”. Then you can add elements to your new vector with this command:
VECTOR/INPUT vec1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
The command takes a vector name and a list of values to add. This is fine if you are dealing with just a small set of data. If you have larger data sets stored in files, you can use the command VECTOR/READ. This command takes a filename, and it also can take several other options, like the format of the elements, and loads the data into the given VECTORS.
The optional format string is similar to those used in reading and writing data in FORTRAN code, so a refresher course may be a good idea if it has been some time since you have used FORTRAN.
You can output data to a file with the inverse VECTOR/WRITE command.
To visualize your data, use the VECTOR/DRAW command. The options available allow you to select whether to draw a histogram, a smooth curve or a bar chart. You also can draw this visualization over the top of another graph.
You can get a list of all of the VECTORS that have been created with the VECTOR/LIST command, and you can clean up unneeded data with the VECTOR/DELETE command.
Once you have loaded your data and taken a look at it, you may have an idea of how the different parts are related to each other. You can use the VECTOR/FIT command to take a function, defined by you with a subroutine, and try to fit the data to it. You also can include a set of associated errors when issuing the command.
The HISTOGRAM group of commands within PAW gives you a larger selection of plotting and analysis tools to apply to your data. The commands are broken down into subgroups that give you commands to create histograms, 2D plots and apply histogram operations to histograms. You can use the GET_VECT and PUT_VECT command subgroups to interact with the VECTOR object that you created above. You also can use FUNCTION commands to create functions that are used in commands that do data fitting, among other areas.
The NTUPLE group of commands are used to manipulate ntuple objects. Ntuples essentially are lists of lists, and you can think of them as matrices. In the PAW documentation, each row is called an event, and each column is called a variable. There are functions to merge data together or make cuts of subsets. Ntuples have their own plot commands that allow you to plot different variables against each other in various forms. If you have lots of data to deal with, you can use the CHAIN command to chain together multiple ntuples to create data sets of essentially unlimited size.
Although PAW is no longer under active development, there still is more than enough really useful code here to keep any scientist busy. If you are doing any work involving data analysis or modeling, especially in C or FORTRAN, it would be well worth your time to do a quick search of the available modules and subroutines in PAW to see if there is anything you can use to make your work progress more quickly. I cover only a very small portion of the functionality available in this article, so be sure to do a bit of a deeper dive to see what you can mine for your own work.
In last month's issue, I talked about Linux permissions (see “It's Better to Ask Forgiveness...” in the May 2015 UpFront section). I could have covered SUID, GUID and sticky bit in the same article, but it seemed like a lot to cover in one sitting. So in this article, I describe the special permissions on a Linux system. Where standard permissions are fairly intuitive, the special permissions don't make a lot of sense at first. Once you understand what they do, however, they're really not too complicated.
But There's No Room for More Permissions!
When you learned to set read, write and execute bits on files and folders, you probably realized that you used all the available “spots” for permissions. So when manipulating special permissions, you sort of re-use existing permission bits. It functions just like any other permission attribute, but they're represented a bit oddly.
Every section of the permissions string (user, group, other) has an additional “special” permission bit that can be set just like rwx. The indication for whether those bits are set is shown on the execute section of the string. For example:
If the SUID (Set User ID) permission is set, the execute bit on the user section shows an s instead of an x.
If the GUID (Group User ID) permission is set, the execute bit on the group section shows an s instead of an x.
If the sticky bit is set, the execute bit on the other section shows a t instead of an x.
Confused yet? Here are a few examples:
-rwsrw-rw- — SUID is set on this file.
drw-rwsrw- — GUID is set on this folder.
drw-rw-r-t — sticky bit is set on this folder.
-rwSr--r-- — SUID is set on this file, but the user execute bit is not.
Note that in the last example the S is uppercase. That's the way you can tell whether the execute bit underneath is set. If the SUID bit is lowercase, it means the execute bit is set. If it's uppercase, it means the SUID bit is set, but the executable bit is not.
What Do They Do?
Unlike standard permissions, special permissions change the way files and folders function, as opposed to controlling access. They also function differently depending on whether they're assigned to files or folders. Let's take a look at them one at a time.
SUID: the SUID bit is applied to executable programs. Once it is set, the program executes with the permissions and abilities of the user who owns the file. As you can imagine, this can be an enormous security risk! If a file is owned by root and has the SUID bit set, anyone who executes it has the same permissions as the root user. As scary as it sounds, there are a few valid use cases for such things. One perfect example is the ping program. In order to access the network hardware required to ping hosts, a user needs to have root access to system. In order for all users to be able to use ping, it's set with the SUID bit, and everyone can execute it with the same system permission that root has. Check it out on your system by typing ls -l /bin/ping. You should see the SUID bit set!
Setting the SUID bit on folders has no effect.
GUID: the GUID set on executable files has a similar effect to SUID, except that instead of using the permissions of the user who owns the file, it executes with the permissions of the group membership. This isn't used very often, but in certain multi-user environments, it might be desirable.
