Despite popular myths, Linux systems can crash, a situation known as oops or panic. When this happens at home, you are inconvenienced. When a critical bug in the kernel causes a production server to stop working, the importance of environment stability and control gains more focus. Linux kernel crashes quickly can escalate from single host events into widespread outages. We want to identify issues in the Linux kernel quickly and contain and resolve them without any adverse impact or downtime for our customers—and we have a solution.
In time-to-market critical data-center environments, kernel crashes can adversely impact the availability and productivity of compute resources. Resolving bugs in the kernel code that cause the oops and panic situations is of paramount importance. In homogeneous environments, where a single operating system version dominates most of the install base, individual bugs gain even more focus, as they potentially can manifest on all machines in a very short period of time.
The automated Linux kernel crash collection, analysis and reporting infrastructure is a novel and complete solution we designed to address the quality and stability of the system's core component, the kernel. The solution relies on the built-in kernel memory dumping mechanism called Kdump (lse.sourceforge.net/kdump), which allows machines experiencing a kernel oops or panic to dump the contents of their memory to a disk. The analysis of memory dumps is performed using the crash utility (people.redhat.com/anderson/crash_whitepaper).
The Linux kernel crash infrastructure consists of a number of individual components, most of which can be deployed separately in a modular fashion:
Kdump mechanism—the Kdump functionality is built in to the Linux kernel. The tool collects memory cores when kernel oops or panic states occur and saves them as a core file to local disk. The necessary configuration, which also requires editing the bootloader menu entries, is deployed using a configuration management tool.
Kernel crash analysis init script—the script runs on machine startup and checks if crash data exists on the disk, creates an analysis file from the memory core using the crash utility, uploads the data to the central NFS repository, and notifies system administrators about the event via e-mail. The script was developed in-house and written in Perl. Like Kdump, we distribute the script to all hosts using a centralized configuration management tool.
Central NFS storage repository—the repository is a large storage area where kernel crash dumps are copied into per-machine directories. We perform data cleanup on a regular basis, with information older than 30 days purged to conserve space. The main purpose of the storage area is to allow system administrators to keep data while they escalate problems to operating system vendors.
Kernel crash database and database population script—a Perl script runs as a scheduled job once a day and copies new crash information from the central NFS repository into an SQL database for permanent retention. The script parses out important fields from the analysis file. Most notably, the exception RIP entry shown in the backtrace (bt) of the crash dump is used as a unique identifier, as it contains the kernel function and the offset where the oops or panic initiated. A single database serves all our data centers across the globe.
Kernel crash monitoring module—this Perl-based component reads crash data from the database and generates alerts for machines, machine models and crash reasons that exceed environment normalcy thresholds in given time periods. We use the module to detect site-wide issues that may not be immediately apparent from single crashes. The monitor can send e-mails or display alerts to a 24/7 manned Web console. Figure 1 shows a mockup view of the monitoring console output.
Kernel crash reporting module—the reporting facility allows a global overview and drill-down of major kernel crash trends that impact our sites, including overall uptime and stability, resolved and unresolved reasons, patch coverage and other valuable metrics. Figure 2 shows a sample monthly analysis report, and Figure 3 shows the entire infrastructure layout.
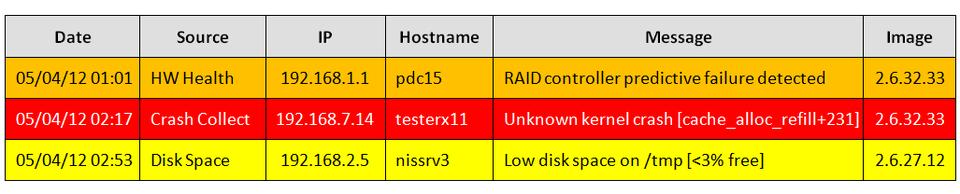
Figure 1. Sample Kernel Crash Alert
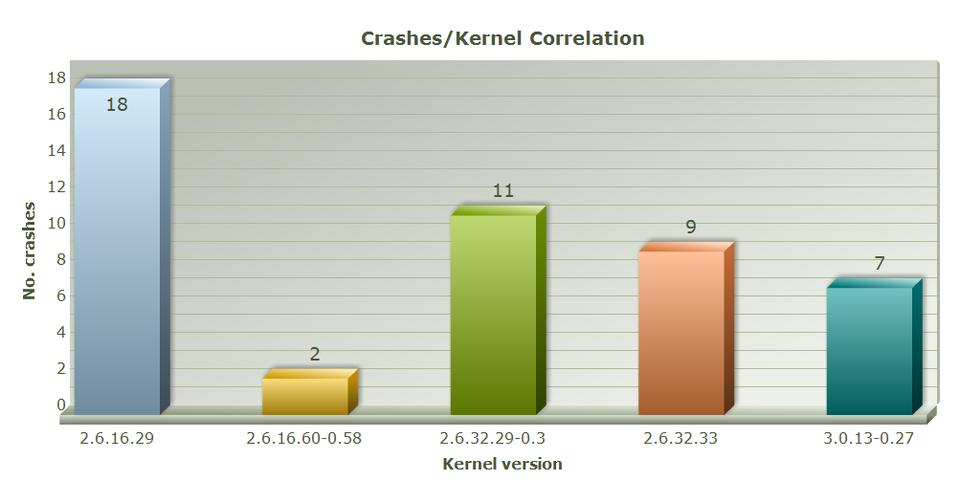
Figure 2. Sample Kernel Crash Report View
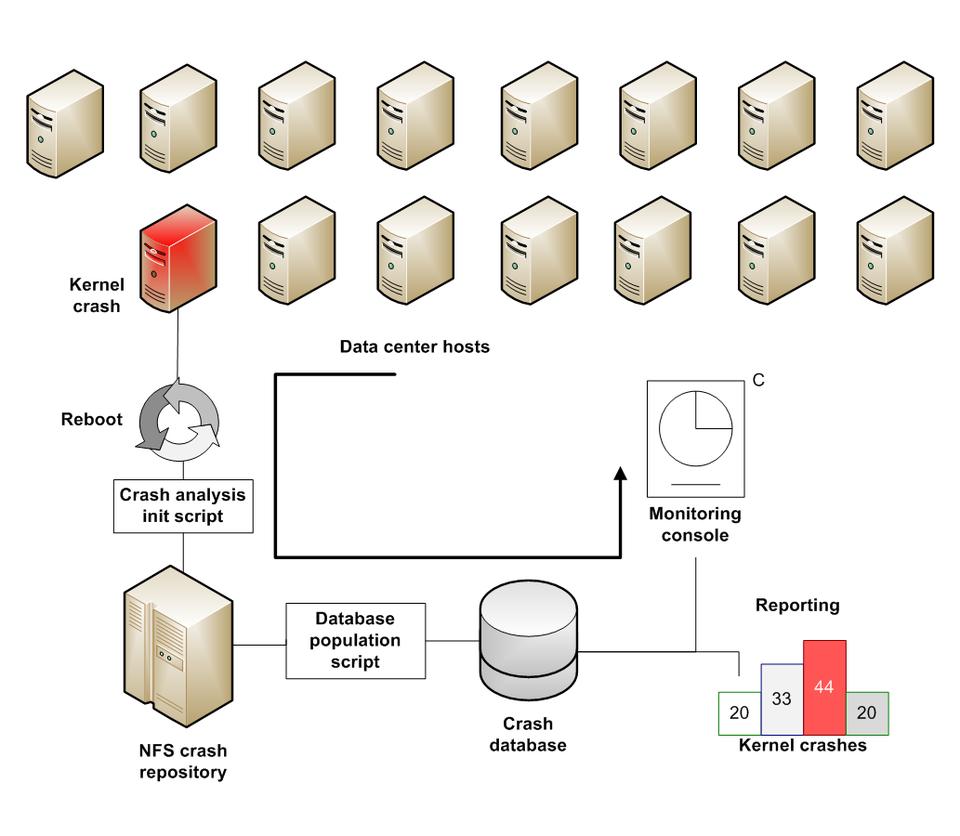
Figure 3. Linux Kernel Crash Infrastructure
Crash data consists of the entire memory core dumped at the time of the crash, kept in a file named vmcore. We analyze the memory core using the crash utility. To automate the procedure, we invoke the crash utility in an unattended manner using an input file with line-delimited crash commands. An interactive view of the crash utility running in a terminal window is shown in Figure 4.
