Tim Bird has started up the Android Mainlining Project, an attempt to create an organized flow of Android features back into the main kernel source. One of Linux's most fun qualities is that it'll compile and run unmodified on more devices than you can count. This is rarely by chance. In most cases, someone, or several people, are responsible for maintaining support on that architecture. Usually, that support is developed inside the official kernel from the start. In the case of the Android OS, Google forked off a copy of the kernel sources and had its teams make the extensive modifications necessary to run on Android devices. Given the high degree of “drift” that tends to come between code bases when that happens, Tim's project is pretty timely. Eventually, the entire Android OS may be reduced to a simple set of configuration variables and a lot of userspace software. Currently, it's configuration variables, userspace software and a whole lot of kernel patches.
Linus Torvalds once said that Al Viro had the uncanny ability to organize his kernel patches so that each one did some small thing that was obviously good. Although the great mass of his patches, taken as a whole, somehow also would manage to advance the kernel at large, advancing the broader goals of developing the VFS (Virtual Filesystem).
The VFS is not necessarily glamorous work, existing as it does almost entirely beneath anything the user can actually see. But, Al's work forms the underpinnings of every filesystem supported by Linux.
One little invisible thing he did lately was start cleaning up the vfsmount data structure, so that it wouldn't export a lot of VFS-specific data to the wider kernel world, but would take the cleaner approach of exporting only the data that non-VFS code might actually need. And, in keeping with Linus' comment of long ago, he was organizing the change so as to cause the smallest possible impact on the rest of the kernel, while paving the way for further cleanups in the future.
What often happens with complex new technologies is that several people get different ideas about how to support them, and they start coding up those competing ideas, until one of them turns out to be the better way. Virtualization is one of those areas. Running other OSes under Linux used to be “virtually” impossible, or else there were frustrating partial solutions that tried to emulate a particular OS under Linux, with varying degrees of success. But, now there are things like Xen and KVM, so running another OS under Linux is trivial. As these projects continue to grow, however, their incompatibilities tend to stand out against each other. Some kernels run better under Xen than KVM, and vice versa. So, when Stefano Stabellini recently announced a port of Xen to the Cortez-A15 ARM processor, the resulting technical discussion on the mailing list tended to focus a bit on getting Xen and KVM to play nicely together.
Another area where multiple visions have been realized in the official kernel tree is with display drivers. Between OMAP, DRM and framebuffer projects, no one can agree on which code base should be used to provide a more general display infrastructure that the others could be built on top of. Apparently, there's plenty of bad blood to go around, and all the projects think that they are the most natural choice for the job.
Recently, the topic came up again when Tomi Valkeinen, author of the OMAP display driver, suggested using OMAP as the framework for all display drivers. Of course, the DRM and framebuffer folks thought that would be a bad idea, and a full-throated debate ensued.
Ultimately, through some mediation by Alan Cox, the decision seems to have been made just to focus on making all three of those systems more and more compatible with each other. This is a clever idea, because it's hard to argue against greater compatibility. While at the same time, as the different implementations become more similar, it should become clearer and clearer which one truly would be the better choice to provide an underlying infrastructure for the others.
I've mentioned before that I keep my entire e-book collection in my Dropbox folder, and I can access it anywhere I have a Web connection. I didn't come up with the idea myself; instead, I shamelessly stole the idea from Bill Childers. I suspect he stole it from someone else, so feel free to steal the idea from me.
Basically, it involves two programs, both free (well, three, if you count Dropbox). First, create a folder inside your Public folder that resides in your Dropbox folder. You can name this folder anything you like, but because it will be hosting all your e-books, it's wise to name it something no one would guess.
Then, in Calibre, click on the bookshelf icon (upper left), and click “switch library”. Then, select that new secret folder you made inside your Public Dropbox folder. Calibre will move your entire library to that folder, so make sure you have enough free space in your Dropbox to handle your entire e-book collection. If you have too many e-books, you could create a separate library inside Calibre and just keep a select few books in that Public folder.
Now you should have a working install of Calibre that stores your e-books and database inside your Dropbox. You simply can open this library file with Calibre on other computers that sync with Dropbox, or you can go one step further and create a cloud-based repository that you can browse from any computer. And, that's where calibre2opds comes into play.
calibre2opds is a Java application that creates a Web site from your Calibre library. Download the Java application from www.calibre2opds.com, and launch it with your favorite Java runtime environment. Once it's launched, you'll see many options for tweaking how your library will look. The first thing you need to do is make sure the Database Folder is pointed to the secret folder to which you moved your Calibre library. Then, you'll want to set the Catalog Folder to something. It's okay to leave it set to _catalog, which is the default.
