Who says “View Source” on a Web page has to be a read-only proposition? Re-mix your favorite Web sites by changing styles, adding and removing elements, and more.
Here's a strange thing: hacking open source isn't done only at midnight, in the spare room, hunched over the protocol analyser, the breadboard, source code control and some helpless device. No, sometimes it's done inside a different crucible entirely: a public world of shameless posturing and self-promotion. A lurid and neon habitation of signs, shops, styles and stuff populated by the babble of conversations both informed and banal. It's a place of great joy and great angst; a place of towering conservatism and the last bastion of the radical voice. Within it, a good hairdo or a radically cut legline can get you as far as a symbolic debugger, possibly even further. Devices they may be, but of a different cut entirely from those of hardware. Its denizens slip hyperactively in and out of view like character actors with coffee addictions and inspired agents. Of course, I refer to the World Wide Web.
In this article, you learn how to code in a new way, a way that's about changing media, not about changing programs. To enter this nightclub and experience the beat, you need the right gear, and the right gear is Mozilla Firefox and GreaseMonkey. Alfred Bester and William Gibson are waiting, so ready your Mojo and prepare for cyberspace insertion. But first, a bit of background.
We tend to forget that the Web is open source, in a way. Some of the Web's infrastructure, browsers and servers, is traditional open-source software, but the idea also applies to Web page content. Appropriation of code is an everyday occurrence. Everyday, Web developers and designers use the View Source browser feature to appropriate (industry term: steal) code and design from other people's pages. It was ever thus, and it remains so. Ideas and code are shared freely and often; it's an art design sensibility.
Most technical people have dabbled with Web development, and dabbling is an easy way to have a bad experience. The big three technologies—HTML, CSS and JavaScript—were riddled with bugs for many years after their inception. That's the experience that probably looms large for early adopters who first tried it out in the 1990s and walked away in disgust. Cross-browser code? No, thank you.
Fortunately, matters have improved tremendously as of late, and the Web is reviving as a technology platform. Better standards support, more standards support and the decline of hoary old misgivings, such as Netscape Communication 4.x and Internet Explorer 5.0, have left Web developers with a nearly clear shot at real portability, a shot frustrated only by the once shiny but now fairly rusty Internet Explorer. In 2005, the buzz is about Modern DHTML, Layout without Tables, Semantic Markup and Asynchronous JavaScript and XML (AJAX). Client-side Web development is coming back, and these are the things of which it's made. This time, the Web is backed by professionals with formal Web training and veterans with ten years of experience. These people have their acts together, and it's possible to say things about Web technology that are no longer drowned out by the static of incompatibility issues.
Supporting and colonizing this trend is the Mozilla Firefox Web browser, and Mozilla technology in general. Of course, Mozilla is fully open source, as open as a religious movement can be, and so there's plenty of room for experimentation. The critical bit of Mozilla and Firefox is its interpreted nature. On top of a big, bad, networked C++ rendering engine is a thin skin of JavaScript scripts and XUL, an XML dialect. This makes Mozilla a distant cousin to Emacs or Tcl/Tk, as it provides the whole Firefox user interface by way of interpreted code. By writing an extension, you can enhance this user interface and drop it in to thousands of willing people's daily experience. Go to update.mozilla.org to see the endless possibilities made real by this system. Every variant hardware device requires Linux kernel driver support; every variant human expectation about user interfaces requires a Firefox extension. That's a lot of extensions.
GreaseMonkey is a Firefox extension (see the on-line Resources). You have to click on the link twice, once to trust www.mozdev.org and once afterward to install the extension. GreaseMonkey differs from the other extensions because it provides no specific user-interface enhancements of its own other than a configuration dialog box. Instead, it creates a macro-like scripting environment into which you put JavaScript scripts. Those scripts operate on Web pages that you specify. When such a page loads, your script goes to work on the page content, no matter who provided it. You're intercepting a content provider's content and modifying it before it hits you. No wonder GreaseMonkey's been called “TiVo for the Web”. I wrote about page modification tactics in Rapid Application Development with Mozilla (Prentice Hall, 2004), but GreaseMonkey has moved that idea into the mainstream by supporting traditional Web-scripting techniques and by packaging it all up into a digestible product.
