You're an ace at log forensics, but what tool will you reach for when you are given 100 10GB files and an hour to process them? Probably not sed or grep.
When your data and work grow, and you still want to produce results in a timely manner, you start to think big. Your one beefy server reaches its limits. You need a way to spread your work across many computers. You truly need to scale out.
In pioneer days they used oxen for heavy pulling, and when one ox couldn't budge a log, they didn't try to grow a larger ox. We shouldn't be trying for bigger computers, but for more systems of computers.—Grace Hopper
Clearly, cluster computing is old news. What's changed? Today:
We collect more data than ever before.
Even small-to-medium-size businesses can benefit from tools like Hadoop and MapReduce.
You don't have to have a PhD to create and use your own cluster.
Many decent free/libre open-source tools can help you easily cluster commodity hardware.
Let me start with some simple examples that will run on one machine and scale to meet larger demands. You can try them on your laptop and then transition to a larger cluster—like one you've built with commodity Linux machines, your company or university's Hadoop cluster or Amazon Elastic MapReduce.
Let's start with problems that can be divided into smaller independent units of work. These problems are roughly classified as “embarrassingly parallel” and are—as the term suggests—suitable for parallel processing. Examples:
Classify e-mail messages as spam.
Transcode video.
Render an Earth's worth of map tile images.
Count logged lines matching a pattern.
Figure out errors per day of week for a particular application.
Now the hard work begins. Parallel computing is complex. Race conditions, partial failure and synchronization impede our progress. Here's where MapReduce saves our proverbial bacon.
MapReduce is a coding pattern that abstracts much of the tricky bits of scalable computations. We're free to focus on the problem at hand, but it takes practice. So let's practice!
Say you have 100 10GB log files from some custom application—roughly a petabyte of data. You do a quick test and estimate it will take your desktop days do grep every line (assuming you even could fit the data on your desktop). And, that's before you add in logic to group by host and calculate totals. Your tried-and-true shell utilities won't help, but MapReduce can handle this without breaking a sweat.
First let's look at the raw data. Log lines from the custom application look like this:
localhost: restarting dsl5.example.com: invalid user 'bart' dsl5.example.com: invalid user 'charlie' dsl5.example.com: invalid user 'david' dsl8.example.net: invalid password for user 'admin' dsl8.example.net: user 'admin' logged in
The log format is hostname, colon, message. Your boss suspects someone evil is trying to brute-force attack the application. The same host trying many different user names may indicate an attack. He wants totals of “invalid user” messages grouped by hostname. Filtering the above log lines should yield:
dsl5.example.com 3
With gigabytes of log files, your trusty shell tools do just fine. For a terabyte, more power is needed. This is a job for Hadoop and MapReduce.
Before getting to Hadoop, let's summon some Python and test locally on a small dataset. I'm assuming you have a recent Python installed. I tested with Python 2.7.3 on Ubuntu 12.10.
The first program to write consumes log lines from our custom application. Let's call it map.py:
#!/usr/bin/python
import sys
for line in sys.stdin:
if 'invalid user' in line:
host = line.split(':')[0]
print '%s\t%s' % (host, 1)
map.py prints the hostname, a tab character and the number 1 any time it sees a line containing the string “invalid user”. Write the example log lines to log.txt, then test map.py:
chmod 755 map.py ./map.py < log.txt
The output is:
dsl5.example.com 1 dsl5.example.com 1 dsl5.example.com 1
Output of map.py will be piped into our next program, reduce.py:
#!/usr/bin/python
import sys
last_host = None
last_count = 0
host = None
for line in sys.stdin:
host, count = line.split('\t')
count = int(count)
if last_host == host:
last_count += count
else:
if last_host:
print '%s\t%s' % (last_host, last_count)
last_host = host
last_count = count
if last_host == host:
print '%s\t%s' % (last_host, last_count)
reduce.py totals up consecutive lines of a particular host. Let's assume lines are grouped by hostname. If we see the same hostname, we increment a total. If we encounter a different hostname, we print the total so far and reset the total and hostname. When we exhaust standard input, we print the total if necessary. This assumes lines with the same hostname always appear consecutively. They will, and I'll address why later. Test by piping it together with map.py like so:
chmod 755 reduce.py ./map.py < log.txt | sort | ./reduce.py
Later, I'll explain why I added sort to the pipeline. This prints:
dsl5.example.com 3
Exactly what we want. A successful test! Our test log lines contain three “invalid user” messages for the host dsl5.example.com. Later we'll get this local test running on a Hadoop cluster.