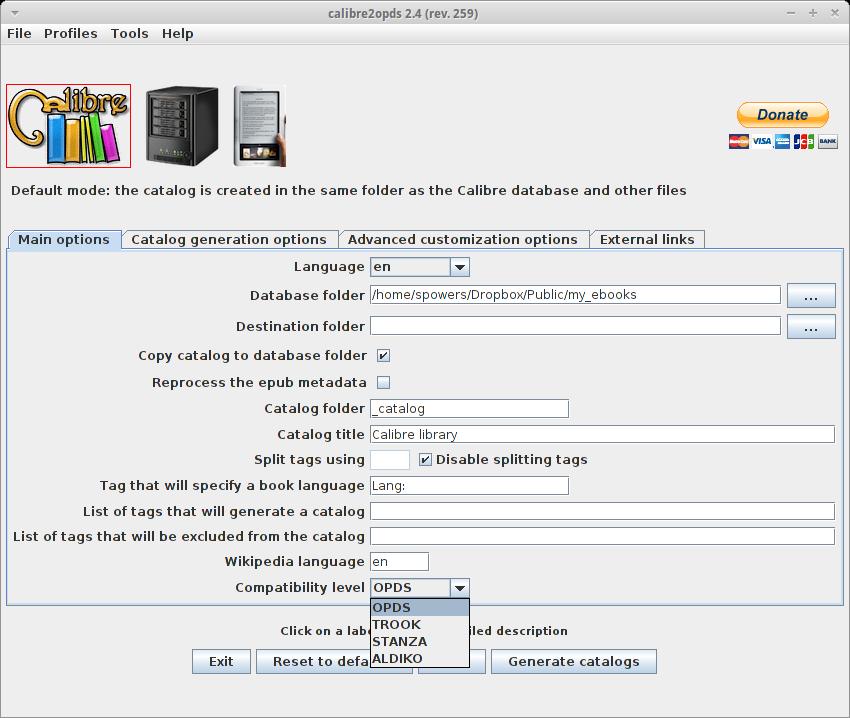
Figure 1. calibre2opds is a GUI Java application.
Next, you need to decide what sort of Web site you want to create. If you want to be able to browse it with any Web browser, leave the “Compatibility Level” at “OPDS”. If you want to browse directly with your Android device, you can choose either TROOK or ALDIKO, and calibre2opds will generate a catalog that those readers can access directly. Once you tweak any other settings to your liking, click the Generate Catalogs button on the bottom, and it will create all the files you need right inside your Calibre database folder.
Because you did all this inside your Public Dropbox folder, you can look for that _catalog folder and find the index.html file inside it. Right-click on index.html, get the Dropbox public link for it, and see the result. (Note: you may need to find the index.xml file if you're trying to browse with Aldiko or Trook.)
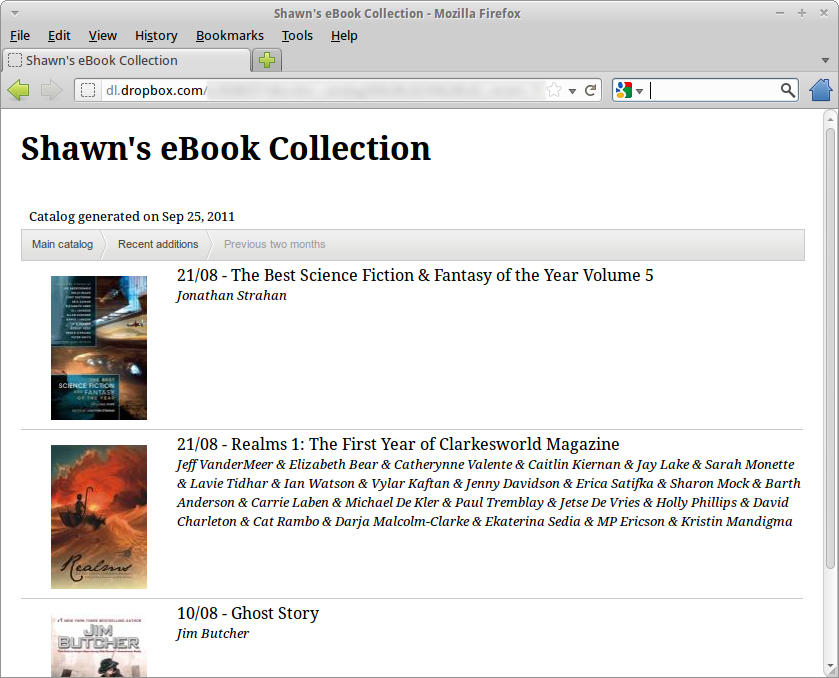
Figure 2. Here is my e-book collection, created by calibre2opds.
