Using Bayesian statistics to detect an e-mail's spamminess.
Most people are spending significant time daily on the task of distinguishing spam from useful e-mail. I don't think I'm alone in feeling that we have better things to do. Spam-filtering software can help.
This article discusses one of many possible mathematical foundations for a key aspect of spam filtering—generating an indicator of “spamminess” from a collection of tokens representing the content of an e-mail.
The approach described here truly has been a distributed effort in the best open-source tradition. Paul Graham, an author of books on Lisp, suggested an approach to filtering spam in his on-line article, “A Plan for Spam”. I took his approach for generating probabilities associated with words, altered it slightly and proposed a Bayesian calculation for dealing with words that hadn't appeared very often. Then I suggested an approach based on the chi-square distribution for combining the individual word probabilities into a combined probability (actually a pair of probabilities—see below) representing an e-mail. Finally, Tim Peters of the Spambayes Project proposed a way of generating a particularly useful spamminess indicator based on the combined probabilities. All along the way the work was guided by ongoing testing of embodiments written in Python by Tim Peters for Spambayes and in C by Greg Louis of the Bogofilter Project. The testing was done by a number of people involved with those projects.
We will assume the existence of a body of e-mails (the corpus) for training, together with software capable of parsing each e-mail into its constituent words. We will further assume that each training e-mail has been classified manually as either “ham” (the e-mail you want to read) or “spam” (the e-mail you don't). We will use this data and software to train our system by generating a probability for each word that represents its spamminess.
For each word that appears in the corpus, we calculate:
b(w) = (the number of spam e-mails containing the word w) / (the total number of spam e-mails).
g(w) = (the number of ham e-mails containing the word w) / (the total number of ham e-mails).
p(w) = b(w) / (b(w) + g(w))
p(w) can be roughly interpreted as the probability that a randomly chosen e-mail containing word w will be a spam. Spam-filtering programs can compute p(w) for every word in an e-mail and use that information as the basis for further calculations to determine whether the e-mail is ham or spam.
However, there is one notable wrinkle. In the real world, a particular person's inbox may contain 10% spam or 90% spam. Obviously, this will have an impact on the probability that, for that individual, an e-mail containing a given word will be spam or ham.
That impact is ignored in the calculation above. Rather, that calculation, in effect, approximates the probabilitily that a randomly chosen e-mail containing w would be spam in a world where half the e-mails were spams and half were hams. The merit of that approach is based on the assumption that we don't want it to be harder or easier for an e-mail to be classified as spam just because of the relative proportion of spams and hams we happen to receive. Rather, we want e-mails to be judged purely based on their own characteristics. In practice, this assumption has worked out quite well.
There is a problem with probabilities calculated as above when words are very rare. For instance, if a word appears in exactly one e-mail, and it is a spam, the calculated p(w) is 1.0. But clearly it is not absolutely certain that all future e-mail containing that word will be spam; in fact, we simply don't have enough data to know the real probability.
Bayesian statistics gives us a powerful technique for dealing with such cases. This branch of statistics is based on the idea that we are interested in a person's degree of belief in a particular event; that is the Bayesian probability of the event.
When exactly one e-mail contains a particular word and that e-mail is spam, our degree of belief that the next time we see that word it will be in a spam is not 100%. That's because we also have our own background information that guides us. We know from experience that virtually any word can appear in either a spam or non-spam context, and that one or a handful of data points is not enough to be completely certain we know the real probability. The Bayesian approach lets us combine our general background information with the data we have collected for a word in such a way that both aspects are given their proper importance. In this way, we determine an appropriate degree of belief about whether, when we see the word again, it will be in a spam.
We calculate this degree of belief, f(w), as follows:
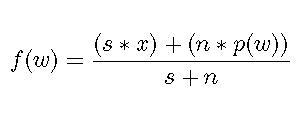
Equation 1
where:
s is the strength we want to give to our background information.
x is our assumed probability, based on our general backround information, that a word we don't have any other experience of will first appear in a spam.
n is the number of e-mails we have received that contain word w.
This gives us the convenient use of x to represent our assumed probability from background information and s as the strength we will give that assumption. In practice, the values for s and x are found through testing to optimize performance. Reasonable starting points are 1 and .5 for s and x, respectively.
