Although most people focus on bandwidth as the main network performance metric, latency is just as important to perceived performance. In this article, Dan explains how overbuffering can cause high latencies and where this can occur in the Linux network stack.
Packet queues are a core component of any network stack or device. They allow for asynchronous modules to communicate, increase performance and have the side effect of impacting latency. This article aims to explain where IP packets are queued on the transmit path of the Linux network stack, how interesting new latency-reducing features, such as BQL, operate and how to control buffering for reduced latency.
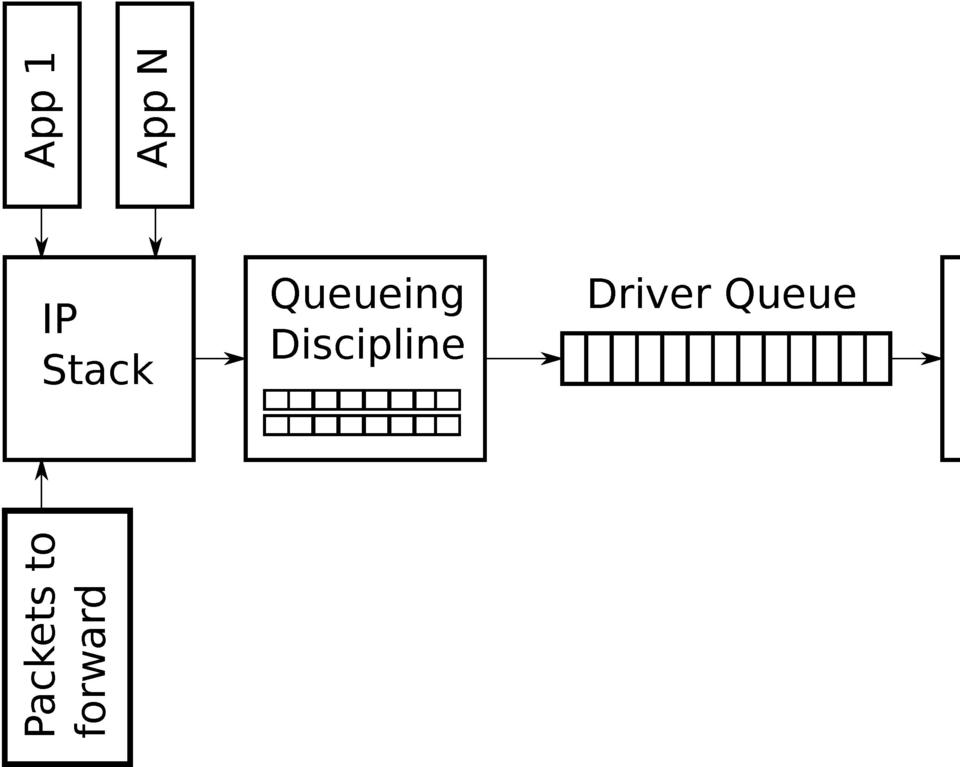
Figure 1. Simplified High-Level Overview of the Queues on the Transmit Path of the Linux Network Stack
Between the IP stack and the network interface controller (NIC) lies the driver queue. This queue typically is implemented as a first-in, first-out (FIFO) ring buffer (en.wikipedia.org/wiki/Circular_buffer)—just think of it as a fixed-sized buffer. The driver queue does not contain the packet data. Instead, it consists of descriptors that point to other data structures called socket kernel buffers (SKBs, vger.kernel.org/%7Edavem/skb.html), which hold the packet data and are used throughout the kernel.
