Linus Torvalds doesn't just make whatever changes he wants to the kernel. Sometimes he goes through the normal procedure of sending code to the relevant maintainers. Recently he sent a patch to Al Viro, trying to speed up the VFS by migrating some data out of SELinux and into the inode data structure.
Linus also went on a brief tirade about security features, and how some of them ended up slowing down performance by 50%, before he and Al fixed it. He and Casey Schaufler (the Smack maintainer) had a bit of a dispute over that. Casey said security folks cared a lot about performance and had to deal with hostile tirades like Linus' all the time, and so were motivated to do better.
Once upon a time, 32-bit kernels were so cool. Nowadays, they are scorned with derisive sneers. Linus Torvalds recently remarked, “anybody who runs a 32-bit kernel with 16GB of RAM doesn't even understand how flawed and stupid that is.”
However, some popular distributions still ship with 32-bit kernels by default, and Pierre-Loup A. Griffais recently pointed out that this was causing huge slowdowns for unsuspecting users.
The problem is bad enough that Rik van Riel suggested giving 32-bit kernels a hard limit of 8 or 12GB of RAM, regardless of how much physical RAM was present on a given system. He added that the kernel also should print a friendly warning “to inform users they should upgrade to a 64-bit kernel to enjoy the use of all of their memory.”
Regardless of this patch, the problem with distributions may persist. As H. Peter Anvin put it, “We kernel guys have been asking the distros to ship 64-bit kernels even in their 32-bit distros for many years.”
Linus Torvalds went on vacation and temporarily lost the ability to make tarball releases of new kernel versions. He updated his git tree, but he apologized for the lack of tarballs. He also speculated that maybe nobody even used the tarballs anymore, now that git existed.
However, Randy Dunlap and Mikael Pettersson immediately replied that they did indeed rely on the tarball method. And, Linus reassured them that he'd keep putting out tarballs for the moment.
Nathan Zimmer posted a patch to parallelize RAM initialization. Typically during bootup, RAM is initialized by a single CPU, before any other CPUs are started up. On Nathan's system, this caused boot times of more than an hour. With his patch, the CPUs would all be brought up first, and then RAM could be initialized by all of them together, over much less time.
Originally, he made it a configuration option, but Greg Kroah-Hartman said there was no reason for that—just make it an intrinsic feature. Clearly no one would choose to configure a slower boot time.
Now that Google Reader is officially gone, most folks have settled on a replacement of some sort. In fact, a few months ago I even went through the process of installing Tiny Tiny RSS as a viable and powerful replacement. At the time, there was only one feature I sorely missed, the “next unread blog” link. Approximately three days before Google Reader shut down for good, I found the holy grail of RSS readers: CommaFeed.
CommaFeed is an open-source project written in Java. It's offered as a free Web-based solution at https://www.commafeed.com. Although the interface is similar to Google Reader, it feels slightly stripped down. Thankfully, it provides a bookmarkable link that will take you to your next unread RSS entry. That feature is the single most important, and difficult to find, RSS reader feature I need.
CommaFeed unfortunately doesn't have a really good mobile interface, and it's lacking features in its Android app, but improvements are being made on both fronts. I must admit, however, that even more important than the “next unread blog” link feature, is the ability to download the source code from GitHub and compile CommaFeed for self-hosting (https://github.com/Athou/commafeed). I don't ever want to get “Google Reader'ed” again. Hosting is complicated, because it's a Java application, but the instructions on the GitHub site make it fairly painless. I recommend trying out https://www.commafeed.com before compiling and self-hosting, because CommaFeed's interface might not be for everyone.
If anyone understands the importance of a good text editor, it's a Linux user stuck on Windows. Sure, Microsoft supplies Notepad and Wordpad, but neither really feels like the powerful sort of text editor a Linux user expects. Enter Notepad++.

Notepad++ provides features like line numbering, syntax highlighting and tabbed file editing. If those seem like ordinary features that should be included in any text editor worth its salt, well, you're right. Notepad++ is fully open source, and it is the preferred simple text editor on Windows. It's certainly not a full IDE, but all the developers I know have it installed if they use Windows. Give it a try at notepad-plus-plus.org.
