A high-availability stack serves one purpose: through a redundant setup of two or more nodes, ensure service availability and recover services automatically in case of a problem. Florian Haas explores Pacemaker, the state-of-the-art high-availability stack on Linux.
Hardware and software are error-prone. Eventually, a hardware issue or software bug will affect any application. And yet, we're increasingly expecting services—the applications that run on top of our infrastructure—to be up 24/7 by default. And if we're not expecting that, our bosses and our customers are. What makes this possible is a high-availability stack: it automatically recovers applications and services in the face of software and hardware issues, and it ensures service availability and uptime. The definitive open-source high-availability stack for the Linux platform builds upon the Pacemaker cluster resource manager. And to ensure maximum service availability, that stack consists of four layers: storage, cluster communications, resource management and applications.
The storage layer is where we keep our data. Individual cluster nodes access this data in a joint and coordinated fashion. There are two fundamental types of cluster storage:
Single-instance storage is perhaps the more conventional form of cluster storage. The cluster stores all its data in one centralized instance, typically a volume on a SAN. Access to this data is either from one node at a time (active/passive) or from multiple nodes simultaneously (active/active). The latter option normally requires the use of a shared-cluster filesystem, such as GFS2 or OCFS2. To prevent uncoordinated access to data—a sure-fire way of shredding it—all single-instance storage cluster architectures require the use of fencing. Single-instance storage is very easy to set up, specifically if you already have a SAN at your disposal, but it has a very significant downside: if, for any reason, data becomes inaccessible or is even destroyed, all server redundancy in your high-availability architecture comes to naught. With no data to serve, a server becomes just a piece of iron with little use.
Replicated storage solves this problem. In this architecture, there are two or more replicas of the cluster data set, with each cluster node having access to its own copy of the data. An underlying replication facility then guarantees that the copies are exactly identical at the block layer. This effectively makes replicated storage a drop-in replacement for single-instance storage, albeit with added redundancy at the data level. Now you can lose entire nodes—with their data—and still have more nodes to fail over to. Several proprietary (hardware-based) solutions exist for this purpose, but the canonical way of achieving replicated block storage on Linux is the Distributed Replicated Block Device (DRBD). Storage replication also may happen at the filesystem level, with GlusterFS and Ceph being the most prominent implementations at this time.
The cluster communications layer serves three primary purposes: it provides reliable message passing between cluster nodes, establishes the cluster membership and determines quorum. The default cluster communications layer in the Linux HA stack is Corosync, which evolved out of the earlier, now all but defunct, OpenAIS Project.
Corosync implements the Totem single-ring ordering and membership protocol, a well-studied message-passing algorithm with almost 20 years of research among its credentials. It provides a secure, reliable means of message passing that guarantees in-order delivery of messages to cluster nodes. Corosync normally transmits cluster messages over Ethernet links by UDP multicast, but it also can use unicast or broadcast messaging, and even direct RDMA over InfiniBand links. It also supports redundant rings, meaning clusters can use two physically independent paths to communicate and transparently fail over from one ring to another.
Corosync also establishes the cluster membership by mutually authenticating nodes, optionally using a simple pre-shared key authentication and encryption scheme. Finally, Corosync establishes quorum—it detects whether sufficiently many nodes have joined the cluster to be operational.
In high availability, a resource can be something as simple as an IP address that “floats” between cluster nodes, or something as complex as a database instance with a very intricate configuration. Put simply, a resource is anything that the cluster starts, stops, monitors, recovers or moves around. Cluster resource management is what performs these tasks for us—in an automated, transparent, highly configurable way. The canonical cluster resource manager in high-availability Linux is Pacemaker.
Pacemaker is a spin-off of Heartbeat, the high-availability stack formerly driven primarily by Novell (which then owned SUSE) and IBM. It re-invented itself as an independent and much more community-driven project in 2008, with developers from Red Hat, SUSE and NTT now being the most active contributors.
Pacemaker provides a distributed Cluster Information Base (CIB) in which it records the configuration and status of all cluster resources. The CIB replicates automatically to all cluster nodes from the Designated Coordinator (DC)—one node that Pacemaker automatically elects from all available cluster nodes.
