Cloud infrastructure must become efficient as demand grows—thus, the end of VMs.
Cloud infrastructure providers like Amazon Web Service sell virtual machines. EC2 revenue is expected to surpass $1B in revenue this year. That's a lot of VMs.
It's not hard to see why there is such demand. You get the ability to scale up or down, guaranteed computational resources, security isolation and API access for provisioning it all, without any of the overhead of managing physical servers.
But, you are also paying for lot of increasingly avoidable overhead in the form of running a full-blown operating system image for each virtual machine. This approach has become an unnecessarily heavyweight solution to the underlying question of how to best run applications in the cloud.
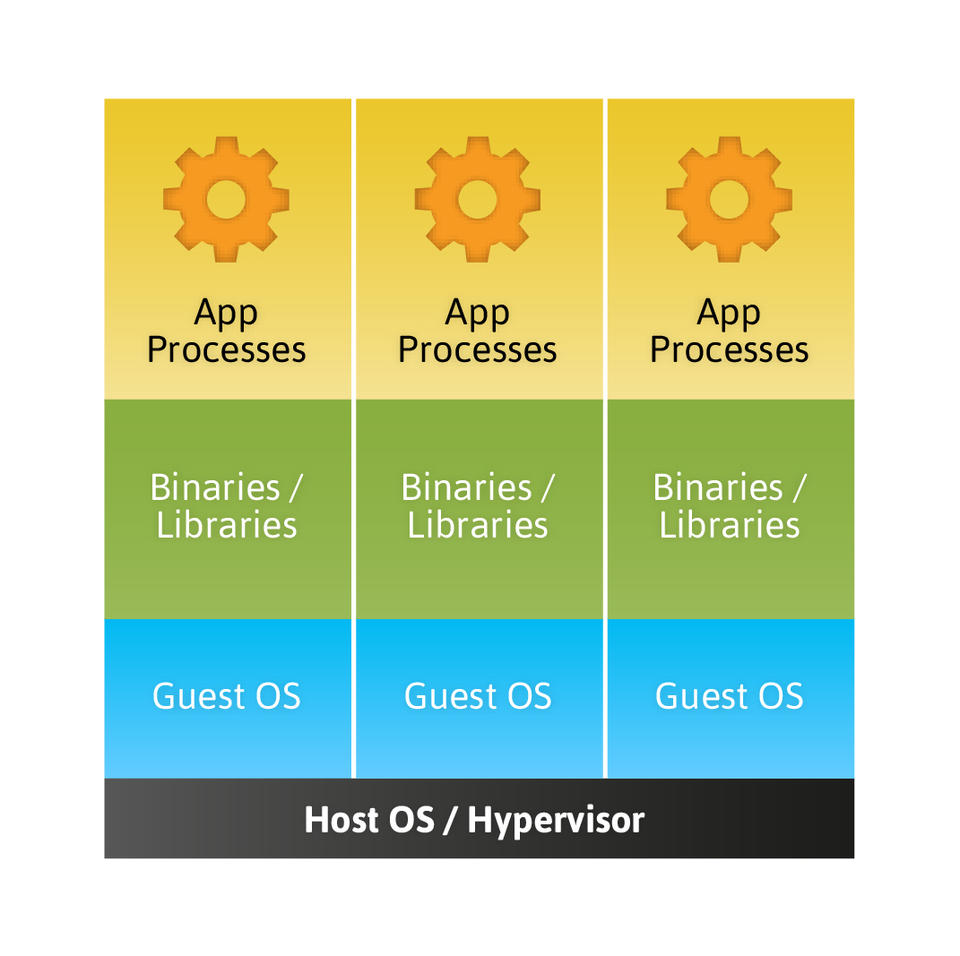
Figure 1. Traditional virtualization and paravirtualization require a full operating system image for each instance.
Until recently it has been assumed that OS virtualization is the only path to provide appropriate isolation for applications running on a server. These assumptions are quickly becoming dated, thanks to recent underlying improvements to how the Linux kernel can now manage isolation between applications.