For all Firefox extensions, you must restart Firefox completely to finish the install. Use File→Exit to do that safely.
Bucket-loads of pre-existing GreaseMonkey scripts are available (see Resources). Before you get too excited though, note that such scripts are tied to one Firefox installation and have no effect on any server. On a Linux or UNIX box, such scripts might affect a large user population, but they're primarily a personal thing. For those readers switched on to people problems, the broader implications should be obvious.
To see all this at work, in this article I hack the Linux Journal Web site with GreaseMonkey. My esteemed editor, Don Marti, even asked me to do this. A brave man indeed. [Maybe next time they'll invite me to the Web site meeting. —Ed.]
Give me a hill and I'll climb it. First up is a bit of scrutiny of the site due for surgery. Recall it's www.linuxjournal.com, if you're reading this in print. This is also the fun part; personal tastes differ, and for user-side drivers—which effectively is what GreaseMonkey scripts are—it's entirely valid and professional to be picky and subjective. In Mozilla-land, dogfood means testing your fixed bugs for technical correctness, and catfood means testing your inventions against unreliable and subjective people who might spring in any direction. It's all catfood here, and there's no right or wrong. After reading this article, LJ's long-suffering site maintainer will likely glare at me venomously or perhaps change the site before this sees print. Design sensibilities, you see. Sorry mate, they made me do it. Hard-core engineers should look away; you might find this analysis distressing. On to the site.
Here's a handful of observations.
The site icon, which appears in the location bar and on the current tab if you use tabbed browsing is dinky and uninspired. Oh well.
There's advertising everywhere.
Linux Journal's supposed to be the granddaddy of technical journals in open source, excluding academia and professional bodies. Where's that indicated?
The headings are red. What's with red? I'm not in a hurry.
On the plus side—my survival as a critic is at stake—the site has a robust three-column layout and is clean overall. Someone knows their stuff. Viewing the source, the layout is all done with CSS, so that's relatively modern; many industry sites still pump out the worst HTML you can imagine. The excessive use of <DIV> tags shows that LJ is halfway through modernisation; there's still some Semantic Markup work to go, where meaningful tags are used as content descriptors instead of the meaningless <DIV>. That update might improve the site's search engine performance or so it's claimed.
Now, of the above personal observations, some are simple to rectify and do not require GreaseMonkey. If you dislike advertising, then the AdBlock extension is for you; there's nothing, or at least little, to code. Similarly, for a long time, all browsers have supported user-specified stylesheets. If you install the ChromEdit extension, you can get at that stylesheet without having to grovel through the filesystem looking for it. Bring it up via Tools→Edit User Files, click the userContent.css tab and start typing. To make headings blue, you might add:
h1.title a { color : blue !important; }
@-moz-document domain(linuxjournal.com) {
h1.title a { color : blue !important; }
}
The first rule applies to all Web sites; the second is a Mozilla special that applies only to the Web site specified. Browser-specific is okay here, because we're working purely on and in the client side.
You can get a lot done in these stylesheets, especially if you know CSS well. You can hack the page's layout to bits by reordering, hiding or floating columns and other content. All of these options are possible via GreaseMonkey as well, but GreaseMonkey is better suited to bigger stuff. In other words, don't go to GreaseMonkey if page changes are easily solved with a stylesheet; it's overkill.
For this article, we'll make one simple change. We'll bring some gravitas to the site by replacing some content with fancy calligraphy drawn from another site.