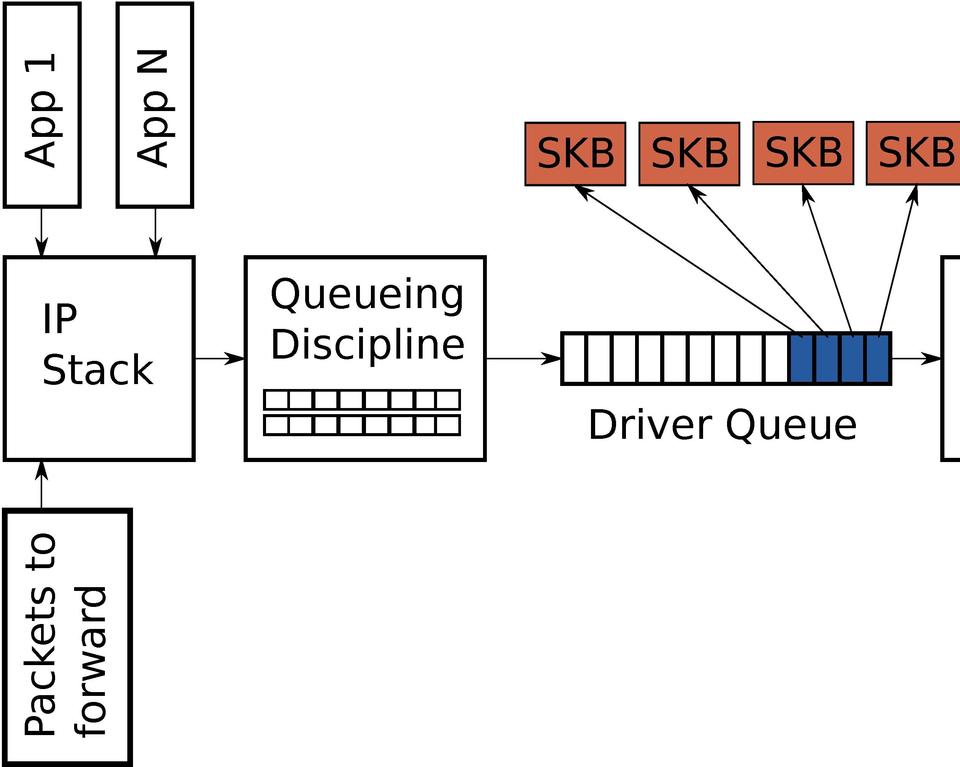
Figure 2. Partially Full Driver Queue with Descriptors Pointing to SKBs
The input source for the driver queue is the IP stack that queues IP packets. The packets may be generated locally or received on one NIC to be routed out another when the device is functioning as an IP router. Packets added to the driver queue by the IP stack are dequeued by the hardware driver and sent across a data bus to the NIC hardware for transmission.
The reason the driver queue exists is to ensure that whenever the system has data to transmit it is available to the NIC for immediate transmission. That is, the driver queue gives the IP stack a location to queue data asynchronously from the operation of the hardware. An alternative design would be for the NIC to ask the IP stack for data whenever the physical medium is ready to transmit. Because responding to this request cannot be instantaneous, this design wastes valuable transmission opportunities resulting in lower throughput. The opposite of this design approach would be for the IP stack to wait after a packet is created until the hardware is ready to transmit. This also is not ideal, because the IP stack cannot move on to other work.
Most NICs have a fixed maximum transmission unit (MTU), which is the biggest frame that can be transmitted by the physical media. For Ethernet, the default MTU is 1,500 bytes, but some Ethernet networks support Jumbo Frames (en.wikipedia.org/wiki/Jumbo_frame) of up to 9,000 bytes. Inside the IP network stack, the MTU can manifest as a limit on the size of the packets that are sent to the device for transmission. For example, if an application writes 2,000 bytes to a TCP socket, the IP stack needs to create two IP packets to keep the packet size less than or equal to a 1,500 MTU. For large data transfers, the comparably small MTU causes a large number of small packets to be created and transferred through the driver queue.
In order to avoid the overhead associated with a large number of packets on the transmit path, the Linux kernel implements several optimizations: TCP segmentation offload (TSO), UDP fragmentation offload (UFO) and generic segmentation offload (GSO). All of these optimizations allow the IP stack to create packets that are larger than the MTU of the outgoing NIC. For IPv4, packets as large as the IPv4 maximum of 65,536 bytes can be created and queued to the driver queue. In the case of TSO and UFO, the NIC hardware takes responsibility for breaking the single large packet into packets small enough to be transmitted on the physical interface. For NICs without hardware support, GSO performs the same operation in software immediately before queueing to the driver queue.
Recall from earlier that the driver queue contains a fixed number of descriptors that each point to packets of varying sizes. Since TSO, UFO and GSO allow for much larger packets, these optimizations have the side effect of greatly increasing the number of bytes that can be queued in the driver queue. Figure 3 illustrates this concept in contrast with Figure 2.
