Union filesystems don't have much luck with the kernel development process. Miklos Szeredi recently tried to get OverlayFS into the main tree, but he ran into a wall in the form of Al Viro. Linus Torvalds initially responded to Miklos' request with, “I think we should just do it. It's in use, it's pretty small, and the other alternatives are worse.” But when Al started reviewing the code, he found that the underlying filesystem operations were simply way too fragile to support users. Even simple operations like deleting a directory tree would be fraught with messy details that could leave the whole filesystem in an inconsistent state in the event of any interruption. In the end, he couldn't let the code pass through the gates.
Daniel Phillips made some extravagant claims about Tux3 performance recently, and he got slapped around by some kernel folks for it. Apparently, Tux3 had outperformed tmpFS on some particular benchmarks, and Daniel was crowing about it on the mailing list. But after folks like Dave Chinner took a look at the actual numbers, it became clear that the benchmark was unreproducible, and had been specifically engineered to measure only the asynchronous front end of Tux3, so that all the time-consuming hard work behind the scenes never actually was included in the benchmark. There was some grumbling from kernel developers about this, while Daniel argued that the benchmark tested only portions of the code that already had been implemented and that other tests would be done as more of the code was written. Clearly, there are two sides to the story. But as Dave Chinner put it, benchmarks should at least include enough information to reproduce the results.
How should Linux handle empty symlinks? At the moment, Linux doesn't allow users to create them, so you might think there's no problem—if they can't exist, there's no need to handle them one way or another. But, nothing prevents someone from mounting a filesystem that was created on an operating system that does allow empty symlinks. So evidently, there really is a need to handle them properly if they ever appear.
As it turns out, Linux's current behavior is not very well known regarding this issue. Pavel Machek started exploring the various ins and outs of it, but the full scope and nuance may take a while to dig out. But, thanks to Eric Blake's cogent arguing, it's clear that something does need to be done. This is a case of POSIX noncompliance that actually may burn some people, as opposed to the cases of POSIX noncompliance that Linus Torvalds doesn't care about at all, in any way whatsoever. As far as Linus is concerned, if it doesn't hurt anyone, it's not a bug. If there's a way to improve on POSIX, then POSIX is the bug. But this time, it may be that POSIX isn't the bug, and the bug does bite.
Once in a while the GPL v2 becomes the topic of debate. This time, Luke Leighton posted to the mailing list, saying that he wanted all his kernel contributions to be dual-licensed under the GPL v2 and the GPL v3 (and all subsequent versions). But, Cole Johnson and Theodore Ts'o pointed out that Linus Torvalds, and many other top kernel people, very vocally had rejected the GPL v3 for the Linux kernel. Theodore said, “the anti-Tivoization clause in GPLv3 is totally unacceptable, and so many of us have stated unequivocally that our code will be released under a GPLv2-only license. This means that GPLv3-only code is always going to be incompatible with code released as part of the Linux kernel, because substantial parts of the kernel have and will be available only under a GPLv2-only license.”
At one point in the conversation, Rob Landley said that the loss of compatibilities between the GPL v2 and v3 had ruined “copyleft”. He said, “These days the GPL largely serves to prevent code re-use, and people have responded to the perceived problems with 'GPL-next' initiatives where they fragment copyleft further with Affero variants, by using creative commons on code, and so on. But copyleft only ever worked as one big universal license, and now it doesn't.”
He added, “In the absence of a universal receiver, most developers have switched to universal donor licenses: MIT/BSD or even public domain. Yes, 'most': the most common license on GitHub is 'no license specified', and that's not just ignorance, that's napster-style civil disobedience from a generation of coders who lump copyright in with software patents and consider it all 'too dumb to live'.”
A bleak assessment.
Because this issue's theme is programming, I thought I should cover some of the more-advanced features available in OpenMP. Several issues ago, I looked at the basics of using OpenMP (www.linuxjournal.com/content/big-box-science), so you may want go back and review that article. In scientific programming, the basics tend to be the limit of how people use OpenMP, but there is so much more available—and, these other features are useful for so much more than just scientific computing. So, in this article, I delve into other by-waters that never seem to be covered when looking at OpenMP programming. Who knows, you may even replace POSIX threads with OpenMP.
