Transcendent memory, called tmem, is a virtual form of RAM that can be given to user programs in copious amounts, provided those programs are okay with the fact that the tmem may vanish without warning. The Xen folks have implemented tmem for Xen, and now they want to provide a generic API for the kernel to make tmem available to any program that wants it. Dan Magenheimer and other Xen folks have been working on some patches, and it looks as though the kernel people are open to the tmem concept, so long as certain security issues are addressed. Security concerns actually drown out most other discussions, so it remains to be seen what technical problems remain before tmem could be included in the kernel tree.
Andrew Morton has taken over temporary maintainership of the MMC code. Pierre Ossman has stepped down as maintainer, and no one stepped up, so Andrew said he'd do it for now. Ian Molton, Matt Fleming, Roberto A. Foglietta and Philip Langdale all stopped just short of actually volunteering to be the new maintainer, though they all said they'd like to be CCed on all MMC patches. One benefit of the maintainership change over was that a bunch of MMC patches bubbled up that had been lying dormant for too long. Paul Mundt, Ohad Ben-Cohen and Adrian Bunk all submitted or pointed to MMC patches to be considered.
kernel.org may be getting some new mailing-list software, written by one of the kernel.org admins, Matti Aarnio. Aside from the fact that this is clearly a very fun project for him, the reasons behind it are not so clear. His code improves on majordomo security, and there are various other enhancements, but he also could have fed those features as patches to majordomo or one of the other popular list-handling tools around. One thing is clear. If kernel.org adopts a brand-new list-handling tool, a lot of other places will use it too.
PramFS, the nonvolatile RAM-based filesystem, keeps state across reboots, just like a normal filesystem. MontaVista tried to get it in the kernel back in 2004, but it was rejected because MontaVista was trying to get a patent on the algorithms. Now Marco Stornelli and Daniel Walker have said that MontaVista has abandoned its patent effort, and Marco wants to submit the code for inclusion again. But, it turns out that this is not a full-featured filesystem. There's no support for symbolic links, and there are other technical questions as well. One obvious question that was asked during the discussion was why PramFS was necessary at all. Why not just extend an existing filesystem to support nonvolatile RAM? Pavel Machek led the charge against PramFS and argued vehemently against accepting the PramFS code as is. He saw no justification for the project and said that before it even could be considered, it would have to implement modern features, such as journaling and other features that come standard with many newer filesystems today.
Microsoft has GPLed its Hyper-V drivers, and it will allow the in-kernel versions of that code to be the canonical versions. Future Microsoft contributions will be made as patches to those kernel drivers, rather than as full releases of their own. Greg Kroah-Hartman announced the occasion, praising Microsoft's Hank Janssen, Haiyang Zhang and Sam Ramji, as well as numerous non-Microsoft people, for helping get this done. Some of the Microsoft people, including Hank, said they intend to continue their work on these drivers as community contributors.
The past few months in this space, I've covered specific utilities and how they can be used, sometimes in quite interesting ways. This month, I instead look at a task and see what utilities are available to accomplish it. People who do scientific computational work tend to use several pieces of software in series. This software could span the entire computer age in terms of how old it might be. The usual work flow involves taking some initial data and feeding it as input to a program, in order to do the first computational step. The output then is fed as input to another program, in order to complete the second computational step. This process continues until the final results are reached. The problem with this method is that the programs used at each computational step probably were written by completely different groups, possibly decades apart. This means the researcher may need to do some kind of transformation to get the output from one computational step into the proper format to be used as input for the next computational step.
One simple yet common problem is the use of different field separators in a data file. In some cases, fields may be separated by commas. In other cases, they may be separated by tab characters. If you have to change from one to the other, you can use the tr utility:
tr "," "\t" <data_file_1 >data_file_2
The above replaces every comma in data_file_1 with a tab and writes the results into data_file_2. This works well for replacing single characters or even classes of characters. Say you had a really old piece of FORTRAN code that expected all letters to be uppercase. You could accomplish that with the following:
tr "[:lower:]" "[:upper:]" <data_file_1 >data_file_2
But, what if you have some more-complicated translation to make? A more general-purpose utility to use for this is sed, the Stream EDitor. With sed, you can make substitutions with the s command. For example, you can achieve the same result as above, converting commas to tabs, by running:
sed -e "s/,/ /g" data_file_1 >data_file_2
(The blank space after the second forward slash is a tab character.) Remember: to type a tab character in the bash shell, you need to type C-v TAB. Using this command, you can translate any kind of separator into any other kind of separator. And don't think it can't happen to you. I personally have seen separators like |*| or %*% in the wild. You never know what some previous person is going to think is a good idea.