Containers now can be used as an alternative to OS-level virtualization to run multiple isolated systems on a single host. Containers within a single operating system are much more efficient, and because of this efficiency, they will underpin the future of the cloud infrastructure industry in place of VM architecture.
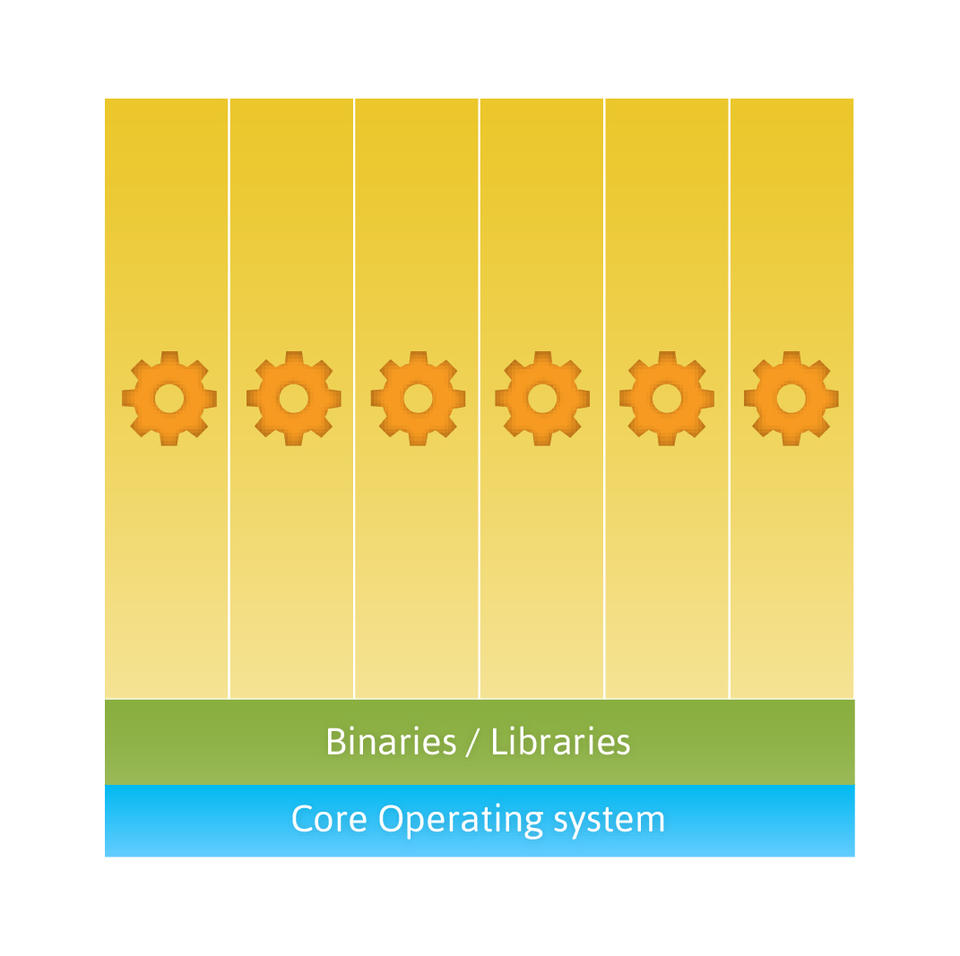
Figure 2. Containers can share a single operating system and, optionally, other binary and library resources.
There is a good reason why we buy by the virtual machine today: containers used to be terrible, if they existed in any useful form at all. Let's hop back to 2005 for a moment. “chroot” certainly didn't (and still doesn't) meet the resource and security isolation goals for multi-tenant designs. “nice” is a winner-takes-all scheduling mechanism. The “fair” resource scheduling in the kernel is often too fair, equally balancing resources between a hungry, unimportant process and a hungry, important one. Memory and file descriptor limits offer no gradient between normal operation and crashing an application that's overstepped its boundaries.
