Introducing Gauger, a lightweight tool for visualizing performance changes that occur as software evolves.
Regression testing is a well-established technique to detect both the introduction of new bugs and the re-introduction of old bugs. However, most regression tests focus exclusively on correctness while ignoring performance. For applications with performance requirements, developers run benchmarks to profile their code in order to determine and resolve bottlenecks. However, unlike regression tests, benchmarks typically are not executed and re-validated for every revision. As a result, performance regressions sometimes are not detected quickly enough.
Compared to correctness issues, performance regressions can be harder to spot. An individual absolute performance score rarely is meaningful; detecting a performance regression requires relating measurements to previous results on the same platform. Furthermore, small changes in external circumstances (for example, other processes running at the same time) can cause fluctuations in measurements that then should not be flagged as problematic; this makes it difficult to set hard thresholds for performance scores. Also, good measurements often take significantly longer than correctness tests. Performance improvements in one area may cause regressions in others, causing system architects sometimes to consider multiple metrics at the same time. Finally, performance can be platform-specific. This can make it necessary to perform performance evaluations on a range of systems.
The Gauger package described in this article provides developers with a simple, free software tool to track system performance over time. Gauger is lightweight, language-independent and portable. Gauger collects any number of performance values from multiple hosts and visualizes their development over time (Figure 1). In order to use Gauger, developers need to add the necessary instrumentation to their code to obtain a performance measurement and then submit it to Gauger with the gauger function call. The gauger function arguments are the description of the value, a category, the value itself and a unit of measurement. Gauger's Web interface then allows visitors to group metrics by category or by execution host and adjust the visualized revision range or the size of the plot. Gauger is ready to be used with many programming languages and revision control systems, and it is easily expandable to accommodate new ones.
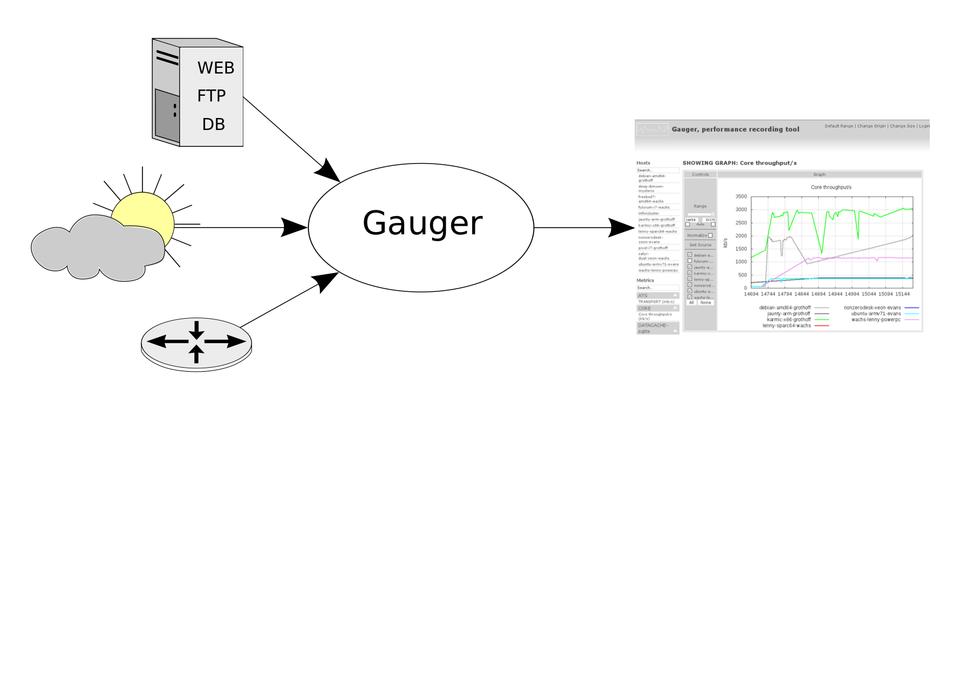
Figure 1. Gauger in action: this screenshot shows performance measurements obtained and visualized by Gauger for the GNUnet Project over the course of a few revisions.
Gauger's Web interface can be used to analyze the collected performance data in various ways. It can combine different metrics in a single plot and offers a color-coded guide to help visitors select only unit-wise compatible metrics. Gauger also allows users to normalize the data in order to mask differences in absolute performance between different execution hosts. If multiple measurements were taken for the same revision, Gauger will show the average and standard deviation as long as only a single metric is plotted. For larger projects with many metrics or execution hosts, Gauger offers a search feature to locate the desired plots. An additional instant search keeps the menus free of irrelevant items.