So, now you have your data fields separated with the correct separator, but what if you need only some of this data? The output file you are massaging may have more data than you need for the next computational step. What can you do? The cut and paste utilities can be used for this purpose. You can cut selected columns out of the data file with:
cut -f1,3 data_file_1 >data_file_2
This cuts columns 1 and 3 and dumps them into data_file_2. It assumes that the field separator is a tab character. If you've used a different separator character, you can use the -d option. For example, the following cuts the file up using comma separators:
cut -f1,3 -d "," data_file_1 >data_file_2
If you have the opposite problem, you can use the paste utility to glue together data from multiple files. Say you have two data files containing the parts required for the next computational step. You can glue them together with:
paste data_file_1 data_file_2 >data_file_3
This assumes that you want to use a tab character as the field separator. If you want to use another character, such as a comma, you can use the -d option, like this:
paste -d "," data_file_1 data_file_2 >data_file_3
Another very useful utility can be used to do this type of job, awk. With awk, you can pull out only the data you need. For example, say your output file has three columns of data, but the next computational step requires only columns 1 and 3. With awk, this becomes a very simple task by executing the following:
awk '{print $1,$3}' data_file_1 >data_file_2
This example assumes that the initial field separator in the data_file_1 is a tab character. You get columns 1 and 3, with a comma as the field separator, dumped into the data_file_2. If you want to keep the tab character, use the following instead:
awk '{print $1"\t"$2}' data_file_1 >data_file_2
If your initial data file, data_file_1, uses a comma as a field separator, you can tell awk this with the -F option:
awk -F "," '{print $1,$2}' data_file_1 >data_file_2
With these options, you can do the field separator translation and the cut function both in one step.
With awk, you can do even more impressive data massaging. Say you need to use the average of the three columns as input to the next computational step. Do the following:
awk '{print ($1+$2+$3)/3}' data_file_1 >data_file_2
awk makes an entire programming language available, and it can be used for very complex data massaging. Hopefully, this short introduction shows some of the possibilities available for your data management tasks and helps smooth the work flow between computational steps.
Haiku is a free and open-source operating system designed to be compatible with BeOS. BeOS was the operating system that ran on computers built and sold by Be, Inc., in the 1990s and also on Apple's PowerPC reference platform. BeOS was designed for working with digital media and took advantage of modern hardware. It worked on multiprocessor systems and extensively used multitasking and multithreading. BeOS was not built to look like another *nix system and neither is Haiku. It is not based on Linux nor does it use the X Window System or GNOME or KDE.
Haiku is written in C++, as was BeOS before it, and the operating system API is object-oriented. As of 2008, Haiku can be compiled from within Haiku itself. As of 2009, there is a native GCC4 port that now allows numerous applications to be ported to Haiku. A Java port for Haiku also is in progress.
Haiku began in 2001 and was named OpenBeOS until 2004, when the name was changed to avoid problems with the original trademarks (and also because the original name required too many Shift-key presses). Haiku is released under the MIT license. Haiku currently is bootable and usable, but it has not reached version 1.0 yet (R1 in Haiku speak).