Let's dive a little deeper. What exactly does map.py do? It transforms unstructured log data into tab-separated key-value pairs. It emits a hostname for a key, a tab and the number 1 for a value (again, only for lines with “invalid user” messages). Note that any number of log lines could be fed to any number of instances of the map.py program—each line can be examined independently. Similarly, each output line of map.py can be examined independently.
Output from map.py becomes input for reduce.py. The output of reduce.py (hostname, tab, number) looks very similar to its input. This is by design. Key-value pairs may be reduced multiple times, so reduce.py must handle this gracefully. If we were to re-reduce our final answer, we would get the exact same result. This repeatable, predictable behavior of reduce.py is known as idempotence.
We just tested with one instance of reduce.py, but you could imagine many instances of reduce.py handling many lines of output from map.py. Note that this works only if lines with the same hostname appear consecutively. In our test, we enforce this constraint by adding sort to the pipeline. This simulates how our code behaves within Hadoop MapReduce. Hadoop will group and sort input to reduce.py similarly.
We don't have to bother with how execution will proceed and how many instances of map.py and reduce.py will run. We just follow the MapReduce pattern and Hadoop does the rest.
Hadoop is mostly a Java framework, but the magically awesome Streaming utility allows us to use programs written in other languages. The program must only obey certain conventions for standard input and output (which we've already done).
You'll need Java 1.6.x or later (I used OpenJDK 7). The rest can and should be performed as a nonroot user.
Download the latest stable Hadoop tarball (see Resources). Don't use a distro-specific (.rpm or .deb) package. I'm assuming you downloaded hadoop-1.0.4.tar.gz. Unpack this and change into the hadoop-1.0.4 directory. The directory hadoop-1.0.4 and the files map.py, reduce.py and log.txt should be in /tmp. If not, adjust the paths in the examples below as necessary.
Run the job on Hadoop like so:
cd /tmp/hadoop-1.0.4 bin/hadoop jar \ contrib/streaming/hadoop-streaming-1.0.4.jar \ -mapper /tmp/map.py -reducer /tmp/reduce.py \ -input /tmp/log.txt -output /tmp/output
Hadoop will log some stuff to the console. Look for the following:
... INFO streaming.StreamJob: map 0% reduce 0% INFO streaming.StreamJob: map 100% reduce 0% INFO streaming.StreamJob: map 100% reduce 100% INFO streaming.StreamJob: Output: /tmp/output
This means our job completed successfully. I see a file called /tmp/output/part-00000, which contains just what we expect:
dsl5.example.com 3
Now is a good time to pause, smile and reward yourself with a quad-shot grande iced caramel macchiato. You're a rockstar.