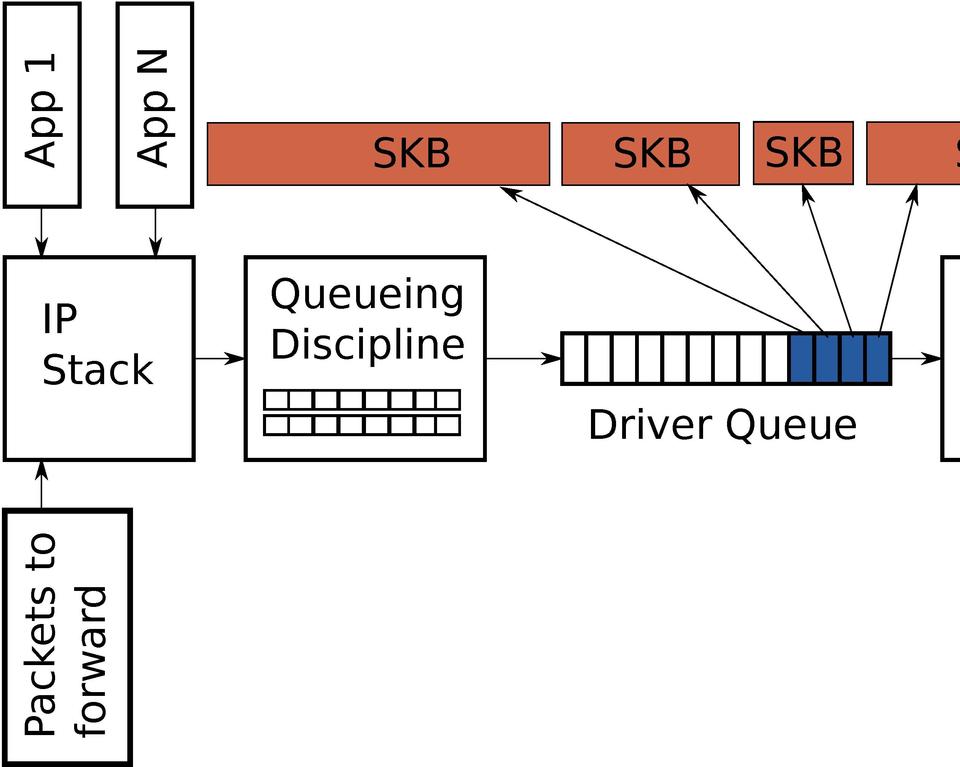
Figure 3. Large packets can be sent to the NIC when TSO, UFO or GSO are enabled. This can greatly increase the number of bytes in the driver queue.
Although the focus of this article is the transmit path, it is worth noting that Linux has receive-side optimizations that operate similarly to TSO, UFO and GSO and share the goal of reducing per-packet overhead. Specifically, generic receive offload (GRO, vger.kernel.org/%7Edavem/cgi-bin/blog.cgi/2010/08/30) allows the NIC driver to combine received packets into a single large packet that is then passed to the IP stack. When the device forwards these large packets, GRO allows the original packets to be reconstructed, which is necessary to maintain the end-to-end nature of the IP packet flow. However, there is one side effect: when the large packet is broken up, it results in several packets for the flow being queued at once. This “micro-burst” of packets can negatively impact inter-flow latency.
Despite its necessity and benefits, the queue between the IP stack and the hardware introduces two problems: starvation and latency.
If the NIC driver wakes to pull packets off of the queue for transmission and the queue is empty, the hardware will miss a transmission opportunity, thereby reducing the throughput of the system. This is referred to as starvation. Note that an empty queue when the system does not have anything to transmit is not starvation—this is normal. The complication associated with avoiding starvation is that the IP stack that is filling the queue and the hardware driver draining the queue run asynchronously. Worse, the duration between fill or drain events varies with the load on the system and external conditions, such as the network interface's physical medium. For example, on a busy system, the IP stack will get fewer opportunities to add packets to the queue, which increases the chances that the hardware will drain the queue before more packets are queued. For this reason, it is advantageous to have a very large queue to reduce the probability of starvation and ensure high throughput.
Although a large queue is necessary for a busy system to maintain high throughput, it has the downside of allowing for the introduction of a large amount of latency.
Figure 4 shows a driver queue that is almost full with TCP segments for a single high-bandwidth, bulk traffic flow (blue). Queued last is a packet from a VoIP or gaming flow (yellow). Interactive applications like VoIP or gaming typically emit small packets at fixed intervals that are latency-sensitive, while a high-bandwidth data transfer generates a higher packet rate and larger packets. This higher packet rate can fill the queue between interactive packets, causing the transmission of the interactive packet to be delayed.