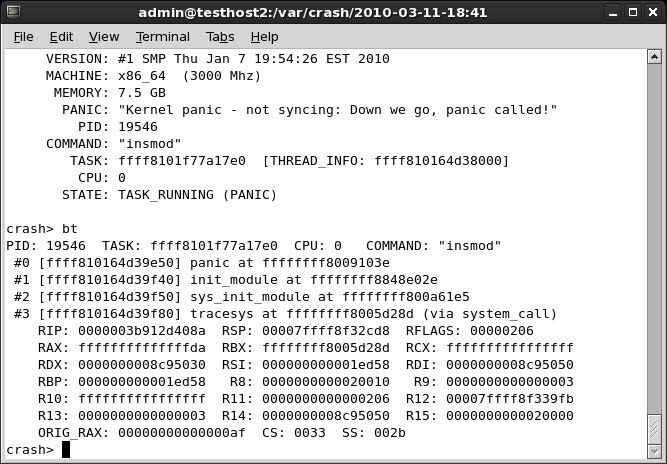
Figure 4. Analysis File Parsed from the Crash Data
Currently, we use the backtrace (bt) of the active task at the time of the crash, the kernel buffer log (log) and the process tree (ps) as main information sources for the initial analysis of the crash data. While a complete analysis of the crash data requires availability of sources and can be done only by the software vendor, the analysis file is extremely useful in isolating core issues and identifying crash patterns.
System bugs usually manifest themselves in specific, repeatable task call traces that can be uniquely identified by the exception pointer, a line in the code where the failure occurred. On the other hand, hardware problems usually are erratic and will result in multiple crash reasons for the same host. In almost all cases, the function name and the offset allow analyzing and mapping crash reasons in a deterministic manner, separating bugs from hardware failures.
Using the available data, we can monitor the environment and correlate crash reasons to recent changes, like the introduction of new system images, patches, firmware updates, new hardware platforms and so on. We use three main categories to classify crash data:
Individual host crashes—repeated crashes of the same host usually stem from hardware problems. We use this information to schedule machine downtime for diagnostics and maintenance.
Machine model crashes—multiple crashes of different hosts sharing the same hardware configuration might indicate a problem with one of the hardware components, such as recent firmware updates or the hardware + operating system combination.
Crash reasons—multiple instances of the same crash reason seen on different machines and machine models are usually a good indication of an operating system bug. However, in most cases, even a single memory core is sufficient to determine and patch the problem.
Following an initial analysis based on the unique crash string match, we can determine whether we're dealing with an existing problem under investigation, a problem already patched by the vendor or a completely new phenomenon. The monitoring component allows us to determine the scope and severity of the incident quickly and precisely
We manage the environment in a fully automated and optimized manner. Known crash reasons are logged in the database for the purpose of statistics and trending, but we skip copying these memory cores into the NFS repository to minimize network and storage overhead. On the other hand, we give new, unknown kernel crash events full priority. Crash data containing new information is sent to operating system vendors for a complete analysis. Most of the time, the crash data submission results in important kernel patches.
Working with Linux kernel crashes is not an easy task and entails many difficulties.
