Featuring a rich standard library, an extensive collection of turn-key widgets, a unit-testing framework and build tools for minifying your source files, it's no wonder that Dojo is a key part of products from industry giants, such as AOL, Sun Microsystems, BEA and others.
A number of JavaScript toolkits have emerged to automate common Web development tasks and simplify creating rich user interfaces. Of all the contenders, Dojo stands out as the industrial-strength JavaScript toolkit because of its incredible depth and breadth. It features an extensive JavaScript library, a system of rich turn-key widgets, a collection of specialized subprojects, build tools and a unit-testing harness. Regardless of what your project entails, it is almost a certainty that Dojo can simplify the development and maintenance required. This article systematically focuses almost exclusively on some of the most fundamental constructs in the toolkit's highly optimized kernel, commonly referred to as Base.
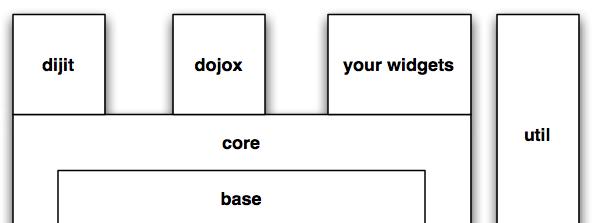
Figure 1. Toolkit Architecture
Variations among Web browsers have made developing applications for the Web really messy work. Working around subtle variations in JavaScript implementations, wrangling the Document Object Model (DOM) and normalizing content rendering across browsers can be downright tormenting at times, and unfortunately, a nontrivial portion of the investment in developing a solid Web application is spent re-inventing this kind of brittle boilerplate. Although many technologies have evolved to mitigate these kinds of issues, one you especially should be aware of the next time you decide to build a Web application is Dojo, the industrial-strength JavaScript toolkit.
In short, the Dojo toolkit is a liberally licensed client-side technology that can supplement virtually any aspect of Web development. It features a tiny but fully featured JavaScript standard library that insulates you from the bare metal of the browser, a large subsystem of widgets that snap into a page with little to no JavaScript required, and a suite of build tools for minifying and consolidating resources as well as writing unit tests. Knowing that industry giants, such as AOL, IBM, BEA and Sun Microsystems, are on board with Dojo should give you a boost of confidence if you're leery of trying something else in an ecosystem that's littered with half-baked inventions that don't always come though on their promises to deliver all-encompassing solutions.
This remainder of this article works through the bulk of the toolkit's most fundamental JavaScript programming constructs that will benefit you regardless of the size or scope of your project.
Although you could download Dojo from its official Web presence and set up a local installation, the easiest way to get started with Dojo is to use the latest version of Dojo that is hosted on AOL's Content Delivery Network (CDN). The following page skeleton demonstrates that the minimal effort required to put Dojo to work from the CDN is a SCRIPT tag that loads Dojo into the HEAD of the page; it is especially noteworthy that the SCRIPT tag incurs the cost of one request to the Web server that delivers a gzipped payload of approximately 29kB and provides the latest 1.1.x release that is available. In Dojo parlance, the good that the SCRIPT tag provides is called Base, because it provides the base for the toolkit, and because everything you'll use is contained in the base-level dojo.* namespace. Speaking of which, with the exception of the dojo identifier itself, the global page-level namespace is otherwise preserved:
<html>
<head>
<title>Putting Dojo To Work</title>
<!-- Loading Dojo requires only one SCRIPT tag -->
<script type="text/javascript"
src="http://o.aolcdn.com/dojo/1.1/dojo/dojo.xd.js">
</script>
<script type="text/javascript">
dojo.addOnLoad(function() {
/* safely use any code that relies on dojo.*
functions in here ... */
});
</script>
</head>
<body>
<a href="http://dojotoolkit.org">Dojo</a>
</body>
</html>
To summarize, the dojo.addOnLoad block fires once the asynchronous loading of the dojo.xd.js file and any dependencies specified via dojo.require statements (more on these in a bit) have completed, and this is necessary in order to prevent any race conditions that might occur without it. Basically, the dojo.xd.js file providing Base accomplishes feats such as normalizing DOM events and provides you with a number of useful utilities for accelerating application development.