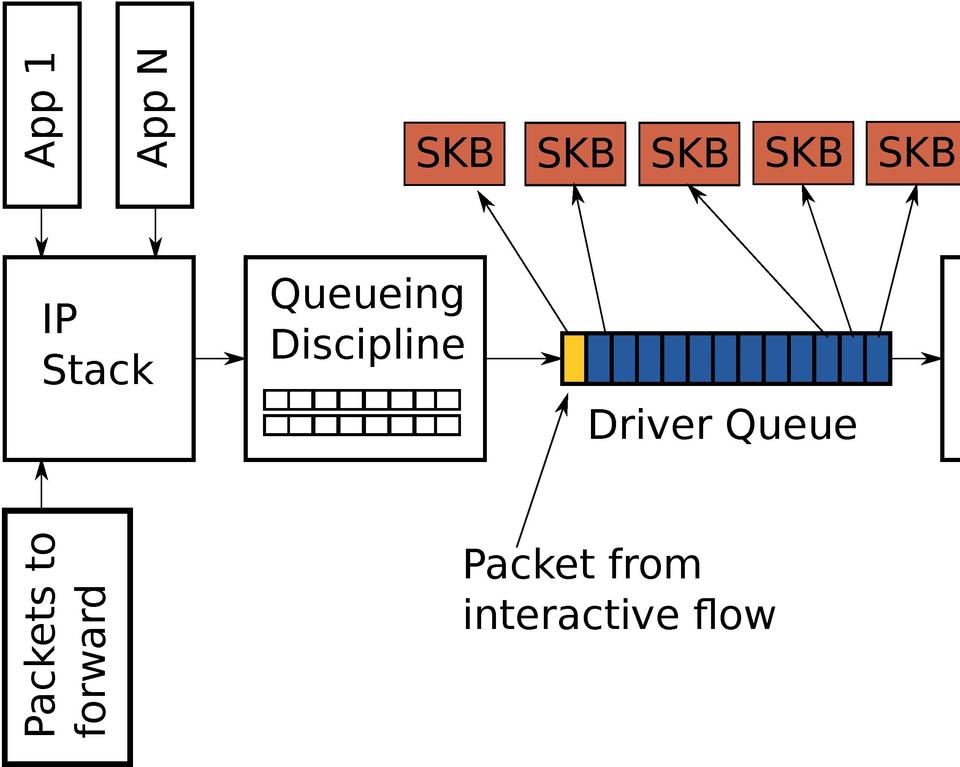
Figure 4. Interactive Packet (Yellow) behind Bulk Flow Packets (Blue)
To illustrate this behaviour further, consider a scenario based on the following assumptions:
A network interface that is capable of transmitting at 5 Mbit/sec or 5,000,000 bits/sec.
Each packet from the bulk flow is 1,500 bytes or 12,000 bits.
Each packet from the interactive flow is 500 bytes.
The depth of the queue is 128 descriptors.
There are 127 bulk data packets and one interactive packet queued last.
Given the above assumptions, the time required to drain the 127 bulk packets and create a transmission opportunity for the interactive packet is (127 * 12,000) / 5,000,000 = 0.304 seconds (304 milliseconds for those who think of latency in terms of ping results). This amount of latency is well beyond what is acceptable for interactive applications, and this does not even represent the complete round-trip time—it is only the time required to transmit the packets queued before the interactive one. As described earlier, the size of the packets in the driver queue can be larger than 1,500 bytes, if TSO, UFO or GSO are enabled. This makes the latency problem correspondingly worse.
Large latencies introduced by over-sized, unmanaged queues is known as Bufferbloat (en.wikipedia.org/wiki/Bufferbloat). For a more detailed explanation of this phenomenon, see the Resources for this article.
As the above discussion illustrates, choosing the correct size for the driver queue is a Goldilocks problem—it can't be too small, or throughput suffers; it can't be too big, or latency suffers.
Byte Queue Limits (BQL) is a new feature in recent Linux kernels (> 3.3.0) that attempts to solve the problem of driver queue sizing automatically. This is accomplished by adding a layer that enables and disables queueing to the driver queue based on calculating the minimum queue size required to avoid starvation under the current system conditions. Recall from earlier that the smaller the amount of queued data, the lower the maximum latency experienced by queued packets.
It is key to understand that the actual size of the driver queue is not changed by BQL. Rather, BQL calculates a limit of how much data (in bytes) can be queued at the current time. Any bytes over this limit must be held or dropped by the layers above the driver queue.
A real-world example may help provide a sense of how much BQL affects the amount of data that can be queued. On one of the author's servers, the driver queue size defaults to 256 descriptors. Since the Ethernet MTU is 1,500 bytes, this means up to 256 * 1,500 = 384,000 bytes can be queued to the driver queue (TSO, GSO and so forth are disabled, or this would be much higher). However, the limit value calculated by BQL is 3,012 bytes. As you can see, BQL greatly constrains the amount of data that can be queued.
