An interesting side effect of last year's cyber attack on the kernel.org server was to identify which of the various services offered were most needed by the community. Clearly one of the hottest items was git repository hosting. And within the clamor for that one feature, much to Willy Tarreau's surprise, there was a bunch of people who were very serious about regaining access to the 2.4 tree.
Willy had been intending to bring this tree to its end of life, but suddenly a cache of users who cared about its continued existence was revealed. In light of that discovery, Willy recently announced that he intends to continue to update the 2.4 tree. He won't make any more versioned releases, but he'll keep adding fixes to the tree, as a centralized repository that 2.4 users can find and use easily.
Any attempt to simplify the kernel licensing situation is bound to be met with many objections. Luis R. Rodriguez discovered this recently when he tried to replace all kernel symbols indicating both the GPL version 2 and some other license, like the BSD or MPL, with the simple text “GPL-Compatible”.
It sounds pretty reasonable. After all, the kernel really cares only if code is GPL-compatible so it can tell what interfaces to expose to that code, right? But, as was pointed out to Luis, tons of issues are getting in the way. For one thing, someone could interpret “GPL-Compatible” to mean that the code can be re-licensed under the GPL version 3, which Linus Torvalds is specifically opposed to doing.
For that matter, as also was pointed out, someone could interpret “GPL-Compatible” as indicating that the code in that part of the kernel could be re-licensed at any time to the second of the two licenses—the BSD or whatever—which also is not the case. Kernel code is all licensed under the GPL version 2 only. Any dual license applies to code distributed by the person who submitted it to the kernel in the first place. If you get it from that person, you can re-license under the alternate license.
Also, as Alan Cox pointed out, the license-related kernel symbols are likely to be valid evidence in any future court case, as indicating the intention of whomever released the code. So, if Luis or anyone else adjusted those symbols, aside from the person or organization who submitted the code in the first place, it could cause legal problems down the road.
And finally, as Al Viro and Linus Torvalds both said, the “GPL-Compatible” text only replaced text that actually contained useful information with something that was more vague.
It looks like an in-kernel disassembler soon will be included in the source tree. Masami Hiramatsu posted a patch implementing that specifically so kernel oops output could be rendered more readable.
This probably won't affect regular users very much though. H. Peter Anvin, although in favor of the feature in general, wants users to have to enable it explicitly on the command line at bootup. His reasoning is that oops output already is plentiful and scrolls right off the screen. Masami's disassembled version would take up more space and cause even more of it to scroll off the screen.
With support from folks like H. Peter and Ingo Molnar, it does look as if Masami's patch is likely to go into the kernel, after some more work.
Whether you love Apple products or think they are abominations, it's hard to beat iPods when it comes to audiobooks. They remember your place, support chapters and even offer speed variations on playback. Thanks to programs like Banshee and Amarok, syncing most iPod devices (especially the older iPod Nanos, which are perfect audiobook players) is simple and works out of the box.
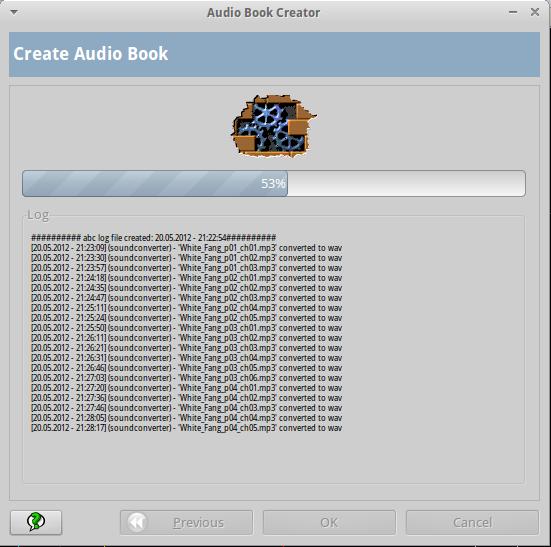
The one downside with listening to audiobooks on iPods is that they accept only m4b files. Most audiobooks either are ripped from CDs into MP3 files or are downloaded as MP3 files directly. There are some fairly simple command-line tools for converting a bunch of MP3 files into iPod-compatible m4b files, but if GUI tools are your thing, Audio Book Creator (ABC) might be right up your alley.