Virtual machines were able to partition and distribute resources viably in the hypervisor without relying on kernel support or, worse, separate hardware. For a long time, virtual machines were the only way on Linux to give Application A up to 80% of CPU resources and Application B up to 20%. Similar partitioning and sharing schemes exist for memory, disk block I/O, network I/O and other contentious resources.
Virtual machines have made major leaps in efficiency too. What used to be borderline-emulation has moved to direct hardware support for memory page mapping and other hard-to-virtualize features. We're down to a CPU penalty of only a few percent versus direct hardware use.
Here are the penalties we currently pay for VMs:
Running a whole separate operating system to get a resource and security isolation.
Slow startup time while waiting for the OS to boot.
The OS often consumes more memory and more disk than the actual application it hosts. The Rackspace Cloud recently discontinued 256MB instances because it didn't see them as practical. Yet, 256MB is a very practical size for an application if it doesn't need to share that memory with a full operating system.
As for slow startup time, many cloud infrastructure users keep spare virtual machines around to accelerate provisioning. Virtual machines have taken the window from requesting to receiving resources down to minutes, but having to keep spare resources around is a sign that it's still either too slow or not reliable enough.
VMs are fairly standardized; a system image running on one expects mostly the same things as if it had its own bare-metal computer. Containers are not very standardized in the industry as a whole. They're very OS- and kernel-specific (BSD jails, Solaris Zones, Linux namespaces/cgroups). Even on the same kernel and OS, options may range from security sandboxes for individual processes to nearly complete systems.
VMs don't have to run the same kernel or OS as the host and they obtain access to resources from the host over virtualized devices—like network cards—and network protocols. However, VMs are fairly opaque to the host system; the hypervisor has poor insight into what's been written but freed in block storage and memory. They usually leverage hardware/CPU-based facilities for isolating their access to memory and appear as a handful of hypervisor processes on the host system.
Containers have to run the same kernel as the host, but they can optionally run a completely different package tree or distribution. Containers are fairly transparent to the host system. The kernel manages memory and filesystem access the same way as if it were running on the host system. Containers obtain access to resources from the host over normal userland/IPC facilities. Some implementations even support handing sockets from the host to the container of standard UNIX facilities.
VMs are also heavyweight. They require a full OS and system image, such as EC2's AMIs. The hypervisor runs a boot process for the VM, often even emulating BIOS. They usually appear as a handful of hypervisor processes on the host system. Containers, on the other hand, are lightweight. There may not be any persistent files or state, and the host system usually starts the containerized application directly or runs a container-friendly init dæmon, like systemd. They appear as normal processes on the host system.
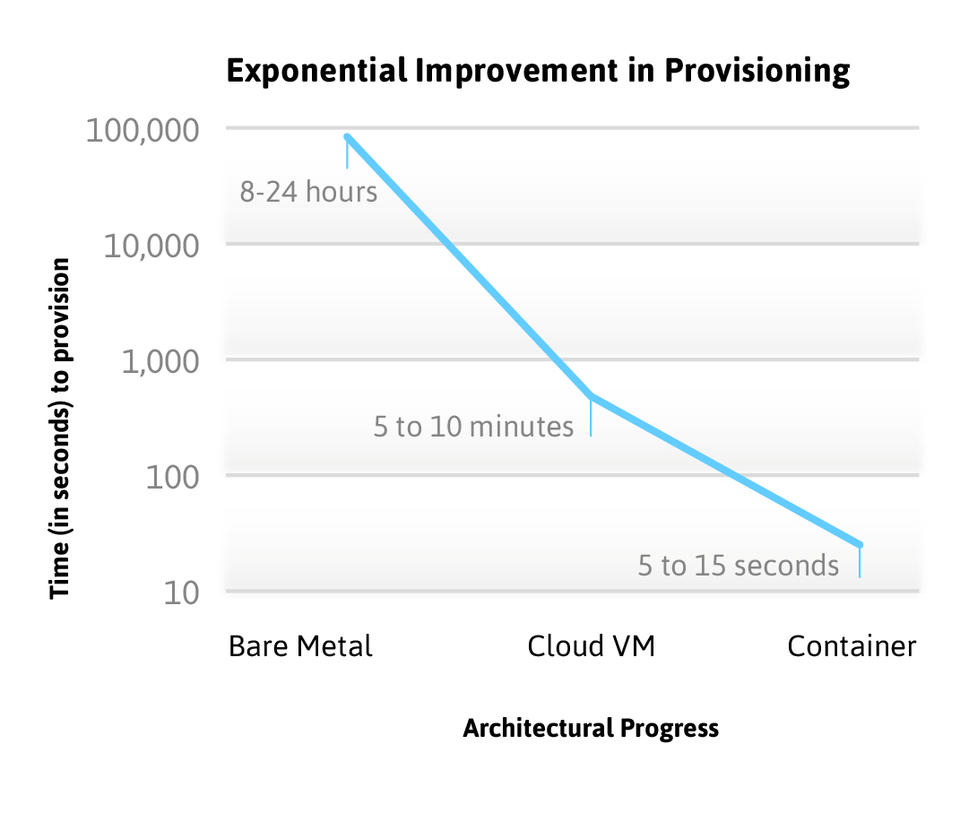
