LUCI4HPC is a lightweight, user-friendly high-performance computer cluster installation and management tool. It offers a graphical Web-based control panel and is fully customizable.
Today's computational needs in diverse fields cannot be met by a single computer. Such areas include weather forecasting, astronomy, aerodynamics simulations for cars, material sciences and computational drug design. This makes it necessary to combine multiple computers into one system, a so-called computer cluster, to obtain the required computational power.
The software described in this article is designed for a Beowulf-style cluster. Such a cluster commonly consists of consumer-grade machines and allows for parallel high-performance computing. The system is managed by a head node and accessed via a login node. The actual work is performed by multiple compute nodes. The individual nodes are connected through an internal network. The head and login node need an additional external network connection, while the compute nodes often use an additional high-throughput, low-latency connection between them, such as InfiniBand.
This rather complex setup requires special software, which offers tools to install and manage such a system easily. The software presented in this article—LUCI4HPC, an acronym for lightweight user-friendly cluster installer for high performance computing—is such a tool.
The aim is to facilitate the maintenance of small in-house clusters, mainly used by research institutions, in order to lower the dependency on shared external systems. The main focus of LUCI4HPC is to be lightweight in terms of resource usage to leave as much of the computational power as possible for the actual calculations and to be user-friendly, which is achieved by a graphical Web-based control panel for the management of the system.
LUCI4HPC focuses only on essential features in order not to burden the user with many unnecessary options so that the system can be made operational quickly with just a few clicks.
In this article, we provide an overview of the LUCI4HPC software as well as briefly explain the installation and use. You can find a more detailed installation and usage guide in the manual on the LUCI4HPC Web site (see Resources). Figure 1 shows an overview of the recommended hardware setup.
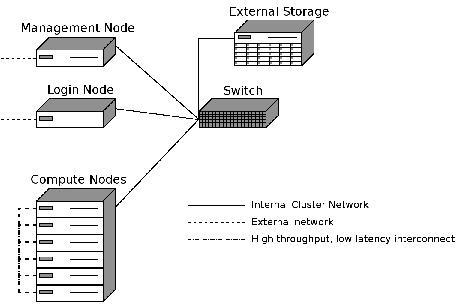
Figure 1. Recommended Hardware Setup for a Cluster Running LUCI4HPC
The current beta version of LUCI4HPC comes in a self-extracting binary package and supports Ubuntu Linux. Execute the binary on the head node, with an already installed operating system, to trigger the installation process. During the installation process, you have to answer a series of questions concerning the setup and configuration of the cluster. These questions include the external and internal IP addresses of the head node, including the IP range for the internal network, the name of the cluster as well as the desired time zone and keyboard layout for the installation of the other nodes.
The installation script offers predefined default values extracted from the operating system for most of these configuration options. The install script performs all necessary steps in order to have a fully functional head node. After the installation, you need to acquire a free-of-charge license on the LUCI4HPC Web site and place it in the license folder. After that, the cluster is ready, and you can add login and compute nodes.
It is very easy to add a node. Connect the node to the internal network of the cluster and set it to boot over this network connection. All subsequent steps can be performed via the Web-based control panel. The node is recognized as a candidate and is visible in the control panel. There you can define the type (login, compute, other) and name of the node. Click on the Save button to start the automatic installation of Ubuntu Linux and the client program on the node.
Currently, the software distinguishes three types of nodes: namely login, compute and other. A login node is a computer with an internal and an external connection, and it allows the users to access the cluster. This is separated from the head node in order to prevent user errors from interfering with the cluster system. Because scripts that use up all the memory or processing time may affect the LUCI4HPC programs, a compute node performs the actual calculation and is therefore composed out of potent hardware. The type “other” is a special case, which designates a node with an assigned internal IP address but where the LUCI4HPC software does not automatically install an operating system. This is useful when you want to connect, for example, a storage server to the cluster, where an internal connection is preferred for performance reasons, but that already has an operating system installed. The candidate system has the advantage that many nodes can be turned on at the same time and that you can later decide from the comfort of your office on the type of each node.
An important part of a cluster software is the scheduler, which manages the assignment of the resources and the execution of the job on the various nodes. LUCI4HPC comes with a fully integrated job scheduler, which also is configurable via the Web-based control panel.
The control panel uses HTTPS, and you can log in with the user name and password of the user that has the user ID 1000. It is, therefore, very easy and convenient to change the login credentials—just change the credentials of that user on the head node. After login, you'll see a cluster overview on the first page. Figure 2 shows a screenshot of this overview.