Most people have heard of gold. Most people are familiar with dollars. For a handful of geeky folks, however, the currency they hope will become a global standard is digital. Whether it's a problem or not, the currency you use on a day-to-day basis is tied to the government. The global value of the money in your pocket can vary widely, and if you're a conspiracy theorist, your concern might be that it could be worth nothing in the blink of an eye.
Surely gold and silver are wise investments if you're concerned your paper dollars will drop in value, but using gold as a means to buy a gallon of milk is a bit difficult. Perhaps cryptocurrencies are the solution. The most popular form of cryptocurrency is the Bitcoin. A very simple explanation of how it works is as follows:
Users download the bitcoin client and use their computer to solve complex math problems, which create a cryptographic record of any transactions on the Bitcoin P2P network.
Users are rewarded Bitcoins for successfully “hashing” the cryptographic record of transactions, and that reward system is how Bitcoins are created.
Users then securely transfer Bitcoins back and forth to purchase items, and those transactions are recorded in the cryptographic history for the entire P2P network to see.
The process is, of course, a little more complicated than that, but that's basically how it works. The computers creating the cryptographic history of transactions are called miners, and “Bitcoin Mining” is simply the act of solving complex math problems in order to make a cryptographic record of transactions. Because mining Bitcoins is how the currency is created, lots of people are connected to the network, racing each other to get a solution that will generate a reward. In fact, it's so competitive, that unless you have a high-end GPU that can process the equations extremely fast, there is no point in trying for the rewards.
Are Bitcoins the future of global currencies? Will one of the alternative cryptocurrencies like Litecoin or Solidcoin become commonplace? The number of places that accept cryptocurrencies are extremely limited, so it's not any easier to buy a gallon of milk with a Bitcoin than it is with a lump of gold, but many think that day is coming. What about you? Do you think cryptocurrency has a future, or do you think it's a geeky fad that will fade away? Send an e-mail with “CRYPTOCURRENCY” in the subject line to info@linuxjournal.com, and I'll follow up with a Web article based on your feedback. For more information on cryptocurrencies, check out these Web sites: www.bitcoin.org, www.litecoin.org and www.solidcoin.org.

If you want to record your Windows screen, but don't want to fork out the money for a commercial application like Camtasia, you might want to give CamStudio a try. CamStudio is an open-source program that captures your Windows desktop and encodes the video using an open-source video codec.
CamStudio has many features, including picture-in-picture support for folks with Webcams. If you're using Windows on one of your computers and want to try out some open-source screen capturing, give CamStudio a try. Download it at www.camstudio.org or from SourceForge at www.sourceforge.net/projects/camstudio.

My last article introduced the GNU Scientific Library and how to include it in your code, but I didn't really cover what you actually can do with this library. Here, I describe some of the available functionality, which hopefully will spark your interest in taking a deeper look.
A series of functions exist for handling polynomials. A polynomial is a function of different powers of a variable, with each element multiplied by a constant—for example:
P(x) = c[0] + c[1]*x + c[2]*x2 + ...
In the GSL, a polynomial is represented by an array containing all of the constants, with zeros for all of the missing powers. So, if your polynomial is P(x) = 5 + x3, your polynomial would be represented by c = [5,0,0,1]. Several functions are available for evaluating your polynomial at some particular value of x. And, there are separate functions for evaluating your function for real values of x (gsl_poly_eval), complex values of x (gsl_poly_complex_eval) and complex values of x with complex coefficients (gsl_complex_poly_complex_eval). This is because complex numbers are separate data types (gsl_complex) and need to be handled differently from simple doubles.