First, let me quickly review a little bit of the basics of OpenMP. All of the examples below are done in C. If you remember, OpenMP is defined as a set of instructions to the compiler. This means you need a compiler that supports OpenMP. The instructions to the compiler are given through pragmas. These pragmas are defined such that they appear as comments to a compiler that doesn't support OpenMP.
The most typical construct is to use a for loop. Say you want to create an array of the sines of the integers from 1 to some maximum value. It would look like this:
#pragma omp parallel for
for (i=0; i<max; i++) {
a[i] = sin(i);
}
Then you would compile this with GCC by using the -fopenmp flag. Although this works great for problems that naturally form themselves into algorithms around for loops, this is far from the majority of solution schemes. In most cases, you need to be more flexible in your program design to handle more complicated parallel algorithms. To do this in OpenMP, enter the constructs of sections and tasks. With these, you should be able to do almost anything you would do with POSIX threads.
First, let's look at sections. In the OpenMP specification, sections are defined as sequential blocks of code that can be run in parallel. You define them with a nested structure of pragma statements. The outer-most layer is the pragma:
#pragma omp parallel sections
{
...commands...
}
Remember that pragmas apply only to the next code block in C. Most simply, this means the next line of code. If you need to use more than one line, you need to wrap them in curly braces, as shown above. This pragma forks off a number of new threads to handle the parallelized code. The number of threads that are created depends on what you set in the environment variable OMP_NUM_THREADS. So, if you want to use four threads, you would execute the following at the command line before running your program:
export OMP_NUM_THREADS=4
Inside the sections region, you need to define a series of individual section regions. Each of these is defined by:
#pragma omp section
{
...commands...
}
This should look familiar to anyone who has used MPI before. What you end up with is a series of independent blocks of code that can be run in parallel. Say you defined four threads to be used for your program. This means you can have up to four section regions running in parallel. If you have more than four defined in your code, OpenMP will manage running them as quickly as possible, farming remaining section regions out to the running threads as soon as they become free.
As a more complete example, let's say you have an array of numbers and you want to find the sine, cosine and tangents of the values stored there. You could create three section regions to do all three steps in parallel:
#pragma omp parallel sections
{
#pragma omp section
for (i=0; i<max, i++) {
sines[i] = sin(A[i]);
}
#pragma omp section
for (j=0; j<max; j++) {
cosines[j] = cos(A[j]);
}
#pragma omp section
for (k=0; k<max; k++) {
tangents[k] = tan(A[k]);
}
}
In this case, each of the section regions has a single code block defined by the for loop. Therefore, you don't need to wrap them in curly braces. You also should have noticed that each for loop uses a separate loop index variable. Remember that OpenMP is a shared memory parallel programming model, so all threads can see, and write to, all global variables. So if you use variables that are created outside the parallel region, you need to avoid multiple threads writing to the same variable. If this does happen, it's called a race condition. It might also be called the bane of the parallel programmer.
The second construct I want to look at in this article is the task. Tasks in OpenMP are even more unstructured than sections. Section regions need to be grouped together into a single sections region, and this entire region gets parallelized. With tasks, they are dumped onto a queue, ready to run as soon as possible. Defining a task is simple:
#pragma omp task
{
...commands...
}
In your code, you would create a general parallel region with the pragma:
#pragma omp parallel
This pragma forks off the number of threads that you set in the OMP_NUM_THREADS environment variable. These threads form a pool that is available to be used by other parallel constructs.
Now, when you create a new task, one of three things might happen. The first is that there is a free thread from the pool. In this case, OpenMP will have that free thread run the code in the task construct. The second and third cases are that there are no free threads available. In these cases, the task may end up being scheduled to run by the originating thread, or it may end up being queued up to run as soon as a thread becomes free.