BQL reduces network latency by limiting the amount of data in the driver queue to the minimum required to avoid starvation. It also has the important side effect of moving the point where most packets are queued from the driver queue, which is a simple FIFO, to the queueing discipline (QDisc) layer, which is capable of implementing much more complicated queueing strategies.
The driver queue is a simple first-in, first-out (FIFO) queue. It treats all packets equally and has no capabilities for distinguishing between packets of different flows. This design keeps the NIC driver software simple and fast. Note that more advanced Ethernet and most wireless NICs support multiple independent transmission queues, but similarly, each of these queues is typically a FIFO. A higher layer is responsible for choosing which transmission queue to use.
Sandwiched between the IP stack and the driver queue is the queueing discipline (QDisc) layer (Figure 1). This layer implements the traffic management capabilities of the Linux kernel, which include traffic classification, prioritization and rate shaping. The QDisc layer is configured through the somewhat opaque tc command. There are three key concepts to understand in the QDisc layer: QDiscs, classes and filters.
The QDisc is the Linux abstraction for traffic queues, which are more complex than the standard FIFO queue. This interface allows the QDisc to carry out complex queue management behaviors without requiring the IP stack or the NIC driver to be modified. By default, every network interface is assigned a pfifo_fast QDisc (lartc.org/howto/lartc.qdisc.classless.html), which implements a simple three-band prioritization scheme based on the TOS bits. Despite being the default, the pfifo_fast QDisc is far from the best choice, because it defaults to having very deep queues (see txqueuelen below) and is not flow aware.
The second concept, which is closely related to the QDisc, is the class. Individual QDiscs may implement classes in order to handle subsets of the traffic differently—for example, the Hierarchical Token Bucket (HTB, lartc.org/manpages/tc-htb.html). QDisc allows the user to configure multiple classes, each with a different bitrate, and direct traffic to each as desired. Not all QDiscs have support for multiple classes. Those that do are referred to as classful QDiscs, and those that do not are referred to as classless QDiscs.
Filters (also called classifiers) are the mechanism used to direct traffic to a particular QDisc or class. There are many different filters of varying complexity. The u32 filter (www.lartc.org/lartc.html#LARTC.ADV-FILTER.U32) is the most generic, and the flow filter is the easiest to use.
In looking at the figures for this article, you may have noticed that there are no packet queues above the QDisc layer. The network stack places packets directly into the QDisc or else pushes back on the upper layers (for example, socket buffer) if the queue is full. The obvious question that follows is what happens when the stack has a lot of data to send? This can occur as the result of a TCP connection with a large congestion window or, even worse, an application sending UDP packets as fast as it can. The answer is that for a QDisc with a single queue, the same problem outlined in Figure 4 for the driver queue occurs. That is, the high-bandwidth or high-packet rate flow can consume all of the space in the queue causing packet loss and adding significant latency to other flows. Because Linux defaults to the pfifo_fast QDisc, which effectively has a single queue (most traffic is marked with TOS=0), this phenomenon is not uncommon.
As of Linux 3.6.0, the Linux kernel has a feature called TCP Small Queues that aims to solve this problem for TCP. TCP Small Queues adds a per-TCP-flow limit on the number of bytes that can be queued in the QDisc and driver queue at any one time. This has the interesting side effect of causing the kernel to push back on the application earlier, which allows the application to prioritize writes to the socket more effectively. At the time of this writing, it is still possible for single flows from other transport protocols to flood the QDisc layer.
Another partial solution to the transport layer flood problem, which is transport-layer-agnostic, is to use a QDisc that has many queues, ideally one per network flow. Both the Stochastic Fairness Queueing (SFQ, crpppc19.epfl.ch/cgi-bin/man/man2html?8+tc-sfq) and Fair Queueing with Controlled Delay (fq_codel, linuxmanpages.net/manpages/fedora18/man8/tc-fq_codel.8.html) QDiscs fit this problem nicely, as they effectively have a queue-per-network flow.
Driver Queue:
The ethtool command (linuxmanpages.net/manpages/fedora12/man8/ethtool.8.html) is used to control the driver queue size for Ethernet devices. ethtool also provides low-level interface statistics as well as the ability to enable and disable IP stack and driver features.