The CIB uses an XML-based configuration format, which in releases prior to Pacemaker 1.0 was the only way to configure the cluster—something that rightfully made potential users run away screaming. Since these humble beginnings, however, Pacemaker has grown into a tremendously useful, hierarchical, self-documenting text-based shell, somewhat akin to the “virsh” subshell that many readers will be familiar with from libvirt. This shell—unimaginatively called “crm” by its developers—hides all that nasty XML from users and makes the cluster much simpler and easier to configure.
In Pacemaker, the shell allows us to configure cluster resources—no surprise there—and operations (things the cluster does with resources). Besides, we can set per-node and cluster-wide attributes, send nodes into a standby mode where they are temporarily ineligible for running resources, manipulate resource placement in the cluster, and do a plethora of other things to manage our cluster.
Finally, Pacemaker's Policy Engine (PE) recurrently checks the cluster configuration against the cluster status and initiates actions as required. The PE would, for example, kick off a recurring monitor operation on a resource (such as, “check whether this database is still alive”); evaluate its status (“hey, it's not!”); take into account other items in the cluster configuration (“don't attempt to recover this specific resource in place if it fails more than three times in 24 hours”); and initiate a follow-up action (“move this database to a different node”). All these steps are entirely automatic and require no human intervention, ensuring quick resource recovery and maximum uptime.
At the cluster resource management level, Pacemaker uses an abstract model where resources all support predefined, generic operations (such as start, stop or check the status) and produce standardized return codes. To translate these abstract operations into something that is actually meaningful to an application, we need resource agents.
Resource agents are small pieces of code that allow Pacemaker to interact with an application and manage it as a cluster resource. Resource agents can be written in any language, with the vast majority being simple shell scripts. At the time of this writing, more than 70 individual resource agents ship with the high-availability stack proper. Users can, however, easily drop in custom resource agents—a key design principle in the Pacemaker stack is to make resource management easily accessible to third parties.
Resource agents translate Pacemaker's generic actions into operations meaningful for a specific resource type. For something as simple as a virtual “floating” IP address, starting up the resource amounts to assigning that address to a network interface. More complex resource types, such as those managing database instances, come with much more intricate startup operations. The same applies to varying implementations of resource shutdown, monitoring and migration: all these operations can range from simple to complex, depending on resource type.
This reference configuration consists of a three-node cluster with single-instance iSCSI storage. Such a configuration is easily capable of supporting more than 20 highly available virtual machine instances, although for the sake of simplicity, the configuration shown here includes only three. You can complete this configuration on any recent Linux distribution—the Corosync/Pacemaker stack is universally available on CentOS 6,[1] Fedora, OpenSUSE and SLES, Debian, Ubuntu and other platforms. It is also available in RHEL 6, albeit as a currently unsupported Technology Preview. Installing the pacemaker, corosync, libvirt, qemu-kvm and open-iscsi packages should be enough on all target platforms—your preferred package manager will happily pull in all package dependencies.
This example assumes that all three cluster nodes—alice, bob and charlie—have iSCSI access to a portal at 192.168.122.100:3260, and are allowed to connect to the iSCSI target whose IQN is iqn.2011-09.com.hastexo:virtcluster. Further, three libvirt/KVM virtual machines—xray, yankee and zulu—have been pre-installed, and each uses one of the volumes (LUNs) on the iSCSI target as its virtual block device. Identical copies of the domain configuration files exist in the default configuration directory, /etc/libvirt/qemu, on all three physical nodes.
Corosync's configuration files live in /etc/corosync, and the central configuration is in /etc/corosync/corosync.conf. Here's an example of the contents of this file:
totem {
# Enable node authentication & encryption
secauth: on
# Redundant ring protocol: none, active, passive.
rrp_mode: active
# Redundant communications interfaces
interface {
ringnumber: 0
bindnetaddr: 192.168.0.0
mcastaddr: 239.255.29.144
mcastport: 5405
}
interface {
ringnumber: 1
bindnetaddr: 192.168.42.0
mcastaddr: 239.255.42.0
mcastport: 5405
}
}
amf {
mode: disabled
}
service {
# Load Pacemaker
ver: 1
name: pacemaker
}
logging {
fileline: off
to_stderr: yes
to_logfile: no
to_syslog: yes
syslog_facility: daemon
debug: off
timestamp: on
}
The important bits here are the two interface declarations enabling redundant cluster communications and the corresponding rrp_mode declaration. Mutual node authentication and encryption (secauth on) is good security practice. And finally, the service stanza loads the Pacemaker cluster manager as a Corosync plugin.