The CSS :first-letter pseudo-selector lets you take an ordinary paragraph of text and make the first letter big, so that several lines of text flow around it. It's a self-important feature and what we're looking for. We simply could apply that feature, but most computers don't have fancy Medieval fonts installed. And, a big Times Roman letter F isn't that exciting. It would be better if we could get the LinuxJournal.com Web site properly illuminated, like the Book of Kells, with extra fancy calligraphy.
Here are a couple of screenshots showing the before and after looks, taken on Windows XP Professional. This is a timely reminder that the user experience is what's important here. It also emphasizes that open source means cross-platform when stated in Mozilla terms. Everything described in this article works identically on Windows, Macintosh, Linux and various obscure Mozilla platforms, such as Solaris.
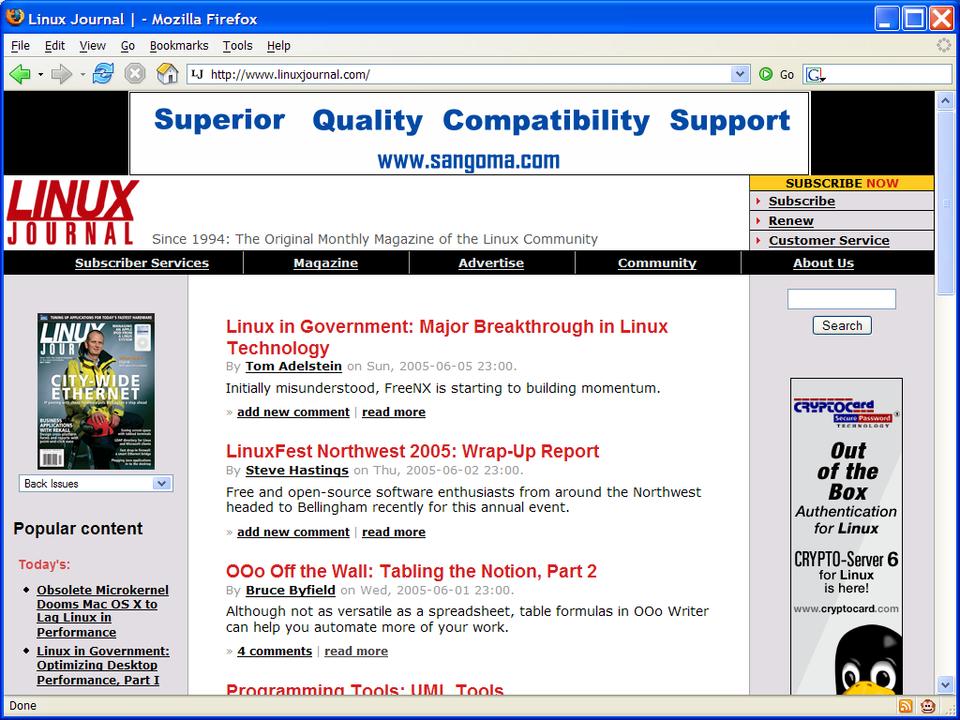
Figure 1. A Regular Linux Site
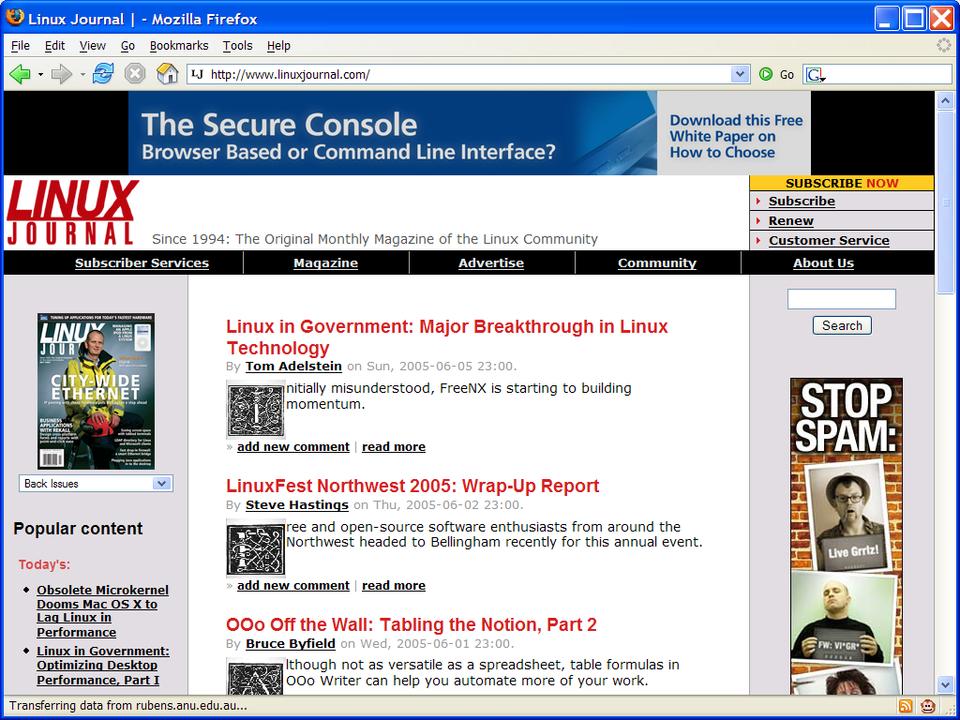
Figure 2. That's better. We didn't need monks to illuminate this manuscript, simply a GreaseMonkey script.
In the second screenshot, you can see that the first letter of each paragraph has been replaced with a fancy illuminated letter. Because I don't have access to the back end of the LJ Web site, that's something of a feat. In fact, these images come from the Australian National University's Medieval Studies image server.
I've used the thumbnail images only. It's a bit naughty to serve up some other Web site's images, and these images aren't perfectly cropped, registered scans, but for the purposes of, well, illustrating a technique, they'll do. Let's hope some parsiminous old sod doesn't take them down by the time you read this.
To make this embellishment work, you need a GreaseMonkey JavaScript script. To make such a script, proceed as though this was any other Web page project. I saved to local disk the LJ home page and then added this to the end of the <head> section:
<script src="illuminate.js></script>