As a natural starting point for our discussion, consider the following snippet from a Web page:
<form name="foo" action="/bar"> <label>A form with name="foo"</label> </form> <div id="foo"> A div with id=foo </div>
The excerpt is trivial, and it should be obvious that running a function as simple as document.getElementById("foo") would always return the DIV element as a result. As a Linux user, you even could use a Gecko-based browser, such as Firefox, or a KHTML-based browser, such as Konqueror, to test the page and verify it for yourself. However, you may be alarmed and shocked to learn that running the very same test in Internet Explorer versions 6 or 7 returns the FORM element instead of the DIV element! This particular bug arises, because the name and id attribute namespaces are merged for IE. As it turns out, the DIV would have been returned if the FORM had not appeared first in the document, so this bug is especially tricky. At any rate, Dojo provides the dojo.byId function that works just like document.getElementById—except that it accounts for this particular issue. Use it to stay safe and to save some typing.
Although the Array data type is one of the most commonly used, not all arrays are created equal—at least not among the various JavaScript implementations. Fortunately, Dojo's Array facilities provide an easy-to-use abstraction, ensuring that the code you write will work anywhere, and you won't be left scratching your head staring at a big semantic bug that's painful to track down. Consider the following (seemingly innocent) block of code:
var a = getMetasyntacticVariables();
if (a.indexOf("foo") != -1) {
/* do something... */
}
Although you might swear that there couldn't possibly be anything wrong with that code, that's because you're probably (again) using and testing with a nice KHTML- or Gecko-based browser. The Trident-based Internet Explorer has its own notions of what an Array should and shouldn't do, and the indexOf method isn't one of them. In other words, you can expect for your code most likely to outright fail if you try to invoke the indexOf function on an Array when the code runs in IE. In this particular case, you could use the dojo.indexOf function to produce code safely that is portable across browsers:
var a = getMetasyntacticVariables();
if (dojo.indexOf(a, "foo") != -1) {
/* do something... */
}
Other useful Array methods available via the dojo.* namespace include map, filter, every, some, lastIndexOf and forEach. They all work as described in the Mozilla Developer documentation.
At first glance, the forEach method may seem a bit redundant, because JavaScript provides a for loop construct, but forEach provides one particularly important feature that often escapes even many senior-level JavaScript programmers: block level scope. To illustrate, first consider the following two approaches to iterating over an Array:
// Approach 1:
var arr = getSomeArray();
for (var i in arr) {
/* manipulate arr[i] */
}
/* The last value of i is available here because the
for loop does not have its own block level scope.
Ditto for any temporary variables
defined between the braces. */
// Approach 2:
var arr = getSomeArray();
dojo.forEach(arr, function(item) {
/* manipulate item */
});
/* Neither item nor any temporary variables are
available here because the scope of the anonymous
function protected this outer scope from it. */
Another function you'll use quite often for DOM manipulation is dojo.style, which acts as a setter when you pass it a node and a map of style properties as parameters and a getter when you pass it a node and a particular style property. In addition to providing an intuitive one-stop shop for style, it protects you from a number of DOM-based browser-specific quirks that otherwise would creep up on you. Here's how it works:
// Set some style properties..
var fooNode = dojo.byId("foo");
dojo.style(fooNode, {
color : "red",
background : "white",
border : "blue"
});
/* ... Lots of interesting things
happen in the meanwhile ... */
// Get a style property such as width...
var props = dojo.style(fooNode, "width");
On a related tangent, you can use any combination of the dojo.hasClass, dojo.addClass and dojo.removeClass functions to inspect and manipulate classes in the same intuitive manner:
var fooNode = dojo.byld("foo");
if dojo.hasClass(fooNode) {
// do something...
dojo.addClass(fooNode, "bar");
} else {
//do something else...
dojo.removeClass(fooNode, "baz");
}
The dojo.query function provides a natural segue into general-purpose DOM manipulation and is based on CSS3 selectors. For example, you might use the following logic to query the DOM for any anchor tags and temporarily highlight the background to be yellow for a mouse-over event:
dojo.query("a")
.onmouseover(function(evt) {
dojo.style(evt.target, {background : "yellow"});
})
.onmouseout(function(evt) {
dojo.style(evt.target, {background : ""});
});
The statement inside the dojo.addOnLoad block queries the DOM for any anchor tags using the “a” CSS3 selector and returns a collection of nodes as a specialized subclass of Array called dojo.NodeList. Each of the dojo.NodeList methods is then successively applied to the collection of nodes with the final result being returned so that it can be captured into a variable if desired. The dojo.NodeList class provides a number of useful methods, such as addClass, removeClass, style and the various Array functions that you already have seen. For example, if you are seduced by the elegant dot notation that dojo.NodeList provides, you may find yourself with an expression like the following:
// find anchors that are direct descendants of divs
var highlyManipulatedNodes = dojo.query("div > a")
.addClass("foo")
.removeClass("bar")
.onmouseover(function(evt) { /* ... you ... */})
.map(function(item) { /* ... get ... */})
.filter(function(item) { /* ... the ... */})
.forEach(function(item) { /* ... idea ... */});
It is especially noteworthy that the dojo.NodeList methods named after and triggered by DOM events, such as onmouseover or onblur, accept a single parameter that is a W3C standardized event object, so you are freed from the development and maintenance of yet another layer of subtle incompatibilities when developing a Web application. In fact, the next section investigates the very mechanism that makes this possible.