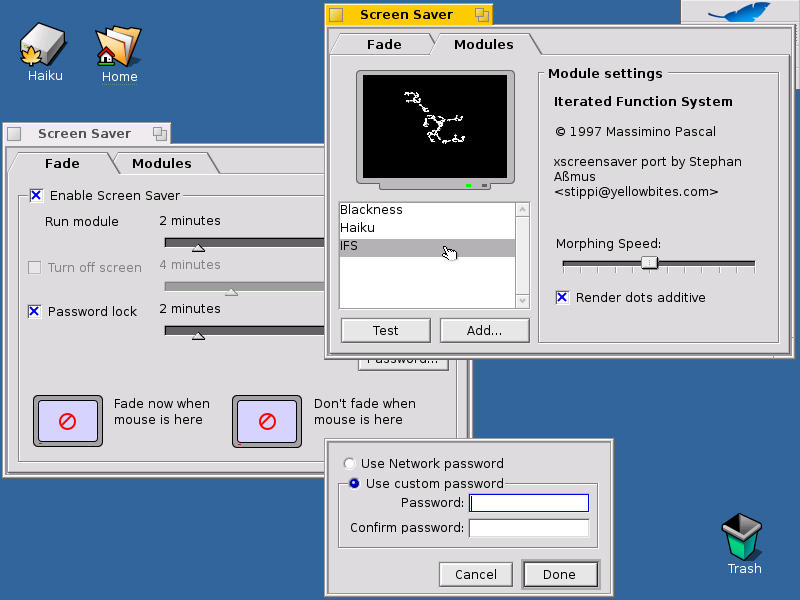
The Haiku Screen Saver Preferences Applet (from www.haiku-os.org)
1. Number of open-source C files available on the Internet (duplicates removed): 11,500,000
2. Number of open-source Java files: 10,600,000
3. Number of open-source C++ files: 8,640,000
4. Number of open-source PHP files: 3,960,000
5. Number of open-source Perl files: 1,820,000
6. Number of open-source Python files: 1,570,000
7. Number of open-source Ruby files: 952,000
8. Number of open-source FORTRAN files: 374,000
9. Number of open-source COBOL files: 9,000
10. Number of open-source “Hello World” programs: 198,000
11. Number of open-source versions of stdio.h: 4,000
12. Number of open-source files containing “TODO:” comments: 1,640,000
13. Number of open-source files containing “FIXME:” comments: 1,230,000
14. Number of open-source files containing the word “hack”: 901,000
15. Number of open-source files containing the “F word”: 88,800
16. Number of Linux distros listed on linux.org: 220
17. Number of Linux distros listed on distrowatch.com: 309
18. Result count difference between Yahoo and Google searching for “Linux”: 1,023,000,000
19. US National Debt as of 08/03/09, 11:18:07am MST: $11,595,953,181,678.30
20. Change in the debt since last month's column: $94,411,207,892.70
1–15: Google Code Search (www.google.com/codesearch)
17: distrowatch.com
18. Yahoo and Google (Yahoo returns the higher count)
19. www.brillig.com/debt_clock
20. Math
I have a love/hate relationship with Netbooks. On the upside, they are inexpensive, portable and beefy enough to run most applications. On the downside, they have small screens and small keyboards. Although I'm not normally a fan of nonstandard desktops, a few Netbook-specific Linux distributions make a valid case for their existence—especially on small screens.
Ubuntu Netbook Remix
Although not the first, UNR is one of the most “open” of the Netbook-specific interfaces. Underneath it is running (of course) Ubuntu, but the interface is designed for tiny screens (Figure 1). Its large icons and lack of tiny menus make it easy to navigate, even from low resolutions. Some of the applications still are awkward at small screen sizes, but UNR does a nice job of making the most of screen real estate. Check it out at www.ubuntu.com/GetUbuntu/download-netbook.
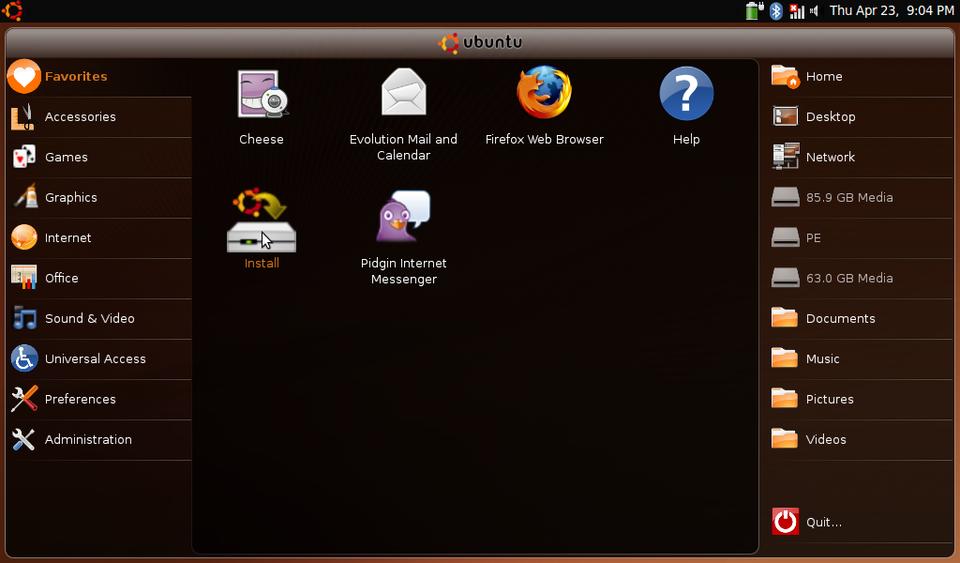
Figure 1. Ubuntu Netbook Remix runs Ubuntu underneath this Netbook-friendly interface.