So, let's say you have a function (called func) that you want to call with five different parameters, such that they are independent, and you want to have them run in parallel. You can do this with the following:
#pragma omp parallel
{
for (i=1; i<6; i++) {
#pragma omp task
func(i);
}
}
This will create a thread pool, and then loop through the for loop and create five tasks to farm out to the thread pool. One cool thing about tasks is that you have a bit more control over how they are scheduled. If you reach a point in your task where you can go to sleep for a while, you actually can tell OpenMP to do that. You can use the pragma:
#pragma omp taskyield
When the currently running thread reaches this point in your code, it will stop and check the task queue to see if there are any waiting to run. If so, it will go ahead and start one of those and put your current task to sleep. When the new task finishes, the suspended task gets picked up and resumes where it left off.
Hopefully, seeing some of the less-common constructs has inspired you to go and check out what other techniques you might be missing from your repertoire. Most parallel frameworks allow you to do most techniques. But each one, for historical reasons, has tended to be used for only one subset of techniques, even though there are constructs available that hardly ever are used. For shared memory programming, the constructs I cover here allow you to do many of the things you can do with POSIX threads without the programming overhead. You just have to trade some of the flexibility you get with POSIX threads.
In a recent career shift, I went from an employer who provided me an iPhone to one who provides me with an Android (Galaxy S4 to be specific). Although I was happy to move to a Linux-based handset, I was concerned about replacing the “Find My iPhone” capability that Apple provides. Not only does my family use it to keep track of each other, but we also relied on it when a phone was misplaced. Does the Google Play store offer anything comparable? Um, yes.
Cerberus is a $4 application (with a generous trial period so you can check it out) that blows Apple's “Find My iPhone” out of the water. Not only can it track down a phone, but it also keeps a history of where the phone has been (Figure 1), takes photos and videos, and yes, sets off an alarm to find your misplaced phone.
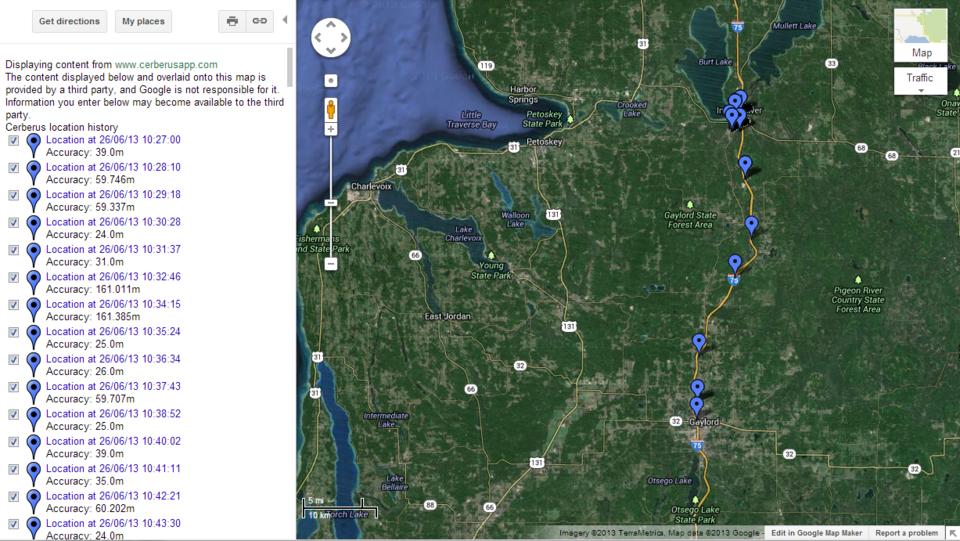
Figure 1. Cerberus Keeps a History of Where the Phone Has Been
I was worried Cerberus might cause unusually high battery usage due to its regular GPS pings, but I haven't noticed any difference at all. Plus, with all its features (Figure 2), I'd be willing to sacrifice a little battery life. Thankfully, I get the best of both worlds!