With secauth enabled, Corosync also requires a shared secret for mutual node authentication. Corosync uses a simple 128-byte secret that it stores as /etc/corosync/authkey, and which you easily can generate with the corosync-keygen utility.
Once corosync.conf and authkey are in shape, copy them over to all nodes in your prospective cluster. Then, fire up Corosync cluster communications—a simple service corosync start will do.
Once the service is running on all nodes, the command corosync-cfgtool -s will display both rings as healthy, and the cluster is ready to communicate:
Printing ring status.
Local node ID 303938909
RING ID 0
id = 192.168.0.1
status = ring 0 active with no faults
RING ID 1
id = 192.168.42.1
status = ring 1 active with no faults
Once Corosync runs, we can start Pacemaker with the service pacemaker start command. After a few seconds, Pacemaker elects a Designated Coordinator (DC) node among the three available nodes and commences full cluster operations. The crm_mon utility, executable on any cluster node, then produces output similar to this:
============ Last updated: Fri Feb 3 18:40:15 2012 Stack: openais Current DC: bob - partition with quorum Version: 1.1.6-4.el6-89678d4947c5bd466e2f31acd58ea4e1edb854d5 3 Nodes configured, 3 expected votes 0 Resources configured. ============
The output produced by crm_mon is a more user-friendly representation of the internal cluster configuration and status stored in a distributed XML database, the Cluster Information Base (CIB). Those interested and brave enough to care about the internal representation are welcome to make use of the cibadmin -Q command. But be warned, before you do so, you may want to instruct the junior sysadmin next to you to get some coffee—the avalanche of XML gibberish that cibadmin produces can be intimidating to the uninitiated novice.
Much less intimidating is the standard configuration facility for Pacemaker, the crm shell. This self-documenting, hierarchical, scriptable subshell is the simplest and most universal way of manipulating Pacemaker clusters. In its configure submenu, the shell allows us to load and import configuration snippets—or even complete configurations, as below:
primitive p_iscsi ocf:heartbeat:iscsi \
params portal="192.168.122.100:3260" \
target="iqn.2011-09.com.hastexo:virtcluster" \
op monitor interval="10"
primitive p_xray ocf:heartbeat:VirtualDomain \
params config="/etc/libvirt/qemu/xray.xml" \
op monitor interval="30" timeout="30" \
op start interval="0" timeout="120" \
op stop interval="0" timeout="120"
primitive p_yankee ocf:heartbeat:VirtualDomain \
params config="/etc/libvirt/qemu/yankee.xml" \
op monitor interval="30" timeout="30" \
op start interval="0" timeout="120" \
op stop interval="0" timeout="120"
primitive p_zulu ocf:heartbeat:VirtualDomain \
params config="/etc/libvirt/qemu/zulu.xml" \
op monitor interval="30" timeout="30" \
op start interval="0" timeout="120" \
op stop interval="0" timeout="120"
clone cl_iscsi p_iscsi
colocation c_xray_on_iscsi inf: p_xray cl_iscsi
colocation c_yankee_on_iscsi inf: p_yankee cl_iscsi
colocation c_zulu_on_iscsi inf: p_zulu cl_iscsi
order o_iscsi_before_xray inf: cl_iscsi p_xray
order o_iscsi_before_yankee inf: cl_iscsi p_yankee
order o_iscsi_before_zulu inf: cl_iscsi p_zulu
Besides defining our three virtual domains as resources under full cluster management and monitoring (p_xray, p_yankee and p_zulu), this configuration also ensures that all domains can find their storage (the cl_iscsi clone), and that they wait until iSCSI storage becomes available (the order and colocation constraints).