Moblin
Although still in beta, Moblin is a Linux distribution built from the ground up designed for mobile devices (Figure 2). More than merely a wrapper around an underlying operating system, Moblin offers an entirely unique user experience. I personally had a difficult time figuring out how to use Moblin, but it's early in development and available to try out. To download a current live image, visit moblin.org/downloads.
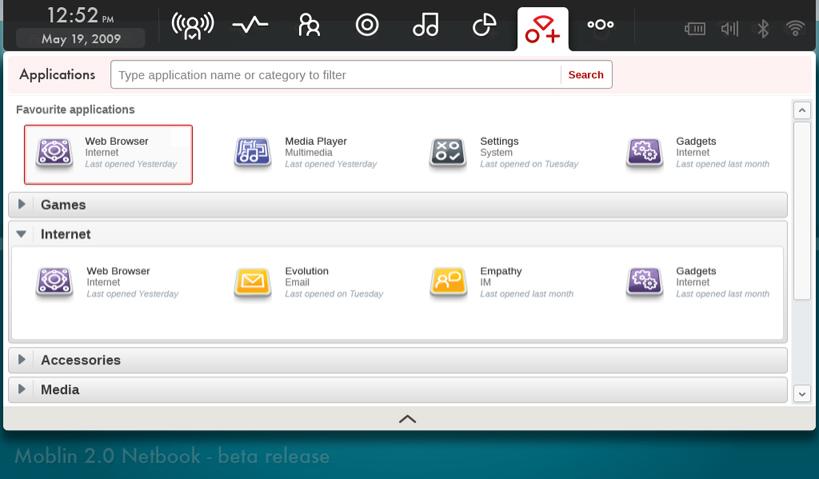
Figure 2. Moblin is designed to work on a variety of handheld devices, but Netbooks are one of the current foci.
Jolicloud
Jolicloud is not only early in development, but is actually in a closed beta program. I heard about the operating system on Twitter, and when I checked it out, it was rather impressive (Figure 3). Although the interface does appear to be very user-friendly, and it's designed for a cramped screen size, the real difference with Jolicloud is its goal to move all your information to the “cloud”. Operating systems like gOS have attempted to do the same, without much success. Hopefully, Jolicloud's sync/cache method to switch between Netbooks and desktops will be able to move us effectively to Web-based applications without sacrificing the need for off-line usability. You can sign up for the closed testing phase at my.jolicloud.com/account/invitation.
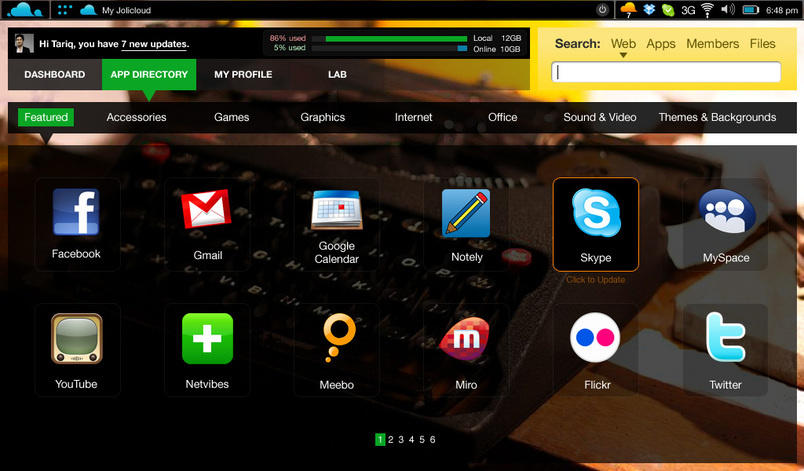
Figure 3. Jolicloud looks impressive. Only time will tell whether it will provide a dependable Web-immersed environment.
Chrome OS: the Future, or Too Little Too Late?