For some reason, Google seems to dislike Google Drive users who prefer Linux. I find this particularly strange, since Google's Chrome OS is based on Linux. Thankfully, the folks over at Insync not only provide Linux support for Google Drive syncing, they do it with style.
Insync is a commercial, proprietary application that installs natively in Linux (https://www.insynchq.com). It offers selective sync, integration with several file managers and a nice tray icon showing sync activity. The coolest feature, however, is the seamless conversion from Google Docs format to LibreOffice format. You can edit your Google Drive documents with the native LibreOffice application, and then it automatically will sync to the cloud in the Web-based Google Docs format! I've tried only a few documents, but in my limited testing, the conversion and sync have been perfect.

Insync has a 15-day free trial and a one-time cost of $9.99. Packages are available for Ubuntu, Fedora, MEPIS and even an unofficial build for Arch Linux. Now that version 1.0 has been released, Insync is available for anyone to download. Due to its native Linux support and super-cool conversion/sync ability, Insync earns this month's Editors' Choice award.
My daughters love the movie Pitch Perfect. I suspect our XBMC has played it more than 100 times, and I'm not exaggerating. Whether or not you enjoy young-adult movies about singing competitions and cartoon-like projectile vomiting, I'll admit it's a pretty fun movie. The question my girls ask me most often is about the audio-mixing software the protagonist uses to make her “sick beats”.
Although Anna Kendrick uses a Macintosh in the movie, and the software's name is obscured or changed in close-ups, it's easy to tell the software she uses is Mixxx. The cool part for me is that while indeed Mixxx works on OS X, it's an open-source application that works natively in Linux as well. That means, in the eyes of my daughters, Linux is now super-cool.
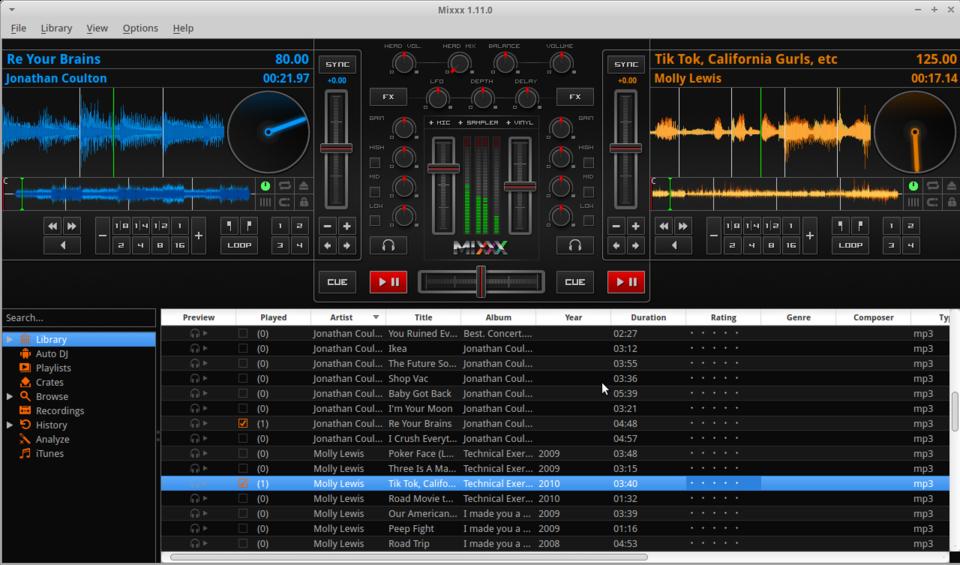
Mixxx is an editing package with incredible visual tools (www.mixxx.org). It's designed to “mix” several songs or rhythm tracks and export a completed song. The very nice GUI makes mixing audio easy to understand, and the interface itself is apparently cool enough for Hollywood. So whether you want to make your own “wicked tracks” or join an a cappella group, Mixxx is just the tool for you. Also, I recommend watching Pitch Perfect, one or two of those XBMC viewings might have been my own!
Don't forget to participate in the 2013 Readers' Choice Awards!
Cast your votes at www.linuxjournal.com/rc13.
Voting ends September 22, 2013. The results will be published in the December 2013 issue of LJ.