Figure 3. Virtualization decoupled provisioning from hardware deployment. Containers decouple provisioning from OS deployment and boot-up.
Compared to a virtual machine, the overhead of a container is disruptively low. They start so fast that many configurations can launch on-demand as requests come in, resulting in zero idle memory and CPU overhead. A container running systemd or Upstart to manage its services has less than 5MB of system memory overhead and nearly zero CPU consumption. With copy-on-write for disk, provisioning new containers can happen in seconds.
Containers are how we at Pantheon maintain a consistent system architecture that spans free accounts up to clustered, highly available enterprise users. We manage an internal supply of containers that we provision using an API.
We're not alone here; virtually every large PaaS system—including Heroku, OpenShift, dotCloud and Cloud Foundry—has a container foundation for running their platform tools. PaaS providers that do rely on full virtual machines have inflexibly high infrastructure costs that get passed onto their customers (which is the case for our biggest competitors in our market).
The easiest way to play with containers and experience the difference is by using a modern Linux OS—whether locally, on a server or even on a VM. There is a great tutorial on Fedora by Dan Walsh and another one with systemd's nspawn tool that includes the UNIX socket handoff.
While Pantheon isn't in the business of providing raw containers as a service, we're working toward the open-source technical foundations. It's in the same spirit as why Facebook and Yahoo incubated Hadoop; it's part of the foundation we need to build the product we want. We directly contribute as co-maintainers to systemd, much of which will be available in the next Red Hat Enterprise Linux release. We also send patches upstream to enable better service “activation” support so containers can run only when needed.
We have a goal that new installations of Fedora and other major distributions, like Ubuntu, provide out-of-the-box, standard API and command-line tools for managing containers, binding them to ports or IP addresses and viewing the resource reservation and utilization levels. This capability should enable other companies eventual access to a large pool of container hosts and flavors, much as Xen opened the door to today's IaaS services.
One way we'll measure progress toward this goal is how “vanilla” our container host machines are. If we can prepare a container host system by just installing some packages and a certificate (or other PKI integration), we'll have achieved it. The free, open-source software (FOSS) world will be stronger for it, and Pantheon will also benefit by having less code to maintain and broader adoption of container-centric computing.
There's also an advantage to this sort of FOSS contribution versus Cloud Foundry, OpenShift or OpenStack, which are open-source PaaS and LaaS stacks. What Pantheon is doing with projects like systemd redefines how users manage applications and resources even on single machines. The number of potential users—and, since it's FOSS, contributors—is orders of magnitude larger than for tools that require multi-machine deployments to be useful. It's also more sustainable in FOSS to have projects where 99% of the value reaches 99% of a large, existing user base.
Efficiency demands a future of containers running on bare-metal hardware. Virtual machines have had their decade.