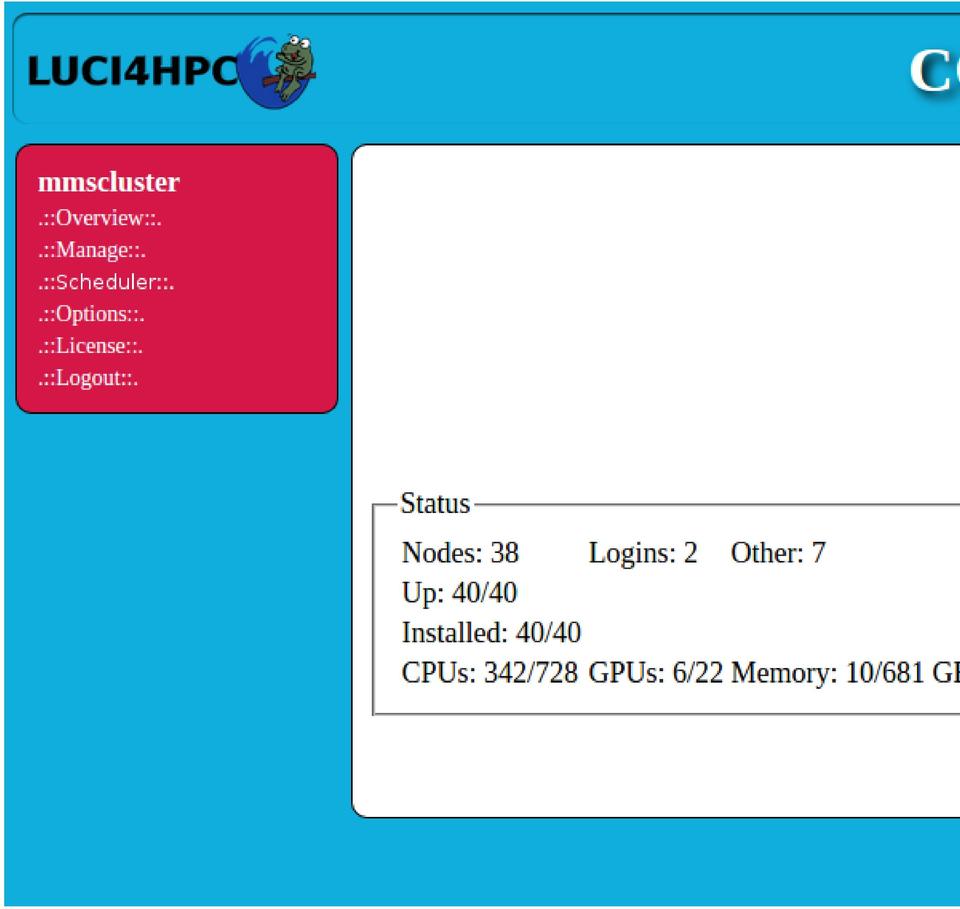
Figure 2. LUCI4HPC Web-Based Control Panel, Cluster Overview Page
This overview features the friendly computer icon called Clusterboy, which shows a thumbs up if everything is working properly and a thumbs down if there is a problem within the cluster, such as a failed node. This allows you to assess the status of the cluster immediately. Furthermore, the overview shows how many nodes of each type are in the cluster, how many of them are operational and installed, as well as the total and currently used amount of CPUs, GPUs and memory. The information on the currently used amount of resources is directly taken from the scheduler.
The navigation menu on the right-hand side of the control panel is used to access the different pages. The management page shows a list of all nodes with their corresponding MAC and IP addresses as well as the hostname separated into categories depending on their type. The top category shows the nodes that are marked as down, which means that they have not sent a heartbeat in the last two minutes. Click on the “details” link next to a node to access the configuration page. The uptime and the load as well as the used and total amount of resources are listed there. Additionally, some configuration options can be changed, such as the hostname, the IP address and the type of the node, and it also can be marked for re-installation. Changing the IP address requires a reboot of the node in order to take effect, which is not done automatically.
The scheduler page displays a list of all current jobs in the cluster, as well as whether they are running or queuing. Here you have the option of deleting jobs.
The queue tab allows you to define new queues. Nodes can be added to a queue very easily. Click on the “details” link next to a queue to get a list of nodes assigned to it as well as a list of currently unassigned nodes. Unassigned nodes can be assigned to a queue, and nodes assigned to a queue can be removed from it to become an unassigned node. Additionally, a queue can have a fair use limit; it can be restricted to a specific group ID, and you can choose between three different scheduling methods. These methods are “fill”, which fills up the nodes one after another; “spread”, which assigns a new job to the least-used node and thus performs a simple load balancing; and finally, “full”, which assigns a job to an empty node. This method is used when several jobs cannot coexist on the same node.
There also is a VIP system. This system gives temporary priority access to a user when, for example, a deadline has to be met. VIP users always are on the top of the queue, and their job is executed as soon as the necessary resources become available. Normally, the scheduler assigns a weight to each job based on the amount of requested resources and the submission time. This weight determines the queuing order.
Finally, the options page allows you to change configuration options of the cluster system, determined during the installation. In general, everything that can be done in the control panel also can be done by modifying the configuration scripts and issuing a reload command.
With the current beta version, a few tasks cannot be done with the control panel. These include adding new users and packages as well as customizing the installation scripts. In order to add a user to the cluster, add the user to the head node as you normally would add a user under Linux. Issue a reload command to the nodes via the LUCI4HPC command-line tool, and then the nodes will synchronize the user and group files from the head node. Thus, the user becomes known to the entire cluster.
Installing new packages on the nodes is equally easy. As the current version supports Ubuntu Linux, it also supports the Ubuntu package management system. In order to install a package on all nodes as well as all future nodes, a package name is added to the additional_packages file in the LUCI4HPC configuration folder. During the startup or installation process, or after a reload command, the nodes install all packages listed in this file automatically.
The installation process of LUCI4HPC is handled with a preseed file for the Ubuntu installer as well as pre- and post-installation shell scripts. These shell scripts, as well as the preseed file, are customizable. They support so-called LUCI4HPC variables defined by a #. The variables allow the scripts to access the cluster options, such as the IP of the head node or the IP and hostname of the node where the script is executed. Therefore, it is possible to write a generic script that uses the IP address of the node it runs on through these variables without defining it for each node separately.
There are special installation scripts for GPU and InfiniBand drivers that are executed only when the appropriate hardware is found on the node. The installation procedures for these hardware components should be placed in these files.
Because of the possibility to change the installation shell scripts and to use configuration options directly from the cluster system in these scripts, you can very easily adapt the installation to your specific needs. This can be used, for example, for the automated installation of drivers for specific hardware or the automatic setup of specific software packages needed for your work.
For the users, most of this is hidden. As a user, you log in to the login node and use the programs lqsub to submit a job to the cluster, lqdel to remove one of your jobs and lqstat to view your current jobs and their status.
The following gives a more technical overview of how LUCI4HPC works in the background.
LUCI4HPC consists of a main program, which runs on the head node, as well as client programs, one for each node type, which run on the nodes. The main program starts multiple processes that represent the LUCI4HPC services. These services communicate via shared memory. Some services can use multiple threads in order to increase their throughput. The services are responsible for managing the cluster, and they provide basic network functionality, such as DHCP and DNS. All parts of LUCI4HPC were written from scratch in C/C++. The only third-party library used is OpenSSL. Besides a DNS and a DHCP service, there also is a TFTP service that is required for the PXE boot process.
A heartbeat service is used to monitor the nodes and check whether they are up or down as well as to gather information, such as the current load. The previously described scheduler also is realized through a service, which means that it can access the information directly from other services, such as the heartbeat in the shared memory. This prevents it from sending jobs to nodes that are down. Additionally, other services, such as the control panel, can access information easily on the current jobs.
A package cache is available, which minimizes the use of the external network connection. If a package is requested by one node, it is downloaded from the Ubuntu repository and placed in the cache such that subsequent requests from other nodes can download the package directly from it. The synchronization of the user files is handled by a separate service. Additionally, the LUCI4HPC command-line tool is used to execute commands on multiple nodes simultaneously. This is realized through a so-called execution service. Some services use standard protocols, such as DNS, DHCP, TFTP and HTTPS for their network communication. For other services, new custom protocols were designed to meet specific needs.
In conclusion, the software presented here is designed to offer an easy and quick way to install and manage a small high-performance cluster. Such in-house clusters offer more possibilities for tailoring the hardware and the installed programs and libraries to your specific needs.
The approach taken for LUCI4HPC to write everything from scratch guarantees that all components fit perfectly together without any format or communication protocol mismatches. This allows for better customization and better performance.
Note that the software currently is in the beta stage. You can download it from the Web site free of charge after registration. You are welcome to test it and provide feedback in the forum. We hope that it helps smaller institutions maintain an in-house cluster, as computational methods are becoming more and more important.