As always in experimental science, you need to analyze the data you collect to see what it's telling you about the world. In the beginning stages, you usually need to be able to do some graphical analysis to get an overall view of any trends being revealed by your experiment. Once you get to the point of having a model you want to test, you then need to run some statistical tests to see how well your model fits the data. It always is more convenient to learn one tool rather than two. To this end, there is the package called SciDAVis (Scientific Data Analysis and Visualization, scidavis.sourceforge.net).
SciDAVis started life as a fork of QtiPlot. It has moved quite a bit from the original codebase with the addition of several new features and changes to the underlying data structures. The functionality it provides is similar to commercial programs like Origin and SigmaPlot. It also is similar to another open-source program called LabPlot. In fact, beginning in 2008, these two projects started working together on a common back end while continuing with their own front ends and their own feature sets. In this article, I take a quick look at some of the things you can do with SciDAVis for your own data analysis tasks.
First, you need to install SciDAVis. Most distributions should have a package available. In Debian-based distributions, you can install it with:
sudo apt-get install scidavis
Binaries also are available for Mac OS X. If binaries aren't available, you can download the source tarball and build it specifically for your system. You need to have the Qt libraries installed, because the interface is built using them.
When you first start SciDAVis, you get an empty project and an empty data table with two columns of numeric values (Figure 1). Selecting a column displays the details of that column in a window on the right-hand side. Selecting the description tab lets you change the name of the column, as well as add a comment describing what the column represents. The type tab lets you change what kind of data you can enter for this column from numeric to text, month names, day names or full dates. You also can set the format of the data type for each column.
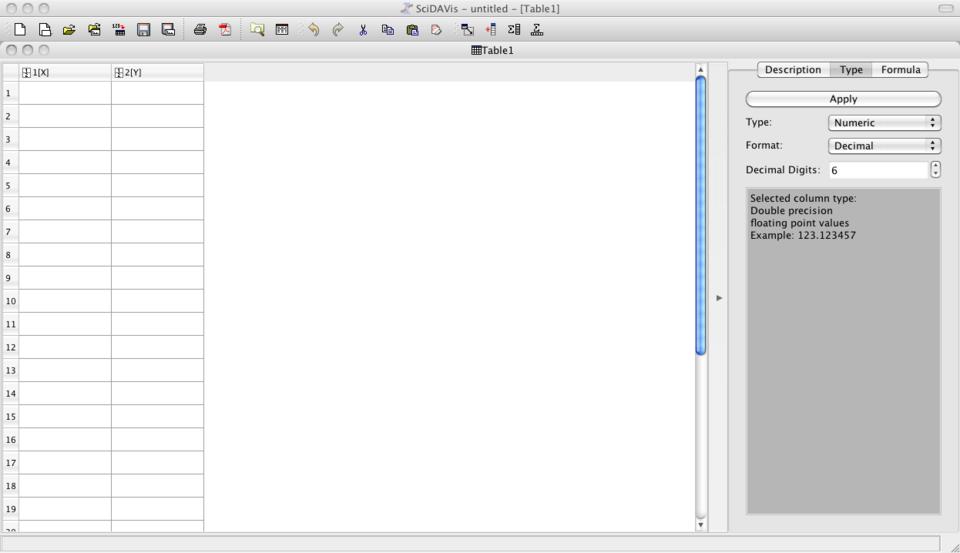
Figure 1. Opening SciDAVis gives you an empty two-column data table.
When you are first learning to use SciDAVis, you probably will just want some junk data to play with. You can do this easily by right-clicking the columns and selecting “Fill Selection with”. Then, you can fill the column with either row numbers or random numbers. Once you have some data available, you can create new columns that are functions of the values stored in the other columns. To access this functionality, you need to select the formula tab in the right-hand side pane. In order to explore some of the other features, let's set the first column to be the row numbers and the second column to be a set of random numbers (Figure 2).