Finally, should further fine-tuning be needed (for example, for use in presentations), Gauger can be used to retrieve the gnuplot source of any plot. The generated gnuplot source includes the plotted data.
Gauger uses a traditional client-server architecture, where the clients report performance measurements to a central server. This architecture allows machines behind NAT or with otherwise restricted Internet access to provide performance measurements to Gauger.
All of the performance-monitoring machines to be used with Gauger should install the Gauger client, and the software to be tested should be integrated with the appropriate language bindings. Language bindings are designed to be transparent and (except for a few extra system calls) have no negative effects in case the Gauger client is not installed on the machine. Thus, it is safe to commit the language bindings to a project repository. As long as the (tiny) language bindings are included, integrating Gauger will not disrupt operations on systems where the Gauger client is not installed.
The Gauger server runs the data collection and visualization part. Data is logged through a RESTful API and saved in human-readable plain-text files. The primary job of the server is to provide a dynamic Web interface to visualize and analyze the collected data. All the communication between Gauger clients and the Gauger server is done in standard HTTP(S) requests so that only port 80 (or 443) needs to be open (Figure 2).
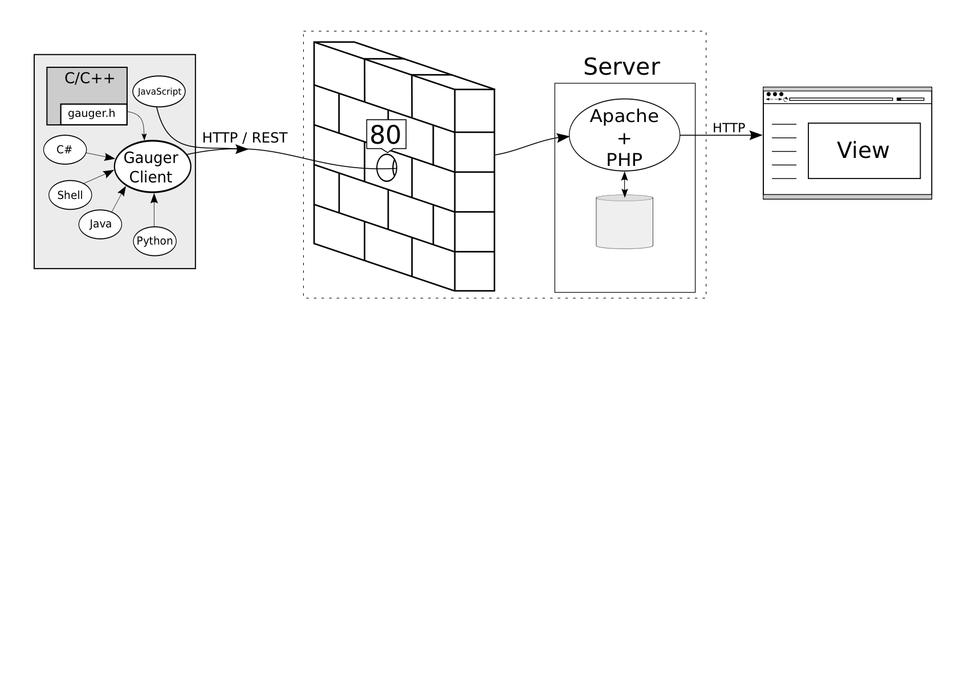
Figure 2. Gauger architecture: the Gauger server is responsible for authentication and receives performance data from the clients. The results are stored in a simple text format in a local directory. PHP is used to generate the Web site.
Each Gauger client installation requires a local Python (> or = than 2.6) interpreter. For the Gauger server, a Web server installation with PHP and gnuplot is required.
The provided install.sh script can be used to install the client, install the server code into an appropriate location and generate an updated Apache configuration. The script prompts for key configuration options, such as the installation path and the desired URL at which the Gauger server should run. Installations that do not use Apache currently require manually configuring the Web server.
Each part of Gauger uses a simple configuration file. The Gauger client configuration file contains the remote server URL, followed by the user name and password. Here's a sample configuration:
https://gnunet.org/gauger/ username password
The Gauger server configuration file contains the directory where data and authentication information are stored. Listing 1 shows a sample server configuration. When the auto-add feature is enabled, new hosts can be added by logging in to the Web site using a fresh hostname and password.
