Let one packet go to multiple addresses and you can save much bandwidth. That's the promis of IP multicasting, and here's how Linux handles it.
In this article I explain how the Linux kernel manages multicast traffic and how it is possible to interact with it by simply patching some kernel code. Although this is a rather specific topic, it might be useful for anyone interested in multicast routing. If you want to monitor or modify any existing multicast protocol, the information provided below will be useful.
At the University of Milan, we are developing a new protocol, CAMP (Call Admission Multicast Protocol), that uses information provided by the multicast kernel code to make some important decisions. We have to be able to receive notifications of important events, such as JOIN or LEAVE requests. As you probably know, the Linux kernel can act as a multicast router, supporting both versions 1 and 2 of PIM (Protocol Independent Multicast, netweb.usc.edu/pim). All the MFC (Multicast Forwarding Cache) update operations are served completely by an external user-mode process interacting with the kernel. In this article, we explain how the kernel manages messages sent by the user-mode dæmon in order to update the MFC. After this brief introduction we describe our hook implementation in more detail. Figure 1 shows the topology of our testing network. As you can see, SNOOPY is acting as a multicast router running PIMd (version 2.1.0-alpha 29.9) on top of Linux kernel 2.4.18.
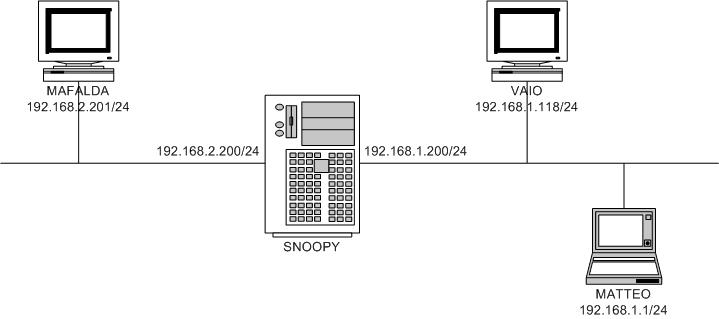
Figure 1. Test Network Topology
All the multicast-related code of the kernel is located in two files: ipmr.c (net/ipv4/ipmr.c) and mroute.h (include/linux/mroute.h). Before we start looking at the code, it is important to mention two other files: /proc/net/ip_mr_vif and /proc/net/ip_mr_cache. As we will see later, these two files are particularly useful for understanding the current state of the multicast router. The ip_mr_vif file lists all the virtual interfaces involved in multicast operations, while ip_mr_cache exactly represents the state of the MFC.
Now, as an example, we start sending out multicast traffic from VAIO to the address 224.225.0.1. Packets are received by SNOOPY but are not forwarded to eth1 because no JOIN has been issued by MAFALDA. When MAFALDA does issue a JOIN to 224.225.0.1, the contents of the two proc files (on SNOOPY) are shown in Table 1 and Table 2.
Table 1. Content of /proc/net/ip_mr/vif
Table 2. Content of /proc/net/ip_mr_cache
In ip_mr_vif the two interfaces (eth0 and eth1) involved in our multicast routing are listed, while the third interface (pimreg) is a virtual device registered by the multicast management code. In Table 2, you can see the route PIMd has built. Here, packets coming from eth0 (Iif: 0) with a source address equal to 192.168.1.118 (Origin: 7601A8C0) and directed to 224.225.0.1 (Group: 0100E1E0) are forwarded to eth1 (Oifs: 1:--ignore the second number at the moment). Now, we issue a LEAVE message from MAFALDA. After a couple of seconds the content of /proc/net/ip_mr_cache is updated, and the result is shown in Table 3.
Table 3. Content of /proc/net/ip_mr_cache after a LEAVE Message
We still have the same origin and group, but now the input interface has been changed to -1, and we have no output interfaces. This is because packets still are coming in from eth0, but because nobody wishes to receive them on other interfaces, they are dropped. When packets are dropped this way, a new entry is stored in a special queue of unresolved addresses. To indicate this is an unresolved address, the input interface is set to -1 and no output interfaces are listed.