It's quite often the case that you'll need to chain together some events arbitrarily to produce an action/reaction effect. The dojo.connect function provides a seamless interface for arbitrarily connecting events and JavaScript Objects. For example, you already know that you could hook up a handler when a user mouses over a specific node by using dojo.query and assigning a function via dojo.NodeList's onmouseover method like so:
dojo.query("#foo") //find the node with id=foo
.onmouseover(function(evt) { /* ... */ });
An alternative implementation via dojo.connect is the following statement, which assembles the connection and returns a handle that can be disconnected later manually if the situation calls for the relationship to be torn down. For example, it's generally a good idea to tear down the handle explicitly before destroying nodes that are involved in the connection:
var h = dojo.connect(dojo.byId("foo"), "onmouseover", function(evt) {
/* ... use the normalized event object, evt, here ... */
});
/* Later */
dojo.disconnect(h); //tidy up things...
Although the net effect is the same for the two implementations presented, dojo.connect seamlessly allows you to provide Objects as the context. For example, the following variation illustrates how to fire off an event handler whenever a particular function is invoked:
var obj = { // a big hash of functions...
foo : function() { /* ... */ },
bar : function() { /* ... */ }
}
// set the handler to fire whenever obj.foo() is run
dojo.connect(obj, "foo", function() {
/* ... a custom event handler ... */
});
obj.foo(); // the custom handler fires automatically
If you want to use a particular scope with the custom handler, you can wedge it in as a third parameter. The parameters are all normalized internally. Here's how it would work:
var obj1 = { // a big hash of functions...
foo : function() { /* ... */ },
bar : function() { /* ... */ }
}
var obj2 = { // a big hash of functions...
baz : function() { /* ... */ }
}
// fire the handler whenever obj.foo() is run
dojo.connect(obj1, "foo", obj2, "baz");
obj.foo(); // fire obj2.baz right after obj1.foo
Although dojo.connect provides a kind of direct action/reaction style of communication, the publish/subscribe metaphor has many highly applicable use cases in loosely coupled architectures in which it's not prudent for objects or widgets to know about one another's existence. This metaphor is simple enough to set up. The dojo.publish function accepts a topic name and an optional Array of parameters that should be passed to any subscribers. Becoming a subscriber to a topic is done through the dojo.subscribe function, which accepts a topic name and a function that is executed in response to the published topic. Here's a working example with a couple Function Objects:
function Foo(topic) {
this.greet = function() {
console.log("Hi, I'm Foo");
/* Foo directly publishes information,
but not to anywhere specific... */
dojo.publish("/lj/salutation");
}
}
function Bar(topic) {
this.greet = function() { console.log("Hi, I'm Bar"); }
/ * Bar directly subscribes to information,
but not from anywhere specific */
dojo.subscribe("/lj/salutation", this, "greet");
}
var foo = new Foo();
var bar = new Bar();
foo.talk(); //Hi, I'm Foo...Hi, I'm Bar
A couple variations on the pub/sub metaphor are available, but the vanilla dojo.publish/dojo.subscribe functions relay the general idea. Any situation in which you cannot (for whatever reason) expose an API might be a prime opportunity to take advantage of pub/sub communication in your application.
JavaScript is an object-oriented programming language, but unlike the class-based languages of Java or C++, it uses prototypal inheritance as its mechanism of choice instead of a class-based paradigm. Consequently, mixing properties into object instances as part of a “has-a” relationship is often a far more natural pattern than attempting to mimic class-based patterns that espouse an “is-a” relationship. Consider the following example that adds in a collection of properties to an object instance all at once using dojo.mixin:
var obj = {prop1 : "foo"}
/* obj gets passed around and lots of
interesting things happen to it */
// now, we need to add in a batch of properties...
dojo.mixin(obj, {
prop2 : "bar",
prop3 : "baz",
prop4 : someOtherObject
});
The dojo.extend function works much like dojo.mixin except that it manipulates a constructor function's prototype instead of the specific object instances.
Of course, there are some design patterns that do lend themselves to inheritance hierarchies, and the dojo.declare function is your ticket to mimicking class-based inheritance if you find yourself in a predicament that calls for it. You pass it the fully qualified name of the “class” you'd like to create, any ancestors that it should inherit from, and a hash of any additional properties. The dojo.declare function provides a built-in construction function that gets run, so any parameters that are passed in can be handled as needed. Here's a short example demonstrating a Baz class that multiply inherits from both a Foo and a Bar class:
//create an lj.Foo that doesn't have any ancestors
dojo.declare("lj.Foo", null,
{
/* custom properties go here */
_name : null,
constructor : function(name) {
this._name = name;
},
talk : function() {alert("I'm "+this._name);},
customFooMethod : function() { /* ... */ }
});
//create an lj.Bar that doesn't have any ancestors
dojo.declare("lj.Bar", null,
{
/* custom properties go here */
_name : null,
constructor : function(name) {
this._name = name;
},
talk : function() {alert("I'm "+this._name);},
customBarMethod : function() { /* ... */ }
});
//create an lj.Baz that multiply inherits
dojo.declare("lj.Baz", [lj.Foo, lj.Bar],
{
/* custom properties go here */
_name : null,
constructor : function(name) {
this._name = name;
},
talk : function() {alert("I'm "+this._name);},
customBazMethod : function() { /* ... */ }
});
//parameters get passed into the special constructor function
bartyBaz = new lj.Baz("barty");
When each of the dojo.declare statements is encountered, internal processing leaves a function in memory that can be readily used to instantiate a specific object instance with the new operator—just like plain-old JavaScript works. In fact, the bartyBaz object is one such instantiation. It inherits the customFooMethod and customBarMethod from ancestors, but provides its own talk method. In the event that it had not provided its own talk method, the last one that was mixed in from the ancestors would have prevailed. In this particular case, the ancestors were [lj.Foo, lj.Bar], so the last mixed in ancestor would have been lj.Bar. If defined, all classes created with dojo.declare have their parameters passed a special constructor function that can be used for initialization or preprocessing.
No discussion of a JavaScript toolkit would be complete without a mention of the AJAX and server-side communication facilities that are available. Dojo's support for server-side communication via the XMLHttpRequest (XHR) object is quite rich, and the dojo.xhrGet function is the most logical starting point, because it is the most commonly used variant. As you might have suspected, it performs a GET request to the server. Unless you configure it otherwise, the request is asynchronous and the return type is interpreted as text. Here's an example of typical usage:
dojo.xhrGet({
url : "/foo", //returns {"foo" : "bar"}
handleAs : "json", // interpret the response as JSON vs text
load : function(response, ioArgs) {
/* success! treat response.foo just like a
normal JavaScript object */
return response;
},
error : function(response, ioArgs) {
/* be prepared to handle any errors that occur here */
return response;
}
});
A point wasn't made of it, but the reason that both the load and error function returns the response type is because Dojo's I/O subsystem uses an abstraction called a Deferred to streamline network operations. The Deferred implementation was adapted from MochiKit's implementation (which was, in turn, inspired from Python's Twisted networking engine). The overarching concept behind a Deferred is that it provides a uniform interface that drastically simplifies I/O by allowing you to handle asynchronous and synchronous requests the very same way. In other words, you can chain callbacks and errbacks arbitrarily onto a Deferred, regardless of whether the network I/O is in flight, threw an Error or completed successfully. Regardless, the callback or errback is handled the same way. In some situations, Deferreds almost create the illusion that you have something like a thread at your disposal.
Here's an updated example of the previous dojo.xhrGet function call that showcases the dojo.Deferred object that is returned:
var d = dojo.xhrGet({
url : "/foo", //returns {"foo" : "bar"}
handleAs : "json", // interpret the response as JSON instead
load : function(response, ioArgs) {
/* success! treat response.foo just
like a normal JavaScript object */
return response; // pass into next callback
},
error : function(response, ioArgs) {
/* be prepared to handle any errors that occur here */
return response; //pass into next errback
}
});
/* The xhrGet function just fired. We have no idea if/when
it will complete in this case since it's asynchronous.
The value of d, the Deferred, right now is null since it
was an asynchronous request */
//gets called once load completes
d.addCallback(function(response) {
/* Just chained on a callback that
fires after the load handler with the
same response that load returned. */
return response;
});
d.addCallback(function(response) {
/* Just chained on another callback that
fires after the one we just added */
return response;
});
d.addErrback(function(response) {
/* Just added an errback that
fires after the default error handler */
return response;
});
/* You get the idea... */
Again, the beauty of a Deferred is that you treat it as somewhat of a black box. It doesn't matter if, when or how it finishes executing. It's all the same to you as the application programmer.