This being a single-instance storage cluster, it's imperative that we also employ safeguards against shredding our data. This is commonly known as node fencing, but Pacemaker uses the more endearing term STONITH (Shoot The Other Node In The Head) for the same concept. A ubiquitous means of node fencing is controlling nodes via their IPMI Baseboard Management Controllers, and Pacemaker supports this natively:
primitive p_ipmi_alice stonith:external/ipmi \
params hostname="alice" ipaddr="192.168.15.1" \
userid="admin" passwd="foobar" \
op start interval="0" timeout="60" \
op monitor interval="120" timeout="60"
primitive p_ipmi_bob stonith:external/ipmi \
params hostname="bob" ipaddr="192.168.15.2" \
userid="admin" passwd="foobar" \
op start interval="0" timeout="60" \
op monitor interval="120" timeout="60"
primitive p_ipmi_charlie stonith:external/ipmi \
params hostname="charlie" ipaddr="192.168.15.3" \
userid="admin" passwd="foobar" \
op start interval="0" timeout="60" \
op monitor interval="120" timeout="60"
location l_ipmi_alice p_ipmi_alice -inf: alice
location l_ipmi_bob p_ipmi_bob -inf: bob
location l_ipmi_charlie p_ipmi_charlie -inf: charlie
property stonith-enabled="true"
The three location constraints here ensure that no node has to shoot itself.
Once that configuration is active, Pacemaker fires up resources as determined by the cluster configuration. Again, we can query the cluster state with the crm_mon command, which now produces much more interesting output than before:
============
Last updated: Fri Feb 3 19:46:29 2012
Stack: openais
Current DC: bob - partition with quorum
Version: 1.1.6-4.el6-89678d4947c5bd466e2f31acd58ea4e1edb854d5
3 Nodes configured, 3 expected votes
9 Resources configured.
============
Online: [ alice bob charlie ]
Clone Set: cl_iscsi [p_iscsi]
Started: [ alice bob charlie ]
p_ipmi_alice (stonith:external/ipmi): Started bob
p_ipmi_bob (stonith:external/ipmi): Started charlie
p_ipmi_charlie (stonith:external/ipmi): Started alice
p_xray (ocf::heartbeat:VirtualDomain): Started alice