A while back, Google announced its upcoming operating system Chrome. It remains to be seen whether the Chrome OS will be a dominant force in the Netbook market or whether it will face the same limited fanfare that the Chrome browser receives. It also begs the question of whether Google waited too long for such an endeavor. With options like UNR, Moblin and soon Jolicloud, Netbooks finally might become more than a novelty. I just hope hardware manufacturers can make some decent keyboards for them!
This might make me sound like an old fogey, but I really do miss the old games like Space Quest, The Curse of Monkey Island and Return to Zork. The problem isn't that I don't have the games anymore, but rather that they were designed for my 386 computer running DOS. Thankfully, I'm not alone in my fits of nostalgia. The developers over at www.scummvm.org have reproduced the “Script Creation Utility for Maniac Mansion” developed by Lucas Arts and packaged it into a virtual machine (thus, ScummVM). That virtual machine is open source and available for just about any platform you can imagine.

Figure 1. If you wonder what the mustached car could possibly be saying, you'll have to play Putt Putt Joins the Parade. Thankfully, it's installable on ScummVM.
It's important to note that ScummVM doesn't come with any actual games. You either need to purchase the old games it supports from eBay or look in your closet for those stacks of old game disks you used to play as a kid (or as an adult, for some of us). What ScummVM does provide is a platform for playing those old games and even introducing your kids to games they'll probably never have a chance to play otherwise. At OSCON in July 2009, ScummVM was announced as SourceForge's Community Award winner in the category of “Best Project for Gamers”. If you've never checked it out, now is a good time.
As for me? I think it's about time I introduced Putt Putt & Fatty Bear to my kids. Hopefully, they enjoy the games as much as my brother-in-law did when he was growing up. Monkey Island? Yeah, I think I'll play that one myself.
I admit, I'm one of those people who dual-boots so I can play video games. I've tried running programs like CrossOver Games in order to feed my need for fragging, but in the end, it seems I always have to install Windows to enjoy some real gaming fun. Thankfully, I'm not the guy in charge of things worldwide, because the folks over at www.supergamer.org have created a bootable, dual-layer DVD full of native-running Linux games. Yes, I said native. Check out the impressive list of preinstalled games you'll get when you download the ISO:
Quake Wars
Doom 3
Prey
Unreal Tournament
Quake 4
Savage 2
Postal 2
Enemy Territory
Penumbra Black Plague
Sauerbraten
Urban Terror
Soldier of Fortune
Torcs
Tremulous
AlienArena
True Combat
America's Army
Nexus
OpenArena
PlaneShift
Drop Team
Frets On Fire
Chromium B.S.U.
Mad Bomber
X-Moto
BZ Flag
Mega Mario
Glaxium
GL-117
NeverBall
NeverPutt
Super Tux
PPRacer
So much for gaming being a Windows-only adventure! Based on Vector Linux, SuperGamer is ready to perform on all modern video cards without additional downloads. Just pop it in, boot it up, and frag.
This is SuperGamer's official screenshot. Notice all the game icons on the bottom of the screen.
Don't worry about what anybody else is going to do. The best way to predict the future is to invent it.
—Alan Kay
Premature optimization is the root of all evil (or at least most of it) in programming.
—Donald Knuth
We're even wrong about which mistakes we're making.
—Carl Winfeld
filter(P, S) is almost always written clearer as [x for x in S if P(x)].
—Guido van Rossum on Python
Lisp has jokingly been called “the most intelligent way to misuse a computer”. I think that description is a great compliment because it transmits the full flavor of liberation: it has assisted a number of our most gifted fellow humans in thinking previously impossible thoughts.
—Edsger Dijkstra, CACM, 15:10
A government big enough to give you everything you want, is big enough to take away everything you have.
—Thomas Jefferson
This month's Linux Journal is all about infrastructure. Want a broader view? Visit us at LinuxJournal.com for more of our editors' insights on infrastructure as it applies to Linux, open source and Web technology.
These articles should get you started:
“Comparing Hard and Soft Infrastructure”: www.linuxjournal.com/content/comparing-hard-and-soft-infrastructure
“Understanding Infrastructure”: www.linuxjournal.com/content/understanding-infrastructure
“Building a Multisourced Infrastructure Using OpenVPN”: www.linuxjournal.com/article/9915
“Why Internet & Infrastructure Need to Be Fields of Study”: www.linuxjournal.com/content/why-internet-infrastructure-need-be-fields-study