ABC is a very nice GUI application offered by a German programmer. The Web site is www.ausge.de, and although the site is in German, the program itself is localized and includes installation instructions in English. The program does require a few dependencies to be installed, but the package includes very thorough instructions. If you want to create iPod-compatible audiobooks, ABC is as simple as, well, ABC!
My past articles in this space have covered specific software packages, programming libraries and algorithm designs. One subject I haven't discussed yet is data storage, specifically data formats used for scientific information. So in this article, I look at two of the most common file formats: NetCDF (www.unidata.ucar.edu/software/netcdf) and HDF (www.hdfgroup.org). Both of these file formats include command-line tools and libraries that allow you to access these file formats from within your own code.
NetCDF (Network Common Data Format) is an open file format designed to be self-describing and machine-independent. The project is hosted by the Unidata program at UCAR (University Corporation for Atmospheric Research). UCAR is working on it actively, and version 4.1 was released in 2010.
NetCDF supports three separate binary data formats. The classic format has been used since the very first version of NetCDF, and it is still the default format. Starting with version 3.6.0, a 64-bit offset format was introduced that allowed for larger variable and file sizes. Then, starting with version 4.0, NetCDF/HDF5 was introduced, which was HDF5 with some restrictions. These files are meant to be self-describing as well. This means they contain a header that describes in some detail all of the data that is stored in the file.
The easiest way to get NetCDF is to check your distribution's package management system. Sometimes, however, the included version may not have the compile time settings that you need. In those cases, you need to grab the tarball and do a manual installation. There are interfaces for C, C++, FORTRAN 77, FORTRAN 90 and Java.
The classic format consists of a file that contains variables, dimensions and attributes. Variables are N-dimensional arrays of data. This is the actual data (that is, numbers) that you use in your calculations. This data can be one of six types (char, byte, short, int, float and double). Dimensions describe the axes of the data arrays. A dimension has a name and a length. Multiple variables can use the same dimension, indicating that they were measured on the same grid. At most, one dimension can be unlimited, meaning that the length can be updated continually as more data is added. Attributes allow you to store metadata about the file or variables. They can be either scalar values or one-dimensional arrays.
A new, enhanced format was introduced with NetCDF 4. To remain backward-compatible, it is constructed from the classic format plus some extra bits. One of the extra bits is the introduction of groups. Groups are hierarchical structures of data, similar to the UNIX filesystem. The second extra part is the ability to define new data types. A NetCDF 4 file contains one top-level unnamed group. Every group can contain one or more named subgroups, user-defined types, variables, dimensions and attributes.
Some standard command-line utilities are available to allow you to work with your NetCDF files. The ncdump utility takes the binary NetCDF file and outputs a text file in a format called CDL. The ncgen utility takes a CDL text file and creates a binary NetCDF file. nccopy copies a NetCDF file and, in the process, allows you to change things like the binary format, chunk sizes and compression. There are also the NetCDF Operators (NCOs). This project consists of a number of small utilities that do some operation on a NetCDF file, such as concatenation, averaging or interpolation.
Here's a simple example of a CDL file:
netcdf simple_xy {
dimensions:
x = 6 ;
y = 12 ;
variables:
int data(x, y) ;
data:
data =
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,
12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23,
24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35,
36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47,
48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59,
60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71 ;
}
Once you have this defined, you can create the corresponding NetCDF file with the ncgen utility.