Just so you're aware, sending data to the server with another HTTP method, such as POST or PUT, entails using the very same kind of pattern and works just as predictably with the dojo.xhrPost function. You even can provide a form node so that an entire form is POSTed to the server in one fell swoop or pass in raw data for those times when you need to transfer some information to the server as part of a RESTful (Representational State Transfer-based) architecture. The dojo.toJson function may be especially helpful in serializing JavaScript objects into a properly escaped JSON string, if the protocol is something along the lines of a JSON-RPC system in which the envelope is expected to be JSON in both directions.
Simple animations are generally a crowd-pleaser, and Base includes a few easy-to-use functions that make animating content a snap. For starters, consider the dojo.fadeIn and dojo.fadeOut functions:
dojo.fadeOut({node : "foo"}).play();
// then sometime later...
dojo.fadeIn({node : "foo"}).play();
Hopefully, that seemed as simple as it should be: point to a node and fade it. It won't be long though before you'll find the desire to do some animations that involve arbitrary CSS properties, and that's when the dojo.animateProperty function comes into play. The basic pattern is that you pass it a node, a map of properties and a duration, and it handles the rest. Here's a simple example that relates the pattern via the dojo.anim function by providing functions for imploding and exploding a node:
//implode a node...
dojo.anim("foo", properties : {width : 0, height : 0}, 500);
//implode over 500ms
/* ... Later ... */
//then explode it back out
dojo.anim("foo", properties : {width : 300, height : 300}, 500);
//explode back out over 500ms...
A number of other useful animation functions exist in the dojo.fx module.
Although there is a ton of functionality jam-packed into Base, there are a number of other highly useful modules that you can get from Core at the expense of a dojo.require statement, which acts like #include from C++ or an import statement from Python or Java. Before providing an overview of what's available in Core, however, it's worth briefly summarizing how the dojo.require statement works, because it is a staple in the toolkit.
In Dojo parlance, a dojo.require statement generally fetches an entire module or a resource that is part of a module, and a module is just a JavaScript file arranged according to a particular convention. For example, if you were to download a source distribution of Dojo and browse the contents of the dojo/io folder, you'd see that an iframe.js file and a script.js file are present. The first statement in each of these files is dojo.provide("dojo.io.iframe") and dojo.provide("dojo.io.script"), respectively. In this case, you'd say that the dojo.io module provides the iframe and script resources. The basic trade-off when designing modules is the balance between minimizing HTTP requests that incur a lot of latency and not downloading more content than you actually need. (The build tools included in Util, however, can consolidate multiple resource files into a single minified JavaScript file that nearly obliterates any concern surrounding this particular issue for many cases.)
Let's put dojo.require to work by having it retrieve the dojo.io.script resource that we'll use to fetch some public data using Flickr's JSON with padding (JSONP) API. Like almost everything else in the toolkit, the dojo.io.script.get function that we'll use abstracts most of the dirty work away, so you don't have to write or maintain any of that brittle boilerplate:
//Require what you need...
dojo.require("dojo.io.script");
//...but don't reference it outside of the dojo.addOnLoad
//block or you'll create a race condition since dojo.require
//statements are satisfied asynchronously over the CDN...
dojo.addOnLoad(function() {
dojo.io.script.get({
callbackParamName : "jsoncallback", //provided by Flickr
url: "http://www.flickr.com/services/feeds/photos_public.gne",
load : function(response, ioArgs) {
/* response is a JSON object with data about public photos */
return response;
},
error : function(response, ioArgs) {
/* ... handle the error ... */
return response;
}
});
}
Although there's not time to gloss over Core systematically the same way we did with Base, it's well worth the time to explore it, and you're now equipped with enough fundamental knowledge to go do some digging on your own. A few of the resources you'll find in Core include:
Internationalization facilities and functions for computing dates, times and formatting currency.
Additional animation capabilities.
The IFRAME transport (useful for uploading files to the server).
Functions for handling cookies.
Powerful data APIs that abstract cumbersome server-side I/O.
Drag-and-drop machinery.
And even though Base and Core are two substantial components of the toolkit, there's also Dijit, DojoX and Util, which easily could span entire articles and books of their own. In short, Dijit is a huge infrastructure of DHTML-based turn-key widgets. DojoX is a collection of specialized subprojects ranging from wrappers around Google Gears to graphics functions that can use scalable vector graphics (SVG) to draw in the browser natively. Util provides DOH, a unit-testing framework and a collection of build tools for squeezing as much performance as possible out of your JavaScript. Although not covered in this article, these topics are well worth investigating and are just as important to your development efforts as Base and Core.