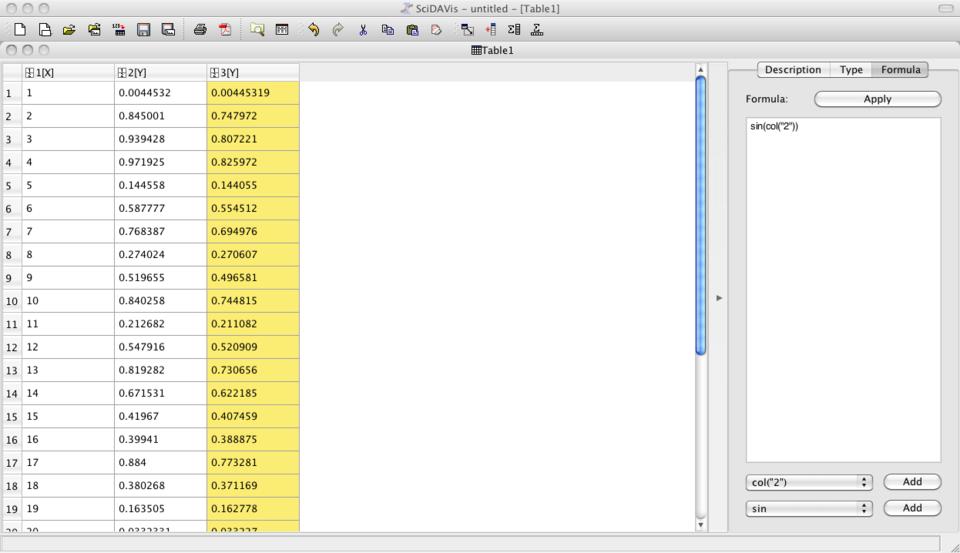
Figure 2. You can use fill functions to create data in order to try things out.
One of the first things you will want to do is plot the data to see what it looks like. To do a basic plot, you simply can right-click on a column and select Plot. If you are just doing an initial look at the shape of the data, select Plot→Line or Plot→Scatter (Figure 3). The x axis is simply the index values, and the y values are the data elements from the column.
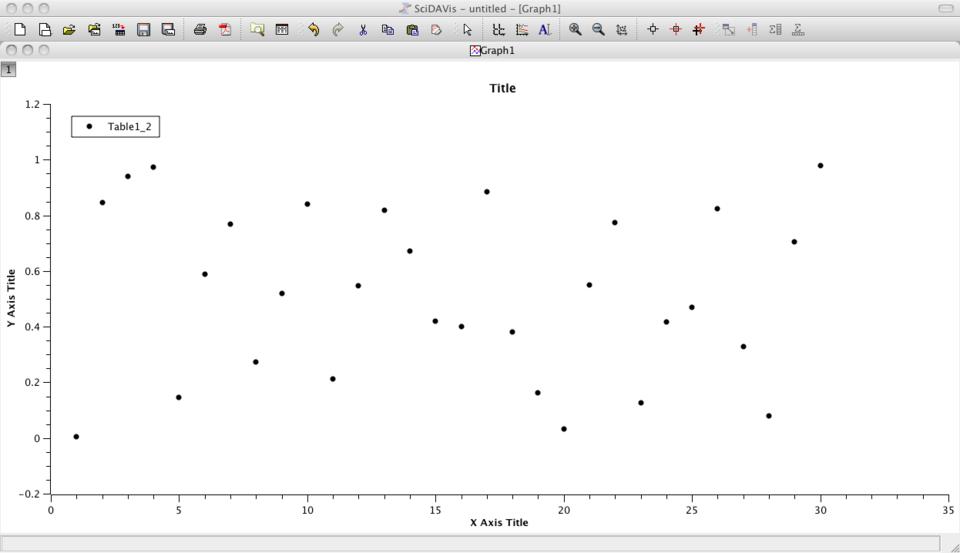
Figure 3. Scatter plots are only a couple mouse clicks away.
If you want to do more complicated plots, SciDAVis provides a full plotting wizard. To access the wizard, either press Ctrl-Alt-W or click View→Plot Wizard. This will pop up a new window where you can select which columns will be used for the x, y and z axes. You also have the option of selecting columns to represent the errors for the x and y axes. You need to create a new curve where you can set the relevant columns. You can create multiple curves that will all be plotted on the same graph. You then get a new window with the plots generated.