To use the library, you need to include the header file netcdf.h. The library function names start with nc_. To open a file, use nc_open(filename, access_mode, file_pointer). This gives you a file pointer that you can use to read from and write to the file. You then need to get a variable identifier with the function nc_inq_varid(file_pointer, variable_name, variable_identifier). Now you can actually read in the data with the function nc_get_var_int(file_pointer, variable_identifier, data_buffer), which will place the data into the data buffer in your code. When you're done, close the file with nc_close(file_pointer). All of these functions return error codes, and they should be checked after each execution of a library function.
Writing files is a little different. You need to start with nc_create, which gives you a file pointer. You then define the dimensions with the nc_def_dim function. Once these are all defined, you can go ahead and create the variables with the nc_def_var function. You need to close off the header with nc_enddef. Finally, you can start to write out the data itself with nc_put_var_int. Once all of the data is written out, you can close the file with nc_close
The Hierarchical Data Format (HDF) is another very common file format used in scientific data processing. It originally was developed at the National Center for Supercomputing Applications, and it is now maintained by the nonprofit HDF Group. All of the libraries and utilities are released under a BSD-like license. Two options are available: HDF4 and HDF5. HDF4 supports things like multidimensional arrays, raster images and tables. You also can create your own grouping structures called vgroups. The biggest limitation to HDF4 is that file size is limited to 2GB maximum. There also isn't a clear object structure, which limits the kind of data that can be represented. HDF5 simplifies the file format so that there are only two types of objects: datasets, which are homogeneous multidimensional arrays, and groups, which are containers that can hold datasets or other groups. The libraries have interfaces for C, C++, FORTRAN 77, FORTRAN 90 and Java, similar to NetCDF.
The file starts with a header, describing details of the file as a whole. Then, it will contain at least one data descriptor block, describing the details of the data stored in the file. The file then can contain zero or more data elements, which contain the actual data itself. A data descriptor block plus a data element block is represented as a data object. A data descriptor is 12-bytes long, made up of a 16-bit tag, a 16-bit reference number, a 32-bit data offset and a 32-bit data length.
Several command-line utilities are available for HDF files too. The hdp utility is like the ncdump utility. It gives a text dumping of the file and its data values. hdiff gives you a listing of the differences between two HDF files. hdfls shows information on the types of data objects stored in the file. hdfed displays the contents of an HDF file and gives you limited abilities to edit the contents. You can convert back and forth between HDF4 and HDF5 with the h4toh5 and h5toh4 utilities. If you need to compress the data, you can use the hdfpack program. If you need to alter options, like compression or chunking, you can use hrepack.
The library API for HDF is a bit more complex than for NetCDF. There is a low-level interface, which is similar to what you would see with NetCDF. Built on top of this is a whole suite of different interfaces that give you higher-level functions. For example, there is the scientific data sets interface, or SD. This provides functions for reading and writing data arrays. All of the functions begin with SD, such as SDcreate to create a new file. There are many other interfaces, such as for palettes (DFP) or 8-bit raster images (DFR8). There are far too many to cover here, but there is a great deal of information, including tutorials, that can help you get up to speed with HDF.
Hopefully now that you have seen these two file formats, you can start to use them in your own research. The key to expanding scientific understanding is the free exchange of information. And in this age, that means using common file formats that everyone can use. Now you can go out and set your data free too.
Although AutoCAD is the champion of the computer-aided design world, some alternatives are worth looking into. In fact, even a few open-source options manage to pack some decent features into an infinitely affordable solution.
QCAD from Ribbonsoft is one of those hybrid programs that has a fully functional GPL base (the Community Edition) and a commercial application, which adds functionality for a fee. On Linux, installing QCAD is usually as easy as a quick trip to your distro's package manager. For Windows users, however, Ribbonsoft offers source code, but nothing else. Thankfully, someone over at SourceForge has compiled QCAD for Windows, and it's downloadable from qcadbin-win.sourceforge.net.
For a completely free option, however, FreeCAD might be a better choice. With binaries available for Windows, OS X and Linux, FreeCAD is a breeze to distribute. In my very limited field testing, our local industrial arts teacher preferred FreeCAD over the other open-source alternatives, but because they're free, you can decide for yourself! Check out FreeCAD at free-cad.sourceforge.net.