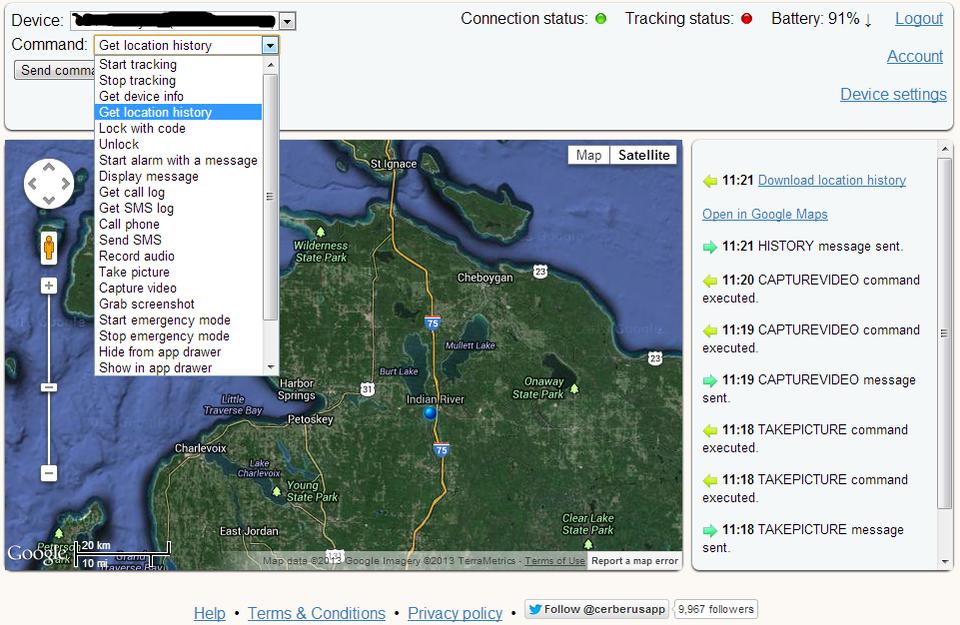
Figure 2. Cerberus' Features
If you are switching from an iPhone to an Android device, or if you've been using Android for a while but haven't installed a security device, I urge you to try Cerberus (www.cerberusapp.com). It's awesome!
My family is in the middle of moving from one house to another. Part of that move involves arranging furniture. I'll be honest, I can move a couch across a room only so many times before I start to think perhaps there's a better way. Thankfully, there is.
Although several 3-D house-modeling packages exist, and a couple are even on-line, nothing seems to work quite as simply as Sweet Home 3D. It's both a 3-D and 2-D layout tool, and it comes with a wide variety of pre-made furniture and window/door graphics to get you started. I was able to design a rudimentary living room in about two minutes (Figure 1), and that included installation time! Sweet Home 3D is an open-source Java application that comes with a nice Windows executable installer.
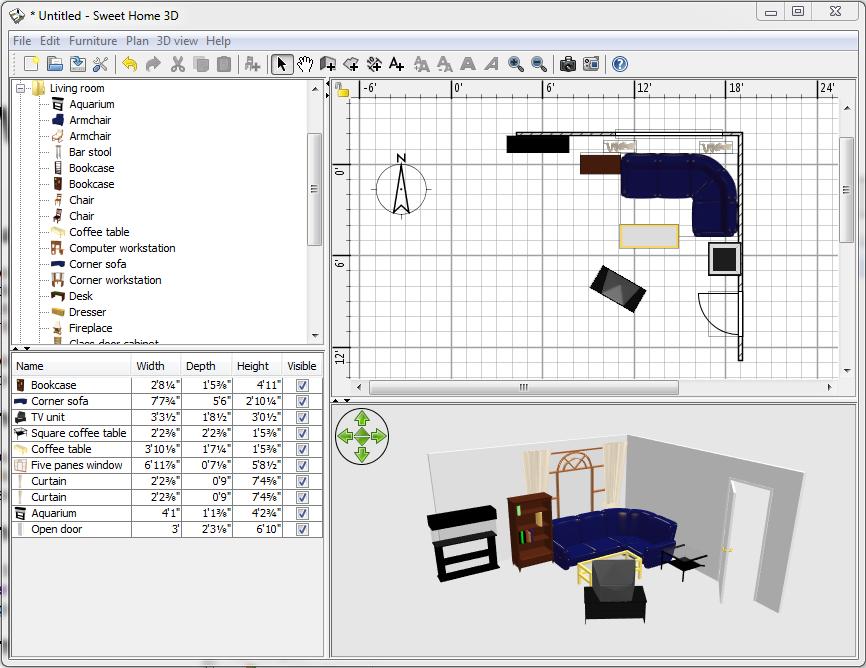
Figure 1. Living Room Design
You might be thinking, if it's Java, won't it run on other platforms too? Well, yes, of course! It might not be as simple as the Windows executable installer to use it on OS X or Linux, but it's Java, so it's cross-platform-compatible. If you need to design a layout for your house, but don't want to haul furniture around to see what it looks like, I highly recommend Sweet Home 3D (www.sweethome3d.com).