p_yankee (ocf::heartbeat:VirtualDomain): Started bob
p_zulu (ocf::heartbeat:VirtualDomain): Started charlie
Note that by default, Pacemaker clusters are symmetric. The resource manager balances resources in a round-robin fashion among cluster nodes.
This configuration protects against both resource and node failure. If one of the virtual domains crashes, Pacemaker recovers the KVM instance in place. If a whole node goes down, Pacemaker reshuffles the resources so the remaining nodes take over the services that the failed node hosted. In the screen dump below, charlie has failed and bob has duly taken over the virtual machine that charlie had hosted:
============
Last updated: Sat Feb 4 16:18:00 2012
Stack: openais
Current DC: bob - partition with quorum
Version: 1.1.6-4.el6-89678d4947c5bd466e2f31acd58ea4e1edb854d5
3 Nodes configured, 2 expected votes
9 Resources configured.
============
Online: [ alice bob ]
OFFLINE: [ charlie ]
Full list of resources:
Clone Set: cl_iscsi [p_iscsi]
Started: [ alice bob ]
Stopped: [ p_iscsi:2 ]
p_ipmi_alice (stonith:external/ipmi): Started bob
p_ipmi_bob (stonith:external/ipmi): Started alice
p_ipmi_charlie (stonith:external/ipmi): Started alice
p_xray (ocf::heartbeat:VirtualDomain): Started bob
p_yankee (ocf::heartbeat:VirtualDomain): Started bob
p_zulu (ocf::heartbeat:VirtualDomain): Started alice
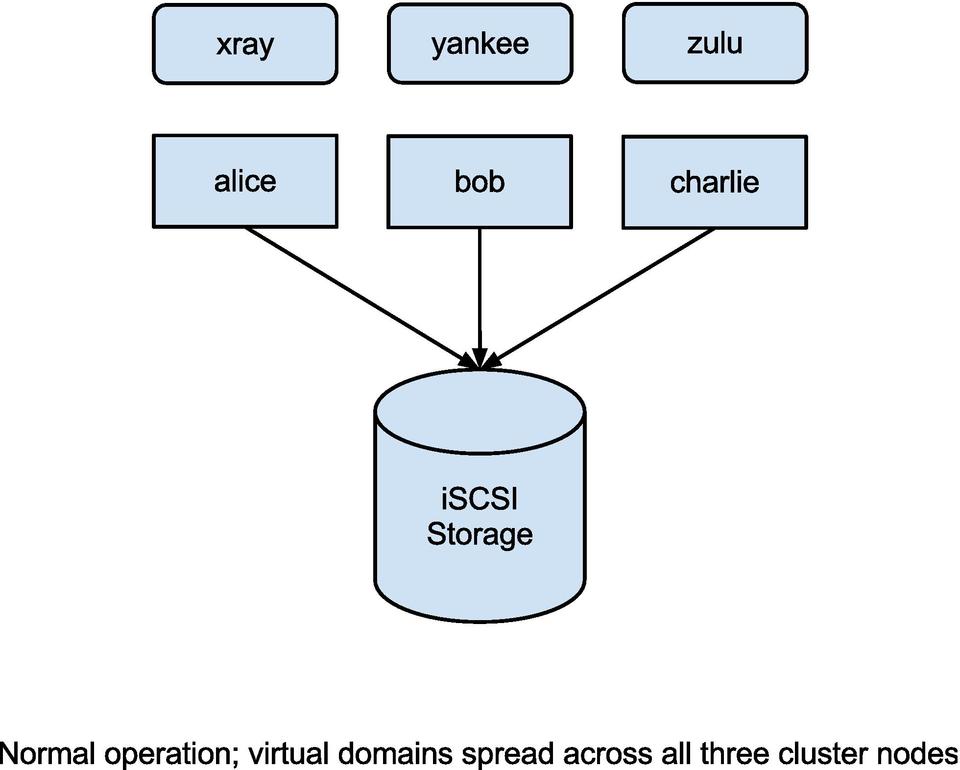
Figure 1. Normal operation; virtual domains spread across all three cluster nodes.
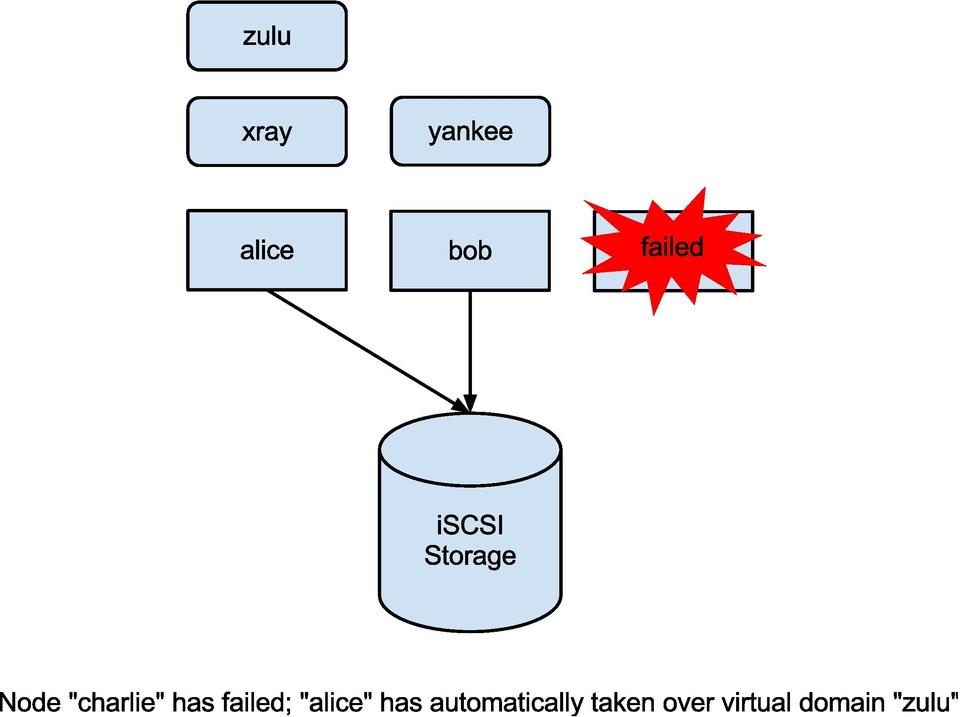
Figure 2. Node charlie has failed; alice has automatically taken over virtual domain zulu.
Once the host charlie recovers, resources can optionally shift back to the recovered host automatically, or they can stay in place until an administrator reassigns them at the time of her choosing.
In this article, I barely scratched the surface of the Linux high-availability stack's capabilities. Pacemaker supports a diverse set of recovery policies, resource placement strategies and cluster constraints, making the stack enormously powerful.