Adding a single simple call at the places where performance measurements are obtained typically is all that's required to integrate Gauger with existing projects. This call then starts the Gauger client process, which, if installed and configured correctly, submits the performance measurement to the server. On systems where the Gauger client is not installed, the call fails silently so as not to disrupt normal operations in any way. The syntax of the Gauger client command-line tool is as follows:
$ gauger [-i ID] -c CATEGORY -n NAME \ -u UNIT -d DATA
Here, NAME is the name of the metric, and DATA is any floating-point value that represents the performance measurement. UNIT is a string that describes the unit of the value, for example, ms/request. CATEGORY is a string used to group multiple performance metrics by subsystem. We recommend using the name of the subsystem or module here, especially for larger projects.
Gauger can autodetect the current revision of the project if the benchmark is executed in a directory that was checked out from a supported Version Control System (VCS). The supported VCSes are Subversion, Git, hg, bazaar, monotone and GNU arch. For distributed VCSes that do not provide an ascending revision numbering system (like Git), Gauger uses the number of commits to the repository. In this case, all execution hosts used for benchmarking should use the same origin to keep the data consistent. If the project uses an unsupported VCS or if the benchmark is executed outside the tree, Gauger needs to know which (revision) number to use for the x-axis. The --id ID option is used to supply the revision number in this case. Some projects may want to use an internal version number or a timestamp instead of a revision number generated by their VCS. The only restriction imposed on the numbers used is that Gauger's regression monitoring assumes a linear progression of development. For projects with multiple branches under active development, different Gauger servers should be set up for each branch.
Gauger ships with bindings for various languages (see, for example, Listings 2, 3, 4 and 5) to make integration easy. The resulting binaries do not depend on a Gauger client installation on the target system. The bindings should be integrated with the main project and, as mentioned before, simply do nothing when invoked if the Gauger client is not installed or not configured properly.
The JavaScript binding is unusual. Because JavaScript cannot access the local filesystem to read the configuration file, the login data must be stored in a cookie in advance. The login page on the Gauger Web site, which usually is used to set up new accounts for execution hosts, can be used to set the respective login cookie in the browser. Access to the source code's repository also is not possible from JavaScript, so the revision number must be supplied explicitly to the GAUGER call. Typically, the current revision number is obtained on the server side. For example, PHP code can be used to obtain the number from the VCS, or on-commit trigger functions provided by the VCS could be used to insert the number into the source code.
Gauger provides developers complete freedom with respect to the names, values and units of the performance metrics to be monitored. So, how do you choose a good unit? Naturally, part of the unit always is dictated by the kind of performance characteristic you are interested in—for example, execution time (seconds) or space consumption (bytes). However, generally it's a good idea always to relate this basic unit to the amount of work performed as part of the unit given to Gauger.
For example, suppose a benchmark measures the execution time for 100 GET requests. In this case, it is better to choose a name “GET request performance” with unit “requests/second” (and log the execution time divided by 100) instead of the name “Time for 100 GET requests” with unit “seconds”. The reason for this is it's quite possible the benchmark will be adjusted in the future—for example, to run 1,000 GET requests. If performance is logged as “requests/second”, such a change would then not require any changes to the name of the tracked metric. As a result, the performance regression analysis can continue to track the metric in the same curve.
Additionally, Gauger allows different results to be compared by adding new metrics to existing plots. If the new metric uses the same unit as the old one, they will use the same y-axis; otherwise, the new one will be plotted against a second y-axis on the right side of the plot. This limits the number of units per plot to two. We recommend using the same units where applicable (for example, no mixing of “seconds” and “milliseconds”) to make comparative analysis easier.
Gauger does not include for support for actually automatically running the benchmarks on various systems. However, this is not a drawback, because an excellent tool for that purpose exists in the form of Buildbot. Buildbot typically is used for regression testing and, hence, is by itself not suitable for identifying performance regressions. Nevertheless, Buildbot requires a similar network setup—that is, clients that run the tests connect to a public server. This makes it trivial to combine a Buildbot setup with Gauger. Buildbot is used to execute regression and performance tests, and Gauger visualizes the development of performance metrics over time.
Another tool for monitoring performance is Munin. Like Gauger, Munin allows users to specify which performance measurements should be created. In contrast to Gauger where execution hosts push data to the server, the Munin server periodically pulls all participating systems for a performance score. As a result, NATed systems are not easily supported. Also, because Munin stores the data indexed by time and not revision number, and given that software performance may differ widely between different platforms, not all systems may have performance scores ready at fixed time intervals. Although Munin is not a good fit for performance regression analysis for developers, it likely is a better fit for system administrators who need to monitor system performance.
Gauger offers a lightweight and language-independent approach for integrating performance regression testing with existing development processes for projects using a wide range of version control systems. With Gauger, performance regressions are detected early, providing users with software that finally is improving consistently in both correctness and performance.