Several years back, Songbird was going to be the newest, coolest, most-awesome music player ever to grace the Linux desktop. Then things happened, as they often do, and Linux support for Songbird was discontinued. I've been searching for a favorite music player for years, and although plenty of really nice software packages exist, I generally fall back to XMMS for playing music—until now.
Nightingale is truly everything I want in a music player. It is simple, yet powerful. The default install makes listening to music an educational experience. In Figure 1 you can see that as my Jonathan Coulton song plays, I automatically see the lyrics, plus instant information on the artist. If that sort of information doesn't interest you, no problem, Nightingale is highly customizable with plugins, and there are dozens and dozens available from its Web site (Figure 2 shows a handful of plugins recommended during the installation process).
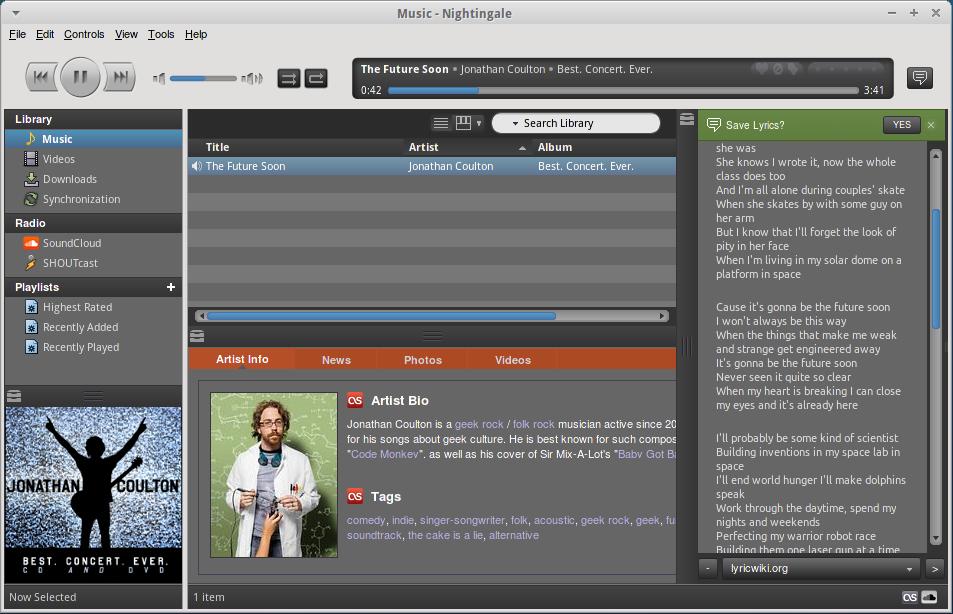
Figure 1. Playing a Song Shows the Lyrics and Artist Info
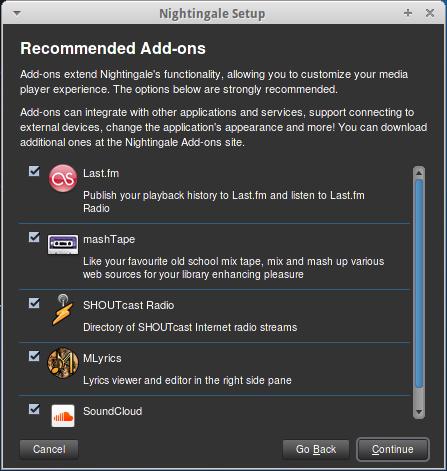
Figure 2. Plugins Recommended during Installation
Every music-playing software package I've tried has disappointed me in one way or another. In my brief relationship with Nightingale, I haven't found a single thing to dislike. The latest version even provides integration into Ubuntu's Unity interface, if that's the desktop environment you prefer. Due to its simple interface, extendible underpinnings, and its continued devotion to the Linux desktop, Nightingale earns this month's Editors' Choice award. Get it for your computer today: www.getnightingale.com.