The -g flag to ethtool displays the driver queue (ring) parameters:
# ethtool -g eth0 Ring parameters for eth0: Pre-set maximums: RX: 16384 RX Mini: 0 RX Jumbo: 0 TX: 16384 Current hardware settings: RX: 512 RX Mini: 0 RX Jumbo: 0 TX: 256
You can see from the above output that the driver for this NIC defaults to 256 descriptors in the transmission queue. Early in the Bufferbloat investigation, it often was recommended to reduce the size of the driver queue in order to reduce latency. With the introduction of BQL (assuming your NIC driver supports it), there no longer is any reason to modify the driver queue size (see below for how to configure BQL).
ethtool also allows you to view and manage optimization features, such as TSO, GSO, UFO and GRO, via the -k and -K flags. The -k flag displays the current offload settings and -K modifies them.
As discussed above, some optimization features greatly increase the number of bytes that can be queued in the driver queue. You should disable these optimizations if you want to optimize for latency over throughput. It's doubtful you will notice any CPU impact or throughput decrease when disabling these features unless the system is handling very high data rates.
Byte Queue Limits (BQL):
The BQL algorithm is self-tuning, so you probably don't need to modify its configuration. BQL state and configuration can be found in a /sys directory based on the location and name of the NIC. For example: /sys/devices/pci0000:00/0000:00:14.0/net/eth0/queues/tx-0/byte_queue_limits.
To place a hard upper limit on the number of bytes that can be queued, write the new value to the limit_max file:
echo "3000" > limit_max
What Is txqueuelen?
Often in early Bufferbloat discussions, the idea of statically reducing the NIC transmission queue was mentioned. The txqueuelen field in the ifconfig command's output or the qlen field in the ip command's output show the current size of the transmission queue:
$ ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:18:F3:51:44:10
inet addr:69.41.199.58 Bcast:69.41.199.63 Mask:255.255.255.248
inet6 addr: fe80::218:f3ff:fe51:4410/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:435033 errors:0 dropped:0 overruns:0 frame:0
TX packets:429919 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:65651219 (62.6 MiB) TX bytes:132143593 (126.0 MiB)
Interrupt:23
$ ip link
1: lo: mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:18:f3:51:44:10 brd ff:ff:ff:ff:ff:ff
The length of the transmission queue in Linux defaults to 1,000 packets, which is a large amount of buffering, especially at low bandwidths.
The interesting question is what queue does this value control? One might guess that it controls the driver queue size, but in reality, it serves as a default queue length for some of the QDiscs. Most important, it is the default queue length for the pfifo_fast QDisc, which is the default. The “limit” argument on the tc command line can be used to ignore the txqueuelen default.
The length of the transmission queue is configured with the ip or ifconfig commands:
ip link set txqueuelen 500 dev eth0
Queueing Disciplines:
As introduced earlier, the Linux kernel has a large number of queueing disciplines (QDiscs), each of which implements its own packet queues and behaviour. Describing the details of how to configure each of the QDiscs is beyond the scope of this article. For full details, see the tc man page (man tc). You can find details for each QDisc in man tc qdisc-name (for example, man tc htb or man tc fq_codel).
TCP Small Queues:
The per-socket TCP queue limit can be viewed and controlled with the following /proc file: /proc/sys/net/ipv4/tcp_limit_output_bytes.
You should not need to modify this value in any normal situation.
Unfortunately, not all of the over-sized queues that will affect your Internet performance are under your control. Most commonly, the problem will lie in the device that attaches to your service provider (such as DSL or cable modem) or in the service provider's equipment itself. In the latter case, there isn't much you can do, because it is difficult to control the traffic that is sent toward you. However, in the upstream direction, you can shape the traffic to slightly below the link rate. This will stop the queue in the device from having more than a few packets. Many residential home routers have a rate limit setting that can be used to shape below the link rate. Of course, if you use Linux on your home gateway, you can take advantage of the QDisc features to optimize further. There are many examples of tc scripts on-line to help get you started.
Queueing in packet buffers is a necessary component of any packet network, both within a device and across network elements. Properly managing the size of these buffers is critical to achieving good network latency, especially under load. Although static queue sizing can play a role in decreasing latency, the real solution is intelligent management of the amount of queued data. This is best accomplished through dynamic schemes, such as BQL and active queue management (AQM, en.wikipedia.org/wiki/Active_queue_management) techniques like Codel. This article outlines where packets are queued in the Linux network stack, how features related to queueing are configured and provides some guidance on how to achieve low latency.
Thanks to Kevin Mason, Simon Barber, Lucas Fontes and Rami Rosen for reviewing this article and providing helpful feedback.