Aside from evaluating polynomials, you may want to solve the polynomial and get the roots of your equation. The most basic example is finding the roots of a quadratic equation. These roots may be real or complex, which means there are two different functions: gsl_poly_solve_quadratic and gsl_poly_complex_solve_quadratic. You hand in the values for the three coefficients and pointers to two variables to hold the two possible roots:
gsl_poly_solve_quadratic(double a, double b, ↪double c, double *x0, double *x1)
If there are no real roots, x0 and x1 are unchanged. Otherwise, the roots are placed successively into x0, and then x1. There are equivalent functions to find the roots of a quadratic equation called gsl_poly_solve_cubic and gsl_poly_solve_complex_cubic.
Once you get beyond a quadratic equation, there is no analytical way to find the roots of a polynomial equation. The GSL provides an iterative method to find the approximate locations of the roots of a higher order polynomial. But, you need to set up some scratch memory that can be used for this purpose. For a polynomial with n coefficients, you would use gsl_poly_complex_workspace_alloc(n) to create this scratch space. Then, you can call gsl_poly_complex_solve to run this process. After you are done, you would need to call gsl_poly_complex_workspace_free to free up this scratch space.
In science, lots of special functions are used in solving problems, and the GSL has support for dozens of functions. To use them, start by including gsl_sf.h in your source code. These functions can be called in two different ways. You can call them directly and simply get the computed value as a result. So, if you wanted to calculate the value of a Bessel function, you could use this:
double ans = gsl_sf_bessel_J0(x);
But, you will have no idea if there were any problems during this computation. To get that information, you would call a variant of this function:
gsl_sf_result result; int status = gsl_sf_bessel_J0_e(x, &result);
The value of status lets you know if there were any error conditions, like overflow, underflow or loss of precision. If there were no errors, the function call returns GSL_SUCCESS. The result variable is actually a struct, with members val (the computed value of the function) and err (an estimate of the absolute error in val). All of the special functions default to evaluating with double precision, but in some cases, this is simply too costly time-wise. In order to save time in cases where a lower level of accuracy is acceptable, the GSL special functions can accept a mode argument:
GSL_PREC_DOUBLE — double precision, accuracy of 2*10-16.
GSL_PREC_SINGLE — single precision, accuracy of 10-7.
GSL_PREC_APPROX — approximate values, accuracy of 5*10-4.
Some of the special functions supported by the GSL include Airy functions, Bessel functions, Debye functions, elliptic integrals, exponential functions, Fermi-Dirac functions, Legendre functions, spherical harmonics and many more. It's definitely worth taking a look at the manual before you even think about writing your own version of some function, because it's very likely already been done for you.
Vectors and matrices are used as data types in several scientific problems. The GSL has support for doing calculations with both vectors and matrices, treating them as new data types. They are both based on a data type called a block. A GSL block is a struct containing the size of the block, along with a pointer to the memory location where the block is actually stored. A vector is a struct defined as:
typedef struct {
size_t size; /* number of elements in the vector */
size_t stride; /* step size from one element to the next */
double *data; /* location of the first element */
gsl_block *block; /* location of block if data
is stored in a block */
int owner; /* do I own this block */
} gsl_vector;
If owner equals 1, the associated block is freed when the vector is freed. Otherwise, the associated block is left alone when the vector is freed. Because of the complexity of the structure, there are special functions to handle vectors. The function gsl_vector_alloc(n) creates a vector of size n, with the data stored in the block member and the owner flag set to 1. The function gsl_vector_free() frees the previously created vector structure. To manipulate individual elements of your new vector, you need to use the functions gsl_vector_get(const gsl_vector *v, size_t i) and gsl_vector_set(gsl_vector *v, size_t i, double x). If you instead want a pointer to an element, you can use gsl_vector_ptr(gsl_vector *v, size_t i). Matrices are very similar, being defined as:
typedef struct {
size_t size1; /* number of rows */
size_t size2; /* number of columns */
size_t tda; /* number of bytes for one row */
double *data; /* location of matrix data */
gsl_block *block; /* underlying storage block */
int owner; /* do I own this block */
} gsl_matrix;
Matrices are stored in row-major order, which is the way it is done in C. Allocation and deallocation are handled by the functions gsl_matrix_alloc() and gsl_matrix_free(). Accessing elements are handled through the functions gsl_matrix_get() and gsl_matrix_set().
Now that you have vectors and matrices, what can you do with them? The GSL has support for the BLAS library (Basic Linear Algebra Subprograms). There is a wrapped version, accessible through gsl_blas.h, where you can use GSL vectors and matrices in the functions. You also have access to the raw BLAS functions through the include file gsl_cblas.h. The GSL version treats all matrices as dense matrices, so if you want to use band-format or packed-format matrices, you need to use the raw functions. There are three levels of BLAS operations:
Level 1: vector operations.