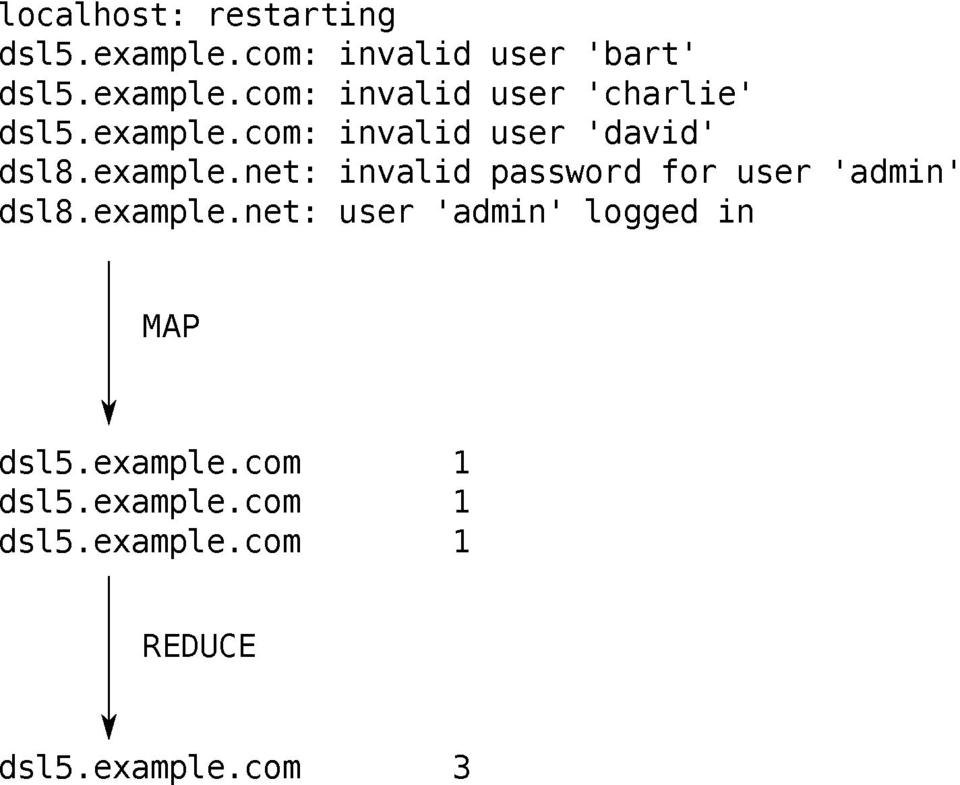
Figure 1. Here's what we did during the map and reduce steps. The transformations we performed allow us to run many mappers and reducers on as many machines as we want. Hadoop takes care of the gory details. It starts mappers and reducers, passes data between them and spits out the answer.
If you've got everything working so far, try starting your own cluster too! Running Hadoop on a single physical machine with multiple Java virtual machines is called pseudo-distributed operation.
Pseudo-distributed operation requires some configuration. The user you're running Hadoop as must also be able to make SSH passwordless connections to localhost. Installing and configuring this is beyond the scope of this article, but you'll find more information in the “Single Node Setup” tutorial mentioned in Resources. If you started with the 1.0.4 tarball release recommended above, the tutorial should work verbatim on any standard GNU/Linux distribution.
If you set up pseudo-distributed (or distributed) Hadoop, you'll gain the benefit of two spartan-but-useful Web interfaces. The NameNode Web interface allows you to browse logs and browse the Hadoop distributed filesystem. The JobTracker Web interface allows you to monitor MapReduce jobs and debug problems.
Figure 2. NameNode Web Interface
Figure 3. JobTracker Web Interface
You may wonder why reduce.py (above) is a convoluted mini-state machine. This is because hostnames change in the input lines provided by Hadoop. The Dumbo Python library (see Resources) hides this detail of Hadoop. Dumbo lets us focus even more tightly on our mapping and reducing.
In Dumbo, our MapReduce implementation becomes:
def mapper(key, value):
if 'invalid user' in value:
yield value.split(':')[0], 1
def reducer(key, values):
yield key, sum(values)
if __name__ == '__main__':
import dumbo
dumbo.run(mapper, reducer)
The state machine is gone. Dumbo takes care of grouping by key (hostname).
Save the above code in a file called /tmp/smart.py. Install Dumbo. See Resources for a link, and don't worry, it's easy. Once Dumbo is installed, run the code:
cd /tmp dumbo start smart.py -hadoop hadoop-1.0.4 \ -input log.txt -output totals \ -outputformat text
Finally, examine the output:
cat totals/part-00000
The content should match our earlier result from Hadoop Streaming.
Hadoop is great for one-time jobs and off-line batch processing, especially where the data is already in the Hadoop filesystem and will be read many times. My first example makes more sense if you assume this. Perhaps the job must be run daily and must finish within a few minutes.
Consider some cases when Hadoop is the wrong tool. Small dataset? Don't bother. In a one-meter race between a rocket and a scooter, the scooter is gone before the rocket's engines are started. Transactional data storage for a Web site? Try MySQL or MongoDB instead.
Hadoop also won't help you process data as it arrives. This is often referred to as “real time” or “streaming”. For that, consider Storm (see Resources for more information).
With practice, you'll quickly be able to discern when Hadoop is the right tool for the job.