Life is a great big canvas; throw all the paint on it you can.
—Danny Kaye
To achieve great things we must live as though we were never going to die.
—Marquis de Vauvenargues
It's choice—not chance—that determines your destiny.
—Jean Nidetch
Love all, trust a few. Do wrong to none.
—William Shakespeare
It is a mistake to try to look too far ahead. The chain of destiny can only be grasped one link at a time.
—Sir Winston Churchill
As I was diving back into Window Maker for this article, it occurred to me that the desktop manager I used for years with Debian is disturbingly similar to the Unity Desktop. It's been clear since its inception that I am not a fan of Ubuntu's new Unity interface, yet it's odd that for years I loved Window Maker, which seems fairly similar, at least visually.
After a little bit of usage, however, I quickly remembered why Window Maker was my desktop of choice for many years. Yes, it has the “side dock” look and feel, but it's far, far more customizable (Figure 1). The dockapps can launch applications, certainly, but they also can be applications (widgets?) themselves, providing interaction and feedback instead of just eye candy.
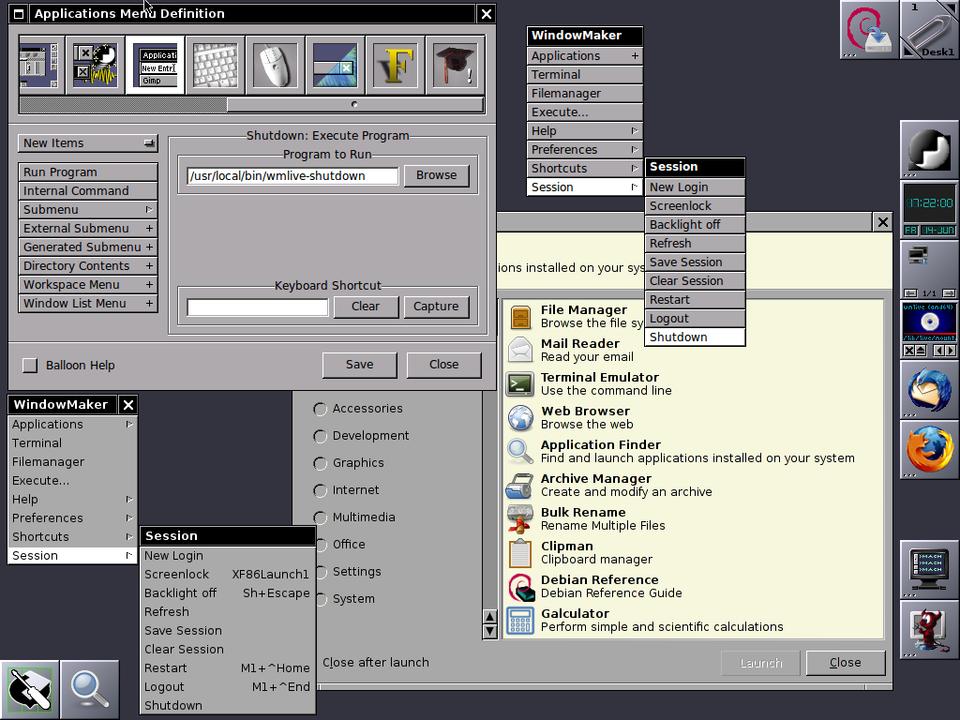
Figure 1. Window Maker is very customizable (screenshot from wmlive.sourceforge.net).
The Window Maker Live CD actually is a great way to install Debian too. If you've never experienced Window Maker firsthand, I urge you to download the ISO file from wmlive.sourceforge.net, and give the live CD a try. If you like it, it's certainly easy to install the full Debian system directly from the CD (Figure 2). Window Maker is a low-resource, awesome desktop environment that's worth checking out, at least for a weekend project.

Figure 2. Window Maker installs the full Debian system directly from CD (screenshot from wmlive.sourceforge.net).