Crash data analysis files contain very high-level information that cannot be easily interpreted even by experienced users. Expert knowledge is required.
Diagnosing hardware problems using crash data is not always straightforward. Crash reports stemming from hardware problems are never fully accurate and are quite difficult to understand. Multiple crash reports and diagnostic checks are sometimes required to determine whether the root cause is in faulty hardware.
Even though most of the software we use is open source, certain parts of the kernel code are not available to us. Lack of familiarity with the code internals also makes it more challenging to understand the execution flow, even if all sources are available. This means that crash analysis will always depend on vendor support.
Linux crash monitoring takes place behind the scenes and its value may not be immediately appreciated. In parallel to the mission of getting the technical parts in place, it is important to work on raising awareness to the need and benefits of the solution.
Linux kernel crash infrastructure has proven to be the single-most effective framework for resolving core system issues across our data centers. In the past two years, we have reported more than 70 unique cases of kernel crashes to operating system vendors, unknown in the IT industry beforehand. Many of the resulting bug fixes were ported into the mainline kernel branch.
More important, we see a clear correlation between the kernel patching derived from kernel crash analysis and fixes and the overall stability of our operational environment. We have gradually observed an almost 10x reduction in the incidence rate of kernel crashes since we fully deployed the solution globally in all our data centers.
The reduction in the number of crashes directly translates into higher availability of compute resources, as well as accurate future prediction into capacity growth against environment stability. We are capable of quantifying the control factor as we possess the tools to detect, assess and resolve critical problems immediately
The concept of the Linux kernel crash infrastructure usually raises a number of interesting questions related to its functionality and wider impact. In this discussion, we'll try to answer these questions:
Why not let vendors handle the problem entirely on their own; after all, they provide all the support?
What is the monetary return of the crash infrastructure solution?
Is there any impact of this solution outside your company?
We are aware of the fact that our computer environment is unique, both in its size, scope and setup. However, as technology leaders and early adopters, we are usually among the first operating system users to discover core problems in the kernel.
Therefore, we cannot depend solely on vendor solutions for managing our environment. Most operating system vendors do not have the necessary resources to replicate a large percentage of various system bugs that we encounter, and they rely on our help to troubleshoot them. Having the right tools and proper expertise makes the task easier and faster.
Another question that is often asked is: how much money is a kernel crash worth?
In the past year alone, we handled approximately 30 different crash types, each of which had the potential of affecting the entire installation base. With the theoretical incidence rate of as little as 0.05 per crash reason, a typical data center with 10,000 hosts would encounter some 500 crashes each time a new critical bug is discovered. This translates into roughly 15,000 crash events annually.
If we assume that no customer productivity is lost because of the kernel crashes, which is almost never the case, and an average downtime of only one hour, an uncontrolled environment with the install base of 10,000 machines would suffer some 15,000 machine hours lost every year. However, if the kernel crashes are left unresolved, the entire install base could potentially be impacted.
A fully automated and proactive Linux kernel crash infrastructure allows us not only to save machines from crashing, but it also enables us to have new capabilities and features that otherwise could not have been used because of the existing bugs.
Last but not the least, the positive impact of our crash infrastructure goes beyond the confines of our company. Fixes in the kernel resulting from our reports are sometimes ported into existing and new releases of various operating systems and sometimes even into the mainline kernel. Our work directly impacts the quality of Linux, as a whole, worldwide.
Linux kernel crash infrastructure is a proven, effective and comprehensive solution for maintaining full situational awareness of our compute environment. The benefits are many: we improve the stability by working with vendors on resolving critical bugs; we maximize uptime, and we gain additional expertise and cooperation between our sites.
We maintain a hassle-free, automated and almost fully self-governed kernel health cycle. Most important, we are in control of our systems. This is evident in the 10x reduction in the crash incidence rate since the full deployment began. We thoroughly recommend its integral use in large, critical time-to-market data centers.