Being able to run Linux flawlessly on a machine with faulty memory that would otherwise be discarded makes a lot of sense—the BadRAM patch makes it happen.
There are several common causes for failure of memory modules. Before solving the problems in software, let's turn to these causes. To understand them, please take a look at Figure 1, which shows schematically what the structure of a (faultless) memory is. Note how the memory is laid out in a (roughly equal) number of rows and columns. Each crossing marks the location of a memory cell, usually storing a single bit. As a result, a memory cell's address is the combination of its row address and column address. Memory modules are fed with these two halves of the address separately (sequenced), so that their address bus is only half the size you would expect. This halving of addresses is handled a by the hardware on your motherboard.

Figure 1. Memory Structure without Problems
The first place where things can go wrong is during the manufacture of these memory modules. This is a very sensitive process, mainly because the dimensions of the chip layouts are getting smaller as the world grows hungry for more memory. Chip manufacture is also quite wasteful of environmental resources because a lot of highly purified chemicals are needed to construct the tiny, sand-derivative product that you eventually buy. Moreover, the sensitivity of the chip manufacturing process makes many chips fall out due to error.
One method of partially solving this problem is to build redundancy into the chips, say including 33 rows of memory cells for every 32 rows; when one row fails, route the signals around it to the extra row. Indeed, this technique is applied by some manufacturers. Nevertheless, unsustained rumors claim there still is a 60% drop-out rate. Needless to say, this factor makes memory expensive.
Errors caused during production can take the shape of a speck of dust that sat on the chip while enlightening or developing one of its layers, as in Figure 2. The grayed-out area is the part that may malfunction as a result of that speck of dust.
Figure 2. Memory Etching Disturbed
Another source of error is static discharge. This is the same effect that makes a woolen or nylon sweater spark a shock when taken off. The reason for the spark is a high voltage between two nearby surfaces. When they come close enough, the spark suddenly jumps over, ionizing the air it passes and, thus, suddenly making it conduct quite well, resulting in a high current for a very short period. Actually, this is the same effect as lightning, only not as powerful, of course. The small structures in a chip are quite sensitive to these aggressive discharges. Static discharge usually damages the “buffers”, the connections between rows/columns and the address selection logic, as shown in Figure 3. This effectively means that a whole row, or a whole column, or even a few of them, become unusable, shown again by the grayed-out area. There are the memory fault patterns that I have seen the most.
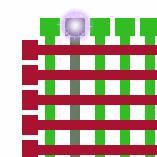
Figure 3. Memory Buffers Damaged by Static Discharge
A last source of error, and up to now I have no certain proof of ever having encountered it, is the gradual decay that all chips are subjected to. This is the process by which the sharply distinct regions of different materials on the chip blur and mix together. This is a natural effect, and if a chip is kept sufficiently cool, it usually takes decades to happen. In the case of memory, no problem, it usually gets outdated for its speed and size long before this point.
The important point of all these errors is that they stick—I am not aware of any technical cause that could lead to random errors. Mind you, it may happen that errors only occur in particular patterns of the surrounding bits, but even then, the error once settled, always occurs in that situation.
Furthermore, errors don't happen for no reason. In all of the above situations, a sudden burst of energy causes the errors, or they are caused by a very slow process. So, we need not expect errors to jump up all of the time, not even on a defective memory module.
Because errors in memories do not evolve, it is usually possible to circumvent the errors by making smart use of dynamic memory allocation techniques.
There are basically two ways of detecting errors in memories. One approach is the use of a special program that scans all of the memory in the machine and reports the failing addresses. One such program that excels in finding errors is memtest86, targeted at i386-based machines. Naturally, trusting the results from such a memory checker relies on the stability of memory errors, which usually turns out to be an okay assumption; I've been running my machine for months without a change in the detected error patterns.
The alternative is based on hardware detection. In the 30-pin SIMM days, it was quite common to include a ninth bit with “parity” information on the memory module. The idea is that the ninth bit, which is actually stored separately on the memory module, contains the bit to make the parity of the whole chip even (or odd, whatever the design of the motherboard wants). When writing, this bit is generated, and when reading back, it is checked. If this read-time check fails, a parity error is thrown.
A modern alternative to parity bits is ECC, short for Error Correction (and detection) Code. These are usually based on some CRC hash from the bits stored, and they can be used to detect up to three faulty bits out of 32, as well as to correct up to two faulty bits. (I am actually uncertain about these precise values, but it's the principle that counts.) So, with ECC RAM, it is possible to detect errors, as well as correct them if they are not too savage.
Modern memory modules as we use them in PC workstations usually come with neither parity nor ECC. On the other hand, it is standard to find ECC in high-end (server) systems as sold by VA Linux and Sun. These usually work with ECC memory, or at least with parity memory. I believe that most common PCs are capable of working with ECC memory, they just don't get that memory plugged in because ECC RAM is more expensive. Yes, this is the low-quality world of PCs blinking an eye at you.
With parity RAM or ECC RAM it would be possible to detect errors on the fly, without the need for a special program like memtest86. Currently however, the BadRAM patch we present here is kept as simple as possible (to increase chances of acceptance in mainstream kernels) and, therefore, does not deal with the added possibilities of ECC RAM.
We assume a memory checker like memtest86 finds errors in memory modules. As explained, this checker lists all erroneous addresses it finds. And, because a whole row or column may fail after a static discharge, this could lead to extremely long lists of errors, hundreds of errors not being an exception. Naturally, such a list would be tedious and error prone to enter into the kernel, and it may also give rise to problems caused by strictly limited resources at boot time. It would be ideal to have a very small representation of all the errors found.
Luckily, memory errors are usually laid out in regular patterns, such as starting at address 0<\#215>1234, every 0<\#215>0040 bytes, over 16 occurrences—or a bit more variation, of course.