Now I'm free to develop that script in pure Mozilla JavaScript, with no cross-browser constraints, because GreaseMonkey works only on Firefox. Let me tell you, it's real 200%-proof pleasure to charge forward in JavaScript without once having to trip over document.all or other MSIE abberations. More than that, there's a bit of now-established rigor we can bring to the code. Here's a skeleton of the job at hand, in the shape of a JS object signature, which is the bit of syntactic dogma that I like to propagate:
var illuminate = {
caps : { ... },
load : function () { ... },
image : function (text) { ... },
mask : function () { ... },
insert : function () { ... },
getElements : function (node) { ... },
getElementsRecursive : function (l, n) { ... },
};
There's no static typing and barely any forward declarations in JavaScript, so there's nowhere to declare an object. Instead, we work with an object literal. This approach creates a packaged set of functionalities that expose only the illuminate option to the page's namespace. So it's both a reuse strategy and a namespace non-pollution strategy. All the methods of the object are expressed as anonymous functions, and caps is a sub-object in which we put data. Anonymous functions also save you from forcing a function name into the page's namespace. That's a vast improvement on early scripting techniques.
Once defined, this object does nothing. You need a line such as this to make it go:
window.onload = function () { illuminate.load(); }
That causes the load() method to run when the page is finished loading. The anonymous function that wraps it provides an extra scope that makes illuminate the current object. Done that way, the reference points to the illuminate object, which means this can be exploited from inside the methods of the object. That saves the object from ever having to use the illuminate variable name—more namespace non-pollution.
Listing 1 shows this object fully implemented, so let's go through it. You also can grab the complete script from the Linux Journal FTP site.