The point of SciDAVis is to make this type of work easy, so you can double-click on the various elements to edit the details of your graphs. Double-clicking on the title, or the axis labels, will pop up a window where you can change the content and the display. You also can change the details of the axes themselves. Double-clicking on an axis will pop up a new window where you can set the scale, the type of grid, the axis displays and a set of general options (Figure 4). Each of these sets of options is available under its own tab in the option window.
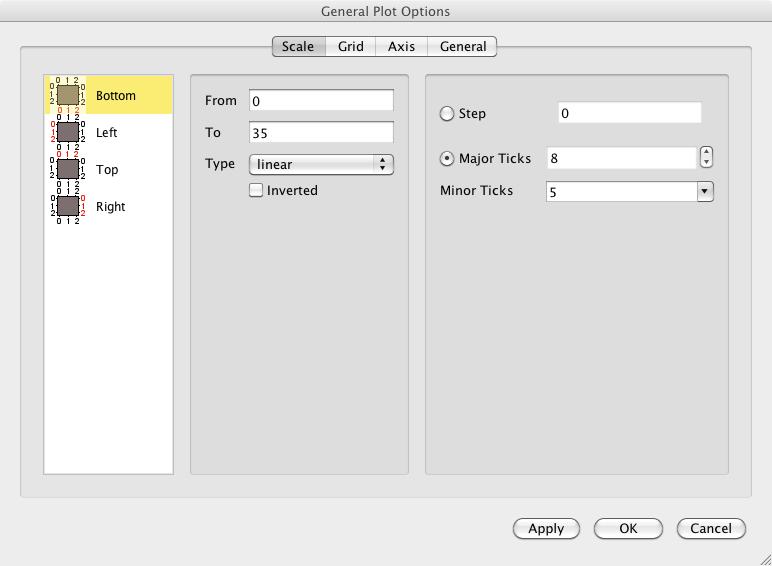
Figure 4. You can change all of the elements of your graphs.
Once the graph looks the way you want it, you will want a copy for your publications. To do this, you either can right-click on the graph and select Export or click on the menu item File→Export Graph. Then you can select your preferred file format for saving the image.
Although graphs can be very useful when trying to get an intuitive grasp of the shape of your data, you do need to back up this intuition with hard numbers. The first thing to do, usually, is simply look at the column statistics. Right-clicking on the column, you would select Column Statistics. This creates a new table where you will get the number of rows in the column, along with other statistics like the standard deviation, variance, sum, minimum and maximum. You can see if there is any correlation between two columns. You need to select two columns from your table, and then click on the menu item Analysis→Correlate. This will pop up a new graph window showing a picture of the correlation. Two new columns will be added to your data table where you can find the lag and correlation values of this particular analysis.
If the data you are looking at has some type of periodicity, you can calculate an FFT of it to see the spread of frequencies within your data. By selecting a column and clicking on the menu item Analysis→FFT, you will get a pop-up window where you can select the details of the FFT you want to calculate. Once these are set, click OK, and a new graph window will be displayed with the FFT plotted (Figure 5).
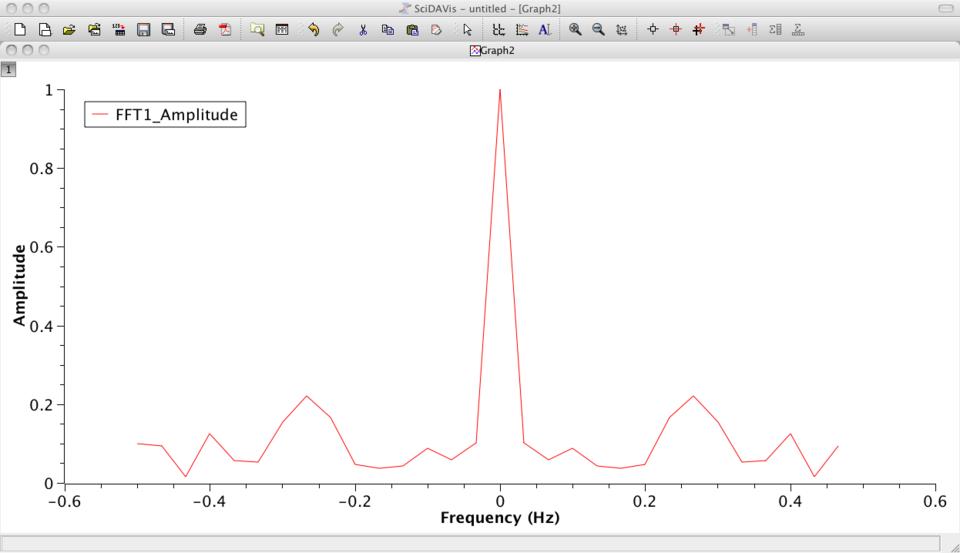
Figure 5. FFT analysis is useful in signal processing.