Level 2: matrix-vector operations.
Level 3: matrix-matrix operations.
BLAS has functions for things like dot products, vector sums and cross products. This provides the base for the linear algebra functions in the GSL. They are declared in the header gsl_linalg.h and are handled through level-1 and level-2 BLAS calls. There are functions for decomposition (LU, QR, singular value, Cholesky, tridiagonal and Hessenberg), Householder transformations and balancing. The header file gsl_eigen.h provides functions for calculating eigenvalues and eigenvectors of matrices. There are versions for real symmetric, real nonsymmetric, complex hermitian and real generalized nonsymmetric eigensystems, among others.
The last thing to look at is the functionality supporting calculus calculations. A whole group of functions handles numerical integration, and there are routines for both adaptive and non-adaptive integration for general functions. There also are specialized versions for special cases like infinite ranges, singular integrals and oscillatory integrals. The types of errors that may happen when you are trying to do a numerical integration are:
GSL_EMAXITER — the maximum number of subdivisions was exceeded.
GSL_EROUND — cannot reach tolerance because of round-off error.
GSL_ESING — a non-integrable singularity or bad integrand behavior.
GSL_EDIVERGE — integral is divergent or doesn't converge quickly enough.
Numerical differentiation also can be done, using finite differencing. These functions are adaptive, trying to find the most accurate result. The three versions are:
gsl_deriv_central() — central difference algorithm.
gsl_deriv_forward() — adaptive forward difference algorithm.
gsl_deriv_backward() — adaptive backward difference algorithm.
In all of these, you hand in a pointer to a function, the value of x where you want to calculate the derivative and a step-size, h, for the algorithm. You also hand in pointers to variables to store the values of the result and the absolute error.
I have barely scratched the surface of what is available in the GSL. Hopefully, you now have a better idea of some of the functions available. Although lots of scientific packages are available, sometimes there really is no option except writing your own. With the GSL, you should be able to do this with a bit less work and get to the actual computational science more quickly.
Flying is learning how to throw yourself at the ground and miss.
—Douglas Adams
Everyone has a photographic memory, some just don't have film.
—Steven Wright
Duct tape is like the force. It has a light side, a dark side, and it holds the world together.
—Unknown (possibly Oprah Winfrey)
To err is human...to really foul up requires the root password.
—Unknown
Real men don't use backups, they post their stuff on a public ftp server and let the rest of the world make copies.
—Linus Torvalds
Somewhere between the world of SMS messages and voice calling is the land of two-way push-to-talk technology. Some cell-phone providers have this feature as an option for select phones, which makes your 2012-era cell phone act like a CB radio from the 1970s. Don't get me wrong, I understand there are situations when this is beneficial, but it still makes me laugh to see people using smartphones like walkie-talkies.
If you don't have the push-to-talk (PTT) feature from your cell-phone provider, you can download the free Tikl app from the Android Marketplace. Tikl allows you to use PTT technology with any other users that have Tikl installed on their phones. Because Tikl is available for both Android and iOS, it covers a wide variety of smartphones.
I don't use Tikl very often, but in my limited testing at a softball game, it worked as advertised. My daughter was able to give me her 10–20, and I was able to give her a big 10–4 on her request to play on the swings. Although using Tikl while driving probably is safer than texting, we still don't recommend it. It'd be tough to convince the Smokey that your Android smartphone is really a CB radio.

As this issue suggests, mobile technology is more a part of our lives than ever, and we are becoming accustomed to having a tremendous amount of information available to us at all times, frequently on gadgets we keep in our pockets and bags. I am also a person who likes to keep a lot of documents, books and other reference materials on my phone, NOOK or tablet. You never know when you might need to look something up, right?
In order to make our articles even more available to you, we are introducing an annual eBook of Linux Journal content in epub and mobi formats. I am a huge fan of these formats. In addition to the many benefits of reflowing text, I also enjoy the ability to search, highlight and take notes using my e-reader software. This new compilation of all 12 issues from 2011, is organized much like our popular Archive DVD and contains all of the articles from 2011 in one easily navigable file. This should be exciting to our readers who are fans of these e-reader formats, as it includes earlier issues that previously were not available for e-readers.
Please visit www.linuxjournal.com/ebook for all the information.