The caps associative array points to the individual letters available at the ANU Web site. Because they're from Medieval times, new-fangled letters such as J, U, W and Y are nowhere in sight. We simply have to do without those for now and also resist the urge to use I for J biblically. The alphabet's constantly changing, albeit slowly, anyway. The way I hear it, if radio is a true reflection of the street argot, Double-u is next to undergo change. Evidently it's being replaced with an identical letter named Dub, as in: “Go to Dub Dub Dub dot sell you something dot com”. Think what you will of that despicable trend. But I digress.
The load() method does all the work. It calls mask(), which inserts a <style> tag as the last thing in the head of the current page. Careful study of the neatly designed LJ home page lets one create styles that fit like extra jigsaw pieces in the existing layout regime. This first style acts on the new illuminated letters, allowing text to flow around them:
div.node > div.content > img[ill]
{ display : inline; float : left; }
This next style stops the float effect so that the next news item doesn't flow around it as well:
div.node > div.links { clear : left; }
That's all standard CSS2 stuff. Finally, the rest of the JavaScript code is a bit over-enthusiastic in its page hacks, as you will see. So, here's a style to shut up the accidental extras:
img[ill] : { display : none; }
In all cases, the ill bit is simply a custom tag attribute added to identify the images specific to this script, so that they can be picked out easily with a style rule.
The second thing that the load() method does is call the insert() method, which adds <img> tags to the main content of the page. To those who dabble only in client-side scripting, perhaps an onclick handler or two, this looks fairly formidable, but it's pretty routine stuff for quality client-side scripting.
The insert() method acquires a list of important nodes in the page using the now robustly supported DOM APIs. It then uses a loop to run through that list, adding an <img> tag of this kind:
<img ill="true" width="64px" height="64px" src="">
This is added to every node found that has a Text node as its first child. That amounts to adding a new child node to any <div class=“content”> tag that's immediately inside a <div class=“node”> tag. That's a big assumption about the page's structure. Also, there are many unwanted examples of that combination, for instance, in the advertising column on the right and in miscellaneous content outside the list of articles. That's why I had to shut up some images with an extra style—too many are inserted. It keeps the code simple to use a broad brush, though.
While developing this, I also noticed that on one instance of the home page, someone had added extra <p> tags to the deck of one article. The deck is the lead-in remarks that draw the reader to the full article content. That's a simple typo or random act of innovation on some editor's part. For that one article, displayed in a layout marginally different to the rest, the script failed to do anything. At least that's better than generating an error or an exception and halting. It does go to show, though, how fragile GreaseMonkey scripts can be if one's not circumspect enough and has ignored the matter of graceful degradation, in which scripts melt away to NO-OPs if things go pear-shaped. Any assumptions made about the page's expected structure should be as general and as flexible as possible. Tread lightly.
Back in the code, insert() also uses standard JavaScript string operations to chop the first character off the deck's text. So that's one plain textual character gone, one image of a character added. Between the Web and Unicode, saying the word character without caution is to flush out in a trice all the lexicographical pedants lurking in the woodwork. Let them come, I say.
The rest of the object is some routine processing leveraged by the insert() method. The image() function is the easier utility: it merely performs a dictionary look-up on the caps object, which is effectively an associative array. JavaScript allows literal strings to be used as array indices and object member names. The retrieved file name is concatenated into a full URL and returned. It's simple data-driven programming.
The other utility is the remaining two methods, getElements() and getElementsRecursive(). They implement a standard prefix tree-walking algorithm that acts on the whole DOM of the page and that is wrapped up in the neater facade of getElements(). They are page-scanning routines and not overly general as there are logic tests inside specific to Linux Journal content. Someone should write a set of qsort(3)-like navigation routines so one simply can plug in a comparator functor or two. Probably that's already been done, but I haven't tracked down such a thing for this article.