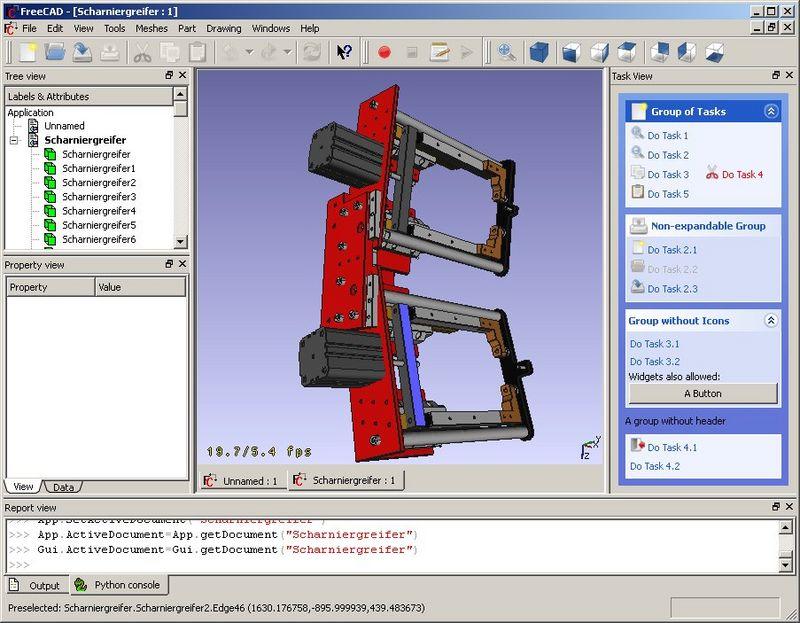
FreeCAD (screenshot from free-cad.sourceforge.net)
I am an impulse domain buyer. I tend to purchase silly names for simple sites that only serve the purpose of an inside joke. The thing about impulse-buying a domain is that DNS propagation generally takes a day or so, and setting up a Web site with a virtual hostname can be delayed while you wait for your Web site address to go “live”.
Thankfully, there's a simple solution: the /etc/hosts file. By manually entering the DNS information, you'll get instant access to your new domain. That doesn't mean it will work for the rest of the Internet before DNS propagation, but it means you can set up and test your Web site immediately. Just remember to delete the entry in /etc/hosts after DNS propagates, or you might end up with a stale entry when your novelty Web site goes viral and you have to change your Web host!
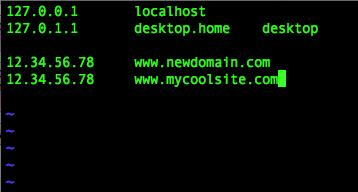
The format for /etc/hosts is self-explanatory, but you can add comments by preceding with a # character if desired.
In 2006, the family computer on which our digital photographs were stored had a hard drive failure. Because I'm obsessed with backups, it shouldn't have been a big deal, except that my backups had been silently failing for months. Although I certainly learned a lesson about verifying my backups, I also realized it would be nice to have an off-site storage location for our photos.
Move forward to 2010, and I realized storing our photos in the “cloud” would mean they were always safe and always accessible. Unfortunately, it also meant my family memories were stored by someone else, and I had to pay for the privilege of on-line access. Thankfully, there's an open-source project designed to fill my family's need, and it's a mature project that just celebrated its 10th anniversary!
Piwigo, formerly called PhpWebGallery, is a Web-based program designed to upload, organize and archive photos. It supports tagging, categories, thumbnails and pretty much every other on-line sorting tool you can imagine. Piwigo has been around long enough that there even are third-party applications that support it out of the box. Want mobile support? The Web site has a mobile theme built in. Want a native app for your phone? iOS and Android apps are available. In fact, with its numerous extensions and third-party applications, Piwigo rivals sites like Flickr and Picasaweb when it comes to flexibility. Plus, because it's open source, you control all your data.