We will use f(w) rather than p(w) in our calculations so that we are working with reasonable probabilities rather than the unrealistically extreme values that can often occur when we don't have enough data. This formula gives us a simple way of handling the case of no data at all; in that case, f(w) is exactly our assumed probability based on background information.
Those who are interested in the derivation of the above formula, read on; others may want to skip down to the next section.
If you are already familiar with the principles of Bayesian statistics, you will probably have no trouble understanding the derivation. Otherwise, I suggest that you read sections 1 and 2 of David Heckerman's “A Tutorial on Learning with Bayesian Networks” (see Resources) before continuing.
The formula above is based on assuming that spam/ham classification for e-mails containing word w is a binomial random variable with a beta distribution prior. We calculate the posterior expectation after incorporating the observed data. We are going to do a test that is the equivalent of the “experiment” of tossing a coin multiple times to see whether it appears to be biased. There are n trials. If we were tossing a coin, each coin toss would be a trial, and we'd be counting the number of heads. But in our case, the trial is looking at the next e-mail in the training corpus that contains the word “porn” and seeing whether the e-mail it contains is a spam. If it is, the experiment is considered to have been successful. Clearly, it's a binomial experiment: there are two values, yes or no. And they are independent: the fact that one e-mail contains “porn” isn't correlated to the question of whether the next one will. Now, it happens that if you have a binomial experiment and assume a beta distribution for the prior, you can express the expectation that the nth + 1 trial will be successful as shown in Equation 2.
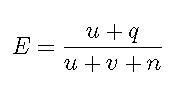
Equation 2
q is the number of successes.
n is the number of trials.
u and v are the parameters of the beta distribution.
We want to show that Equation 1 is equivalent to Equation 2. First perform the following substitutions:
s = u + v s * x = u
The next step is to replace q with n * p(w). We have already discussed the fact that p(w) is an approximation of the probability that a randomly chosen e-mail containing w is spam in an imaginary world where there are the same number of spams as hams. So n * p(w) approximates the count of spams containing w in that world. This approximates the count of successes in our experiment and is therefore the equivalent of q. This completes our demonstration of the equivalence of Equations 1 and 2.
In testing, replacing p(w) with f(w) in all calculations where p(w) would otherwise be used, has uniformly resulted in more reliable spam/ham classification.
At this point, we can compute a probability, f(w), for each word that may appear in a new e-mail. This probability reflects our degree of belief, based on our background knowledge and on data in our training corpus, that an e-mail chosen randomly from those that contain w will be a spam.
So each e-mail is represented by a set of of probabilities. We want to combine these individual probabilities into an overall combined indicator of spamminess or hamminess for the e-mail as a whole.
In the field of statistics known as meta-analysis, probably the most common way of combining probabilities is due to R. A. Fisher. If we have a set probabilities, p1, p2, ..., pn, we can do the following. First, calculate -2ln p1 * p2 * ... * pn. Then, consider the result to have a chi-square distribution with 2n degrees of freedom, and use a chi-square table to compute the probability of getting a result as extreme, or more extreme, than the one calculated. This “combined” probability meaningfully summarizes all the individual probabilities.
The initial set of probabilities are considered to be with respect to a null hypothesis. For instance, if we make the null hypothesis assumption that a coin is unbiased, and then flip it ten times and get ten heads in a row, there would be a resultant probability of (1/2)10 = 1/1024. It would be an unlikely event with respect to the null hypothesis, but of course, if the coin actually were to be biased, it wouldn't necessarily be quite so unlikely to have an extreme outcome. Therefore, we might reject the null hypothesis and instead choose to accept the alternate hypothesis that the coin is biased.
We can use the same calculation to combine our f(w)s. The f(w)s are not real physical probabilities. Rather, they can be thought of as our best guess about those probabilities. But in traditional meta-anaytical uses of the Fisher calculation they are not known to be the real probabilities either. Instead, they are assumed to be, as part of the null hypothesis.
Let our null hypothesis be “The f(w)s are accurate, and the present e-mail is a random collection of words, each independent of the others, such that the f(w)s are not in a uniform distribution.” Now suppose we have a word, “Python”, for which f(w) is .01. We believe it occurs in spams only 1% of the time. Then to the extent that our belief is correct, an unlikely event occurred; one with a probability of .01. Similarly, every word in the e-mail has a probability associated with it. Very spammy words like porn might have probabilities of .99 or greater.
Then we use the Fisher calculation to compute an overall probability for the whole set of words. If the e-mail is a ham, it is likely that it will have a number of very low probabilities and relatively few very high probabilities to balance them, with the result that the Fisher calculation will give a very low combined probability. This will allow us to reject the null hypothesis and assume instead the alternative hypothesis that the e-mail is a ham.
Let us call this combined probability H:
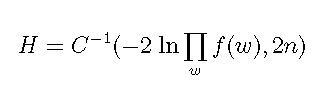
Equation 3
where C-1() is the inverse chi-square function, used to derive a p-value from a chi-square-distributed random variable.
Of course, we know from the outset the null hypothesis is false. Virtually no e-mail is actually a random collection of words unbiased with regard to hamminess or spamminess; an e-mail usually has a telling number of words of one type or the other. And certainly words are not independent. E-mails containing “sex” are more likely to contain “porn”, and e-mails containing the name of a friend who programs Python are more likely also to contain “Python”. And, the f(w)s are not in a uniform distribution. But for purposes of spam detection, those departures from reality usually work in our favor. They cause the probabilities to have a nonrandom tendency to be either high or low in a given e-mail, giving us a strong statistical basis to reject the null hypothesis in favor of one alternative hypothesis or the other. Either the e-mail is a ham or it is a spam.
So the null hypothesis is a kind of straw dog. We set it up only in order for it to be knocked down in one direction or the other.
It may be worthwhile to mention here a key difference between this approach and many other combining approaches that assume the probabilities are independent. This difference applies, for example, to such approaches as the “Bayesian chain rule” and “Naïve Bayesian classification”. Those approaches have been tested in head-to-head combat against the approach described here using large numbers of human-classified e-mails and didn't fare as well (i.e., didn't agree as consistently with human judgment).
The calculations for those approaches are technically invalid due to requiring an independence of the data points that is not actually present. That problem does not occur when using the Fisher technique because the validity of the calculations doesn't depend on the data being independent. The Fisher calculation is structured such that we are rejecting a null hypothesis that includes independence in favor of one of the two alternative hypotheses that are of interest to us. These alternative hypotheses each involve non-independence, such as the correlation between “sex” and “porn”, as part of the phenomenon that creates the extreme combined probabilities.
These combined probabilities are only probabilities under the assumption that the null hypothesis—known to be almost certainly false—is true. In the real world, the Fisher combined probability is not a probability at all, but rather an abstract indicator of how much (or little) we should be inclined to accept the null hypothesis. It is not meant to be a true probability when the null hypothesis is false, so the fact that it isn't doesn't cause computational problems for us. The naïve Bayesian classifier is known to be resistant to distortions due to a lack of independence, but it doesn't avoid them entirely.
Whether these differing responses to a lack of independence in the data are responsible for the superior performance of Fisher in spam/ham classification testing to date is not known, but it is something to consider as one possible factor.
The individual f(w)s are only approximations to real probabilities (i.e., when there is very little data about a word, our best guess about its spam probability as given by f(w) may not reflect its actual reality). But if you consider how f(w) is calculated, you will see that this uncertainty diminishes asymptotically as f(w) approaches 0 or 1, because such extreme values can be achieved only by words that have occurred quite frequently in the training data and either almost always appear in spams or almost always appear in hams. And, conveniently, it's the numbers near 0 that have by far the greatest impact on the calculations. To see this, consider the influence on the product .01 * .5 if the first term is changed to .001, vs. the influence on the product .51 *.5 if the first term is changed to .501, and recall that the Fisher technique is based on multiplying the probabilities. So our null hypothesis is violated by the fact that the f(w)s are not completely reliable, but in a way that matters vanishingly little for the words of the most interest in the search for evidence of hamminess: the words with f(w) near 0.
Alert readers will wonder at this point: “Okay, I understand that these Fisher calculations seem to make sense for hammy words with correspondingly near-0 probabilities, but what about spammy words with probabilities near 1?” Good question! Read on for the answer that will complete our discussion.