This operation of queuing unresolved packets is necessary for a particular reason: receiving an IGMP packet and adding the corresponding MFC entry takes a lot of time (about 2-3 seconds on our test network and about 20-30 seconds on a bigger network with interconnected multicast routers). When VAIO started transmitting multicast packets in our previous example, there was a high probability that the JOIN message from MAFALDA wasn't yet handled by SNOOPY, and the corresponding MFC entry necessary to forwarding packets was not already set up. So, in order not to lose the packets received from VAIO while the JOIN request is handled and the new MFC entry is added, they are queued in this special cache. As soon as the MFC entry is added, the queue is cleaned up, and the packets waiting in it are forwarded to the right destination. Obviously, due to performance and memory restrictions, this queue cannot grow too large. This is solved by simply adding a timer function that periodically cleans up the cache of unresolved entries (ipmr_expire_process()).
Now, let's take a look at the data structures involved in this process (Listing 1).
Listing 1. The vif_device and mfc_cache structures used by the multicast routing code.
vif_device is a virtual device linked to a real network adapter. The dev field is a pointer to the net_device structure representing the real hardware interface. More interesting is the mfc_cache structure. Its fields are self-explanatory and reflect all the data shown in Tables 2 and 3.
The three main variables used in ipmr.c are as follows:
/* Devices */ static struct vif_device vif_table[MAXVIFS]; /* Forwarding cache */ static struct mfc_cache *mfc_cache_array[MFC_LINES]; /* Queue of unresolved entries */ static struct mfc_cache *mfc_unres_queue;
vif_table is simply an array of all the virtual devices created by PIMd; mfc_cache_array represents the MFC; and mfc_unres_queue is the list of unresolved entries described above. Prior to analyzing the multicast management code, it is worth spending a couple of words on the TTL array, a member of the mfc_cache structure. Each value of the array is linked directly to the vif_table. In fact, for each multicast address assigned to every interface, we have a single byte value identifying the TTL threshold. As we will see later, this value is compared to the TTL field of each IP packet when deciding if the packet is to be forwarded.
We have seen the basic data structure of multicast routing, so now let's take a look at how they are manipulated by the kernel. All the functions are implemented in one single file, ipmr.c. Keep in mind that the code in this file does not implement the routing protocol itself. The functions you can find in ipmr.c are used by the multicast routing dæmon (PIMd in our case) to manage these data structures. Simply put, whenever PIMd decides it's time to add or delete a route, it merely sends a message to the kernel specifying the action that should be taken. PIMd, in order to do that, must be able to receive IGMP packets; these are passed up to user space by the kernel. PIMd communicates to the kernel in two different ways: using ioctls and via the setsockopt() system call. Both the vif and mfc tables are handled using the setsockopt() system call.
In order to better understand how this is achieved we take a look at some of PIMd's code as well. In particular, all the functions communicating with the kernel are located in the kern.c file of the PIMd distribution. Here, the function k_chg_mfc() is responsible for adding or modifying an existing MFC entry, while the deletion of an existing entry is performed by k_del_mfc(). In order to tell the kernel how multicast packets should be forwarded, some information similar to that listed in the mfc_cache structures must be provided by the user dæmon. In particular, this information is encapsulated in a new structure defined as mfcctl (Listing 2).
Listing 2. The mfcctl used by PIMd.
The fields in this example should be self-explanatory. It's important to mention, though, the role of the mfc_ttls array in this structure. As stated earlier, this value represents the TTL threshold; however, it is treated in a slightly different way by the user-mode dæmon. The function k_chg_mfc() must specify to the kernel on which interfaces the multicast packet should be forwarded. In order to do so, a list of the output interfaces must be provided; the mfcc_ttls fills this role. The code snippet below shows this point:
for (vifi = 0, v = uvifs;
vifi < numvifs; vifi++, v++)
{
if (VIFM_ISSET(vifi, oifs))
mc.mfcc_ttls[vifi] = v->uv_threshold;
else
smc.mfcc_ttls[vifi] = 0;
}
Here, if an interface is indeed an output interface for a particular multicast address, its TTL threshold is set to the real value; otherwise it is set to zero. The kernel interprets the value zero as a non-output interface for that particular group, and as a consequence, it will set the corresponding byte of the mfc_cache structure equal to 255 (decimal) and not forward the packets.
Now, let's see what the kernel does when it receives a request to add a new entry to the MFC. The type request is handled by the ipmr_mfc_add() function. The kernel checks whether this is an update request by looking for the current entry in the MFC. If a matching item is found, the new TTL's values are copied into the existing mfc_cache structure, and the minvif and maxvif values are updated as well. These values indicate the minimum and the maximum index values of all output interfaces for a particular multicast address. The function performing this job is ipmr_update_thresholds(). For your convenience, we include the function shown in Listing 3, because it better explains the meaning of the minval and maxval fields.
Listing 3. How the kernel updates a current MFC entry.
Back to our ipmr_mfc_add() function; we now consider the case where an existing MFC entry is not found. In this case, a new structure is allocated and inserted into the MFC table. Once this operation is completed, the kernel must perform one last action: forwarding any unresolved multicast packet currently queued in the mfc_unres_queue that might be directed to the newly added destination node. In an affirmative case, packets are removed from this queue and forwarded to the new interface. The other operation that remains to be executed is the MFC delete. This one is pretty straightforward—data structures are basically the same as what was seen before. In order to remove a cache entry, the user-mode dæmon invokes the k_del_mfc() function while the handler for the kernel mode invokes the impr_mfc_delete(). This function simply removes the specified entry from the MFC.
Now that we have identified where MFC entries are added, modified and deleted, we can start hooking the multicast routing code. Function hooking is a simple concept. Basically, a function inserted in the middle of the code shown previously causes the system to switch to an external function implemented in a kernel module. In a way, the function implemented in the module can be seen as a callback that is invoked every time an MFC entry is added, modified or deleted. To implement this hooking mechanism, we based our code on a well-known hooking architecture already implemented in the 2.4.x kernel: the Netfilter interface. If you have never used it before, suffice to say it's a popular interface implemented within the kernel to allow packet filtering. The same action that Netfilter performs with packets can be done easily with arbitrary data structures—mfc_caches in our case. In particular, the following is the prototype of the callback function:
typedef void nf_nfy_msg(
unsigned int hook,
unsigned int msgno,
const struct net_device
*dev,
void* moreData);
Here, hook represents the domain (this value always will assume the PF_INET value); msgno represents the message number (the action taken by the kernel, adding an mfc_cache entry, for example); dev can assume the value of any current net_device involved during the operation; and moreData is a void* pointer to a generic data structure. This pointer is indeed a pointer to an mfc_cache data structure.
Now that we have seen the format of the callback let's see how it can be invoked by the kernel. It's actually quite simple; placing the following in the kernel code will invoke any registered hook function for the specified action:
#ifdef NF_EVT_HOOK && NF_MCAST_HOOK
NF_NFY_HOOK(
PF_INET,
NF_NFY_IP_MCAST_MSG,
IPMR_MFC_ADD,
NULL,
(void*) c);
#endif
However, the details about our hook architecture are beyond the scope of this article. The reader will understand the code better by looking at our modified kernel files [available from the Linux Journal FTP site at ftp.linuxjournal.com/pub/lj/listings/issue103/6070.tgz] or at the original Netfilter implementation.
Now that we have had a complete overview of the multicast routing implementation in Linux and a couple of notes about how to implement a hooking mechanism, it's necessary to pinpoint a couple of concepts we observed during our tests.
Let's go back to our testing network and imagine the following scenario: SNOOPY is sending out multicast traffic, and both MAFALDA and VAIO issue a JOIN request. You expect to see a new multicast route with eth0 and eth1 as output interfaces. Unfortunately, that is not what happens. Taking a look at /proc/net/ip_mr_cache, you can see only a single route to MAFALDA, but both MAFALDA and VAIO are receiving multicast traffic correctly. Here's why: outgoing packets from SNOOPY are sent using 192.168.1.200 as a source address. For that reason, when sending out data on eth0, SNOOPY will behave like it's sending out multicast traffic on a LAN. That means SNOOPY will start sending out packets on eth0 even before VAIO issues a JOIN, because the kernel is unaware of the presence of a PIM dæmon able to interpret IGMP packets coming from other PCs. In order to make other workstations receive multicast traffic, it simply sends out packets. This way, any other machine on the same network segment can turn on the multicast hardware filter and pick up the desired data from the wire. In a similar situation, multicast JOIN and LEAVE requests cannot be hooked on the primary interface, because on that interface the kernel is not exactly performing multicast routing.