Mainly, GUID is used on a folder. If the GUID bit is set on a folder, files created inside that folder inherit the same group membership of the folder itself. This is particularly useful in group collaborations. Normally when someone creates a file, it has the group membership of that user's primary group. Inside a GUID folder, the user still owns the file, but the group membership is set automatically so others in the group can access the files.
Sticky bit: first off, I have no idea why the sticky bit is represented by a t instead of an s. I've searched high and low, and asked many people. No one seems to know. Maybe a Linux Journal reader knows the answer and will enlighten me. (If so, I'll include it in the Letters to the Editor section.) Anyway, the sticky bit is another special permission that is used on folders. In fact, it has no effect at all if it's set on a file.
Folders that have the sticky bit set add a layer of protection for files created within them. Normally in a folder accessible by multiple people, anyone can delete anyone else's files. (Even if they don't have write access to the files!) With the sticky bit set, only the user who owns the file can delete it. It seems like a subtle thing, but when you consider a folder like the /tmp folder on a multi-user Linux system, you can see how important the sticky bit can be! In fact, if it weren't for the sticky bit, the /tmp folder on your system would be like the Wild Wild West, and nefarious gunslingers could delete other people's files willy nilly. You can see the sticky bit set on your system by typing ls -l / | grep tmp.
Assigning Special Permissions
Applying the special permissions to a file or folder is exactly like assigning regular permissions. You use the chmod tool—for example:
chmod u+s file.txt — adds the SUID permission to file.txt.
chmod g-s file.txt — removes the GUID permission from file.txt.
chmod o+t folder — adds the sticky bit to the “folder” directory.
Special permissions can be assigned right alongside regular permissions as well, so things like this are perfectly fine:
chmod ug+rw,u+s,ugo-x file.txt
And just like standard permissions, it's possible (and often preferable) to assign special permissions using octal notation. In order to do that, you use the fourth field. When assigning permissions like this:
chmod 755 file.txt
there's a fourth field that if left off, is assumed to be zero. So this is actually the same as the above example:
chmod 0755 file.txt
That preceding zero is the field that assigns special permissions. If you leave it off, it's assumed to be zero, and no special permissions are assigned. Knowing it's there, however, should make it fairly easy to understand how to use it. If you read last month's article on permissions that included understanding octal notation, just apply that concept to special permissions. Figure 1 shows how it breaks down.
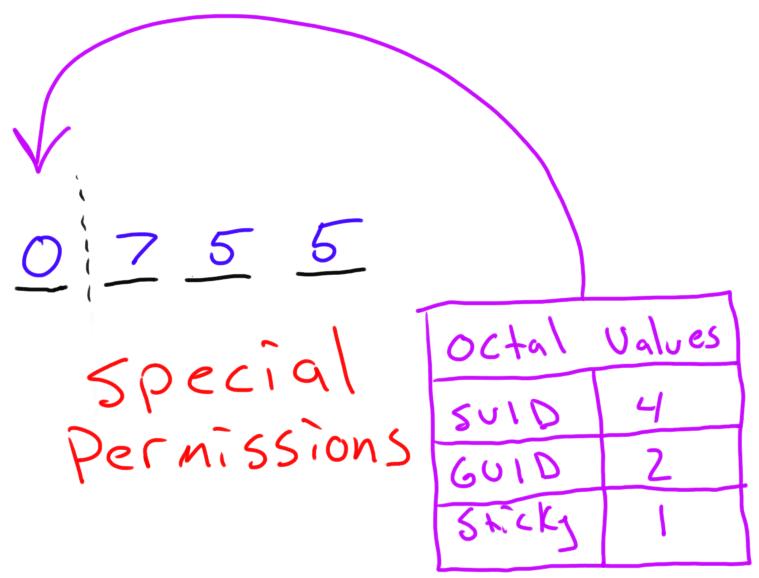
Figure 1. Octal Notation
So in order to assign a folder read/write access for user and groups along with the GUID bit, you would type:
chmod 2770 foldername
And, the resulting permission string (seen by typing ls -l) would show the following (note the lowercase s— remember what that means?):
drwxrws--- foldername
Just like standard permissions, if you want to set multiple special permissions, you just add the values. In order to set SUID and sticky bit, you would set the fourth octal field to 5. Usually, only a single special permission is set on any particular file or folder, but with octal notation, you have the option to set them in any way you see fit.
Hopefully these two articles clear up any misconceptions about Linux permissions. More complicated access controls are available with ACLs, but for most use cases, the standard permission strings are all you need to control access to files and folders on your system.
For to be free is not merely to cast off one's chains, but to live in a way that respects and enhances the freedom of others.
—Nelson Mandela
For the things we have to learn before we can do them, we learn by doing them.
—Aristotle
Words are a heavy thing...they weigh you down. If birds talked, they couldn't fly.
—Sy Rosen
You don't become great by trying to be great. You become great by wanting to do something, and then doing it so hard that you become great in the process.
—Randall Munroe
It's not the hours you put in your work that counts, it's the work you put in the hours.
—Sam Ewing