The calculation described above is sensitive to evidence of hamminess, particularly when it's in the form of words that show up in far more hams than spams. This is because probabilities near 0 have a great influence on the product of probabilities, which is at the heart of Fisher's calculation. In fact, there is a 1971 theorem that says the Fisher technique is, under certain circumstances, as powerful as any technique can possibly be for revealing underlying trends in a product of possibilities (see Resources).
However, very spam-oriented words have f(w)s near 1, and therefore have a much less significant effect on the calculations. Now, it might be assumed that this is a good thing. After all, for many people, misclassifying a good e-mail as spam seems a lot worse than misclassifying a bad e-mail as a ham, because no great harm is done if a single spam gets through but significant harm might result from a single good e-mail being wrongly classified as spam and therefore ignored by the recipient. So it may seem good to be sensitive to indications of hamminess and less sensitive to indications of spamminess.
However, there are ways to deal with this problem that in real-world testing do not add a noticeable tendency to wrongly classify good e-mail as spam, but do significantly reduce the tendency to misclassify spam as ham.
The most effective technique that has been identified in recent testing efforts follows.
First, “reverse” all the probabilities by subtracting them from 1 (that is, for each word, calculate 1 - f(w)). Because f(w) represents the probability that a randomly chosen e-mail from the set of e-mails containing w is a spam, 1 - f(w) represents the probability that such a randomly chosen e-mail will be a ham.
Now do the same Fisher calculation as before, but on the (1 - f(w))s rather than on the f(w)s. This will result in near-0 combined probabilities, in rejection of the null hypothesis, when a lot of very spammy words are present. Call this combined probability S.
Now calculate:
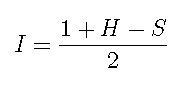
Equation 4
I is an indicator that is near 1 when the preponderance of the evidence is in favor of the conclusion that the e-mail is spam and near 0 when the evidence points to the conclusion that it's ham. This indicator has a couple of interesting characteristics.
Suppose an e-mail has a number of very spammy words and also a number of very hammy words. Because the Fisher technique is sensitive to values near 0 and less sensitive to values near 1, the result might be that both S and H are very near 0. For instance, S might be on the order of .00001 and H might be on the order of .000000001. In fact, those kinds of results are not as infrequent as one might assume in real-world e-mails. One example is when a friend forwards a spam to another friend as part of an e-mail conversation about spam. In such a case, there will be strong evidence in favor of both possible conclusions.
In many approaches, such as those based on the Bayesian chain rule, the fact that there may be more spammy words than hammy words in an example will tend to make the classifier absolutely certain that the e-mail is spam. But in fact, it's not so clear; for instance, the forwarded e-mail example is not spam.
So it a useful characteristic of I that it is near .5 in such cases, just as it is near .5 when there is no particular evidence in one direction or the other. When there is significant evidence in favor of both conclusions, I takes the cautious approach. In real-world testing, human examination of these mid-valued e-mails tends to support the conclusion that they really should be classified somewhere in the middle rather than being subject to the black-or-white approach of most classifiers.
The Spambayes Project, described in Richie Hindle's article on page 52, takes advantage of this by marking e-mails with I near .5 as uncertain. This allows the e-mail recipient to give a bit more attention to e-mails that can't be classified with confidence. This lessens the chance of a good e-mail being ignored due to incorrect classification.
To date, the software using this approach is based on one word per token. Other approaches are possible, such as building a hash table of phrases. It is expected that the math described here can be employed in those contexts as well, and there is reason to believe that phrase-based systems will have performance advantages, although there is controversy about that idea. Future Linux Journal articles can be expected to cover any developments in such directions. CRM114 (see Resources) is an example of a phrase-based system that has performed very well, but at the time of this writing it hasn't been directly tested against other approaches on the same corpus. (At the time of this writing, CRM114 is using the Bayesian chain rule to combine p(w)s.)
The techniques described here have been used in projects such as Spambayes and Bogofilter to improve performance of the spam-filtering task significantly. Future developments, which may include integrating these calculations with a phrase-based approach, can be expected to achieve even better performance.