Once you have had a chance to look at your data, you may have started to form an idea of a model that represents the system you were measuring. An idea is not enough, however. You actually need to do some calculations and see whether your model fits the data you collected. Two options are available. The first is to use the Fit Wizard. You can access it by clicking on the menu item Analysis→Fit Wizard. This pops up a window where you can build a function describing your model. Once you have built up your model, click the button called Fit. This pops up a new window where you can select the details of doing the actual fitting of the generic function to your data. Here you can set the initial guesses and select the algorithm used to do the actual fitting (Figure 6).
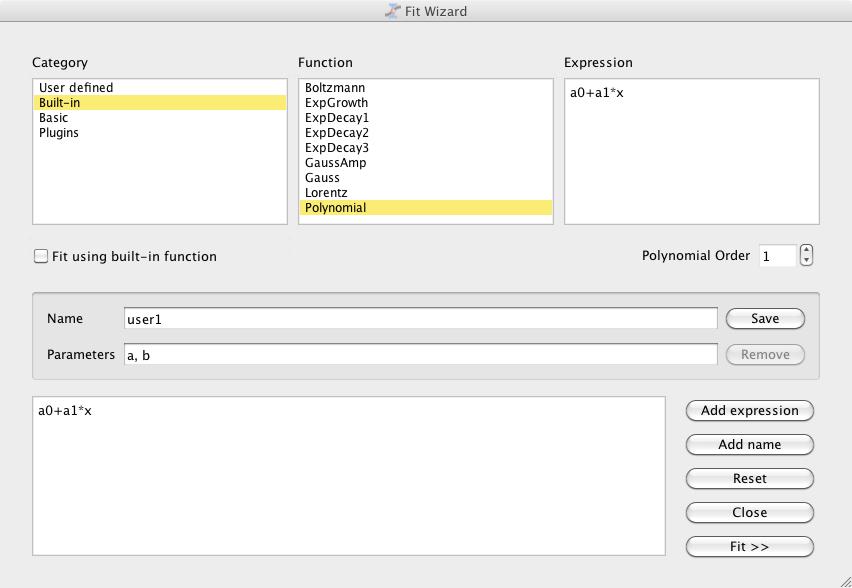
Figure 6. The Fit Wizard lets you define your model and see how well it fits your data.
You also can set how many iterations to try and the tolerance of when you can stop. When everything is set to your satisfaction, click the Fit button. This pops up a new graph window, plus an output window detailing the results of trying to do the fit. The other option of trying to fit your model is to start with your initial graph. In this case, you start by right-clicking the main graph window and selecting the Analyze option. This opens a submenu where you can select one of a number of common defaults, such as linear, polynomial, exponential growth or decay, among several others. You also can open the Fit Wizard from this submenu.
This article has been only a very short introduction. Lots of other functions are available if you are willing to go through the manual. Also, you have the option of using Python as a scripting language within SciDAVis in order to do even more complicated data analysis. You might need to compile from source, however, if the binaries available to you don't include this functionality. Hopefully, you will take the time to learn what may be a very useful tool for analyzing your experimental data.
I'd rather work with someone who's good at their job but doesn't like me, than someone who likes me but is a ninny.
—Sam Donaldson
Better be despised for too anxious apprehensions, than ruined by too confident security.
—Edmund Burke
Age is no guarantee of maturity.
—Lawana Blackwell
Eighty percent of success is showing up.
—Woody Allen
When you can't have what you want, it's time to start wanting what you have.
—Kathleen A. Sutton