As the DOM tree is walked, any <div class=“content”> nodes are appended to the list of discovered nodes. There's no copying at work; it's all nodes by reference. Walking a whole DOM tree is a bit ambitious. For more focused GreaseMonkey hacks, it's more efficient to go straight to the page element at issue, perhaps with a document.getElementById() call. When you're not sure about the exact structure of the page, though, it's better to grope blindly through all the content with a minimum of assumptions. How directly you proceed simply depends on what kind of leverage you're looking for.
Now that the script is developed, all that needs to be done is to configure it into the GreaseMonkey extension. Recall that so far it has been developed on a static and locally held test page. That configuration task is, to be frank, a bit weird, at least at GreaseMonkey 0.3.3.
To get it in place, make sure the script is named illuminate.user.js. Next, using Firefox with GreaseMonkey installed, navigate to the local directory where the script is. On Linux that is something like:
file:///home/nrm/
On Windows it may start with:
file:///C|/Documents%20and%20Settings/nrm/Desktop/
Notice the three forward slashes. The file URI scheme is similar to NFS or SMB and, in theory, can retrieve files located anywhere, for example:
file://www.example.com/something.txt
Omit a domain and the default is localhost, which generally is what you want.
Once that directory listing appears, you should see a link for the illuminate.user.js file. Right-click on it (context-click on Mac OS X), and the magic option is revealed: “Install User Script ...”. Pick that, because no amount of fiddling with the GreaseMonkey options on the Tools menu can bring you equal joy. The GreaseMonkey configuration dialog box appears next, with the new script lodged on the left. Click Add on the right, and type in the Linux Journal URL, like so:
http://www.linuxjournal.com/*
Click OK and the script's installed. Now it can be reached via the Tools menu for subsequent administration. Reload the LJ page and everything should work, with illuminated capitals in place. If not, it's time to open the JavaScript Console and go back to script debugging, testing with 1.0.4 and GreaseMonkey 0.3.3.
The tale of illuminated capitals thus is told, and it's a tale of content aggregation. Of course, this is but a trivial example. You're not restricted to patching-in a single, grubby <img> tag, nor must you be so sanguine about the existing page content. GreaseMonkey scripts can hack the page content to bits, and you can stick any amount of extra content into the page, from any source. The redoubtable XMLHttpRequest object is available to such scripts, and it can be used to load any content in the world that's accessible by HTTP— content that then can be put in the current page. You also can send bits of the current page elsewhere with this object, but that's another article. Here I've attempted a graceful addition to the page.
Now you might say, “this is an exercise in folly, no one will see my work but me.” That, however, simply is a distribution problem, one solvable by many different IT deployment techniques, not the least of which is hypertext links.
Such enhancements are not so silly either. Imagine the Web interface to your favourite network device, perhaps a router. Wouldn't it be nice if the host status lights from the open-source and Web-enabled Big Brother LAN-monitoring application appeared next to the IP addresses of the matching hosts in the filtering rules in the Web pages served up by that router? At least then you wouldn't be trying to fix a route for a box that's not even running in the first place. You'd see a big red light next to the entry in the router's configuration pages. GreaseMonkey is exactly the right tool for such problems, especially since no one has access to the source pages generated by the router's embedded Web server.
Furthermore, many Web pages are busy places, full of navigation widgets and data entry fields. GreaseMonkey scripts can hack all that to bits, removing or adding elements to the page that streamline the user's individual surfing behaviour. Don't like that menu bar at the top? Hide it. Can't remember how to fill in that form? Add some reminder text that floats above it. You get the idea.
Finally, because GreaseMonkey is content-based, analogies with other content media are worth considering. If there are hit records and hit movies, then a hit GreaseMonkey script no doubt will emerge in time. What political orientation it has with respect to the Web site it hacks will set a very interesting precedent. Will it be a script that protests, deconstructs, graffitis, supports or censures the site in question? Only time will tell. In the meantime, GreaseMonkey is a handy tool for Web content that's otherwise difficult to change.
Resources for this article: /article/8458.