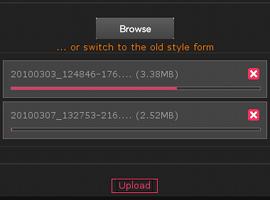
Piwigo supports direct upload of multiple files, but it also supports third-party upload utilities (screenshot courtesy of www.piwigo.org).
Categories, tags, albums and more are available to organize your photos (screenshot courtesy of www.piwigo.org).
If you haven't considered Piwigo, you owe it to yourself to try. It's simple to install, and if you have a recent version of Linux, your distribution might have it by default in its repositories. Thanks to its flexibility, maturity and downright awesomeness, Piwigo gets this month's Editors' Choice award. Check it out today at www.piwigo.org.
We recently asked LinuxJournal.com readers about their networking preferences, and after calculating the results, we have some interesting findings to report. From a quick glance, we can see that our readers like their Internet fast, their computers plentiful and their firewalls simple.
One of the great things about Linux Journal readers and staff is that we all have a lot in common, and one of those things is our love of hardware. We like to have a lot of it, and I suspect we get as much use out of it as we can before letting go, and thus accumulate a lot of machines in our houses. When asked how many computers readers have on their home networks, the answer was, not surprisingly, quite a few! The most popular answer was 4–6 computers (44% of readers); 10% of readers have more than 10 computers on their home networks (I'm impressed); 14% of readers have 7–9 running on their networks, and the remaining 32% of readers have 1–3 computers
We also asked how many of our surveyed readers have a dedicated server on their home networks, and a slight majority, 54%, responded yes. I'm pleased to know none of us are slacking on our home setups in the least!
Understandably, these impressive computing environments need serious speed. And while the most common Internet connection speed among our surveyed readers was a relatively low 1–3mbps (17% of responses), the majority of our readers connect at relatively fast speeds. The very close second- and third-most-common speeds were 6–10mbps and an impressive more than 25mbps, respectively, and each representing 16% of responses. A similarly large number of surveyed readers were in the 10–15mbps and 15–25mbps ranges, so we're glad to know so many of you are getting the most out of your Internet experience.
The vast majority of our readers use cable and DSL Internet services. Cable was the slight leader at 44% vs. 41% for DSL. And 12% of readers have a fiber connection—and to the mountain-dwelling Canadian reader connected via long-range Wi-Fi 8km away, I salute you! Please send us photos of your view.
The favorite wireless access point vendor is clearly Linksys, with 30% of survey readers using some type of Linksys device. NETGEAR and D-Link have a few fans as well, each getting 15% of the delicious response pie. And more than a handful of you pointed out that you do not use any wireless Internet. I admit, I'm intrigued.
Finally, when asked about your preferred firewall software/appliance, the clear winner was “Stock Router/AP Firmware” with 41% of respondents indicating this as their preferred method. We respect your tendency to keep it simple. In a distant second place, with 15%, was a custom Linux solution, which is not surprising given our readership's penchant for customization in all things.
Thanks to all who participated, and please look to LinuxJournal.com for future polls and surveys.
Building one space station for everyone was and is insane: we should have built a dozen.
—Larry Niven
Civilization advances by extending the number of important operations which we can perform without thinking of them.
—Alfred North Whitehead
Do you realize if it weren't for Edison we'd be watching TV by candlelight?
—Al Boliska
And one more thing...
—Steve Jobs
All right everyone, line up alphabetically according to your height.
—Casey Stengel
Looking for software recommendations, apps and generally useful stuff? Visit www.linuxjournal.com/editors-choice to find articles highlighting various technology that merits our Editors' Choice seal of approval. We think you'll find this listing to be a valuable resource for discovering and vetting software, products and apps. We've run these things through the paces and chosen only the best to highlight so you can get right to the good stuff.
Do you know a product, project or vendor that could earn our Editors' Choice distinction? Please let us know at info@linuxjournal.com.