The regularity is often easiest to see when doing binary. That is because the rows and columns are addressed by spreading address bits over these lines, and by interpreting part of the address to decide whether the used address lines fall into the correct region.
A single error can be described as an address, of which all bits are valuable information. We write this, for example, as 0<\#215>1234,0<\#215>ffff where the first number is the base address and the second number is a mask. The “1” bits in the mask indicate which of the corresponding base address bits are valuable. If, aside from this address, also the address plus 0<\#215>0040 is wrong, then we can simply alter the mask to represent this. The resulting address/mask pair now becomes 0<\#215>1234,0<\#215>ffbf. We can see that this is correct because the addresses covered are all addresses A for which (A & 0<\#215>ffbf)=0<\#215>1234, or concretely, 0<\#215>1234 and 0<\#215>1274. If there are 16 faulty addresses with this intermittent offset, then the whole thing becomes 0<\#215>1234,0<\#215>fc3f to capture faulty addresses: 0<\#215>1234, 0<\#215>1274, ..., 0<\#215>15f4.
This approach works well to capture faults over a row or column, as long as these cover a power of two for bits, which is normal. It also works to capture the specks of dust that disable a few neighboring bits on the chip. But what if a memory module contains more errors? Or, similarly, if multiple memory modules each have errors? To cover these cases, we usually assume a list of the aforementioned address/mask pairs. In practice, it turns out that five of these pairs suffice for most practical situations. Be aware that any set of errors can always be compacted in as little as one such pair, albeit with loss of good addresses, 0<\#215>0000,0<\#215>0000 being the ultimate example that captures all errors, but unfortunately, no good addresses. With five pairs, we usually have no problems that extreme.
memtest86, starting with version 2.3, is able to generate BadRAM patterns that can directly be entered on the command line of a BadRAM-patched Linux kernel. In the above example, memtest86 would report a sequence of evolving patterns, eventually leading to:
badram=0<\#215>1234,0<\#215>fb3f
Having written this down, you may now reboot the system and enter this on the command line:
LILO: linux badram=0<\#215>1234,0<\#215>fb3fand your system should boot fine, ignoring the broken memory parts. Now, go ahead and add this line to your /etc/lilo.conf:
append="badram=0<\#215>1234,0<\#215>fb3f"and run LILO. You will not have to enter the address/mask pairs anymore on consecutive boots.
My old ZX Spectrum had a nifty way to expand memory with an additional 32K. The Sinclair memory expansion kit was comprised of 64K chips, of which either the high or the low half was known to work while the other half was faulty, which made the price lower than the “proper” expansion method with 32k chips. By selecting some toggle on the motherboard, the computer was instructed which half of the expansion memory chips it should use. Basically, the BadRAM patch does the same thing, with a bit more refinement.
Memory management units, which are a necessity for all Linux distributions to work well, redirect a page as accessed by a “user space” program to any physical page. What appears like a long stretch of memory allocated just for your user process is, in reality, scattered over the memory modules (and may even be swapped out). When a user-level program allocates memory, the kernel gives it out by allocating single pages of physical memory.
The only part of Linux that works in terms of physical memory addresses is the kernel. It is loaded in the beginning of the memory (obviously, you must not have errors in that region) and may allocate blocks of memory from the same pile of free memory that is also used to serve the user process.
This pile of memory is filled with the physical pages at boot time. Actually all that the BadRAM patch does is leave out those pages that fall in one of the address/mask pairs entered on the command line.
This means that all the work involved in BadRAM is done at boot time. Afterward, the only effect is that the pile of free memory is a tad smaller. Extensive benchmarks have shown that this has no measurable influence on runtime performance.
When you make a patch like this, and certainly when you're “SlashDotted” over it, you receive a lot of interesting e-mail, some with ideas even weirder than those I thought of.
One proposal I've often heard is to perform a memory test at boot time. Although this may seem interesting, it is not practical. memtest86 does an excellent job, but it requires several hours. You don't want this at boot time, and you also don't want to have a bad memory test (we already have that in most PC BIOSes, anyway, and BadRAM modules usually pass that test). The option of making a LILO boot alternative for memtest86, or of having a memtest86 boot floppy, has always been my preference.
I have had some reports of errors in motherboards which corrupted a particular address of physical memory, perhaps due to a short circuit with an on-board peripheral. One such reporter informed me that he had put four modules of 512M in his machine to limit the chances of hitting the erroneous address, but his problems were entirely resolved by throwing out a single memory page with the BadRAM patch. Discarding 4K out of 2G made his machine work flawlessly.
I have also talked with someone who owns a PC from a large PC-at-home project. The rather proprietary architecture of his Compaq Deskpro did not foresee an option to switch off the 15M-16M memory hole needed for some ISA cards. So, expanding memory to 24M did not work on Linux 2.2 because setting mem=24M means that the region 15M-16M works as, you guessed it, a memory hole. But, after adding badram=0<\#215>00f00000,0<\#215>fff00000 to inform the kernel that the hole should be treated as BadRAM, he got his additional memory going and was ready to add even more.
Finally, I received romantic responses from people that had worked with older systems that detected memory faults (using either parity schemes or ECC schemes) and assigned a lower level of trust to such faulty pages. When a page was “under evaluation”, it would, at most, be used to load program code, the idea being that program code is a verbatim copy off a hard disk and can be restored if the error pertains. If it worked well for a while, the error apparently had been something spurious, and the page would be upgraded to “trustworthy” again. However, if program storage also didn't work, the page would be put out of use. This scheme would be very interesting to support, but it would take up CPU cycles at runtime and, therefore, should be seen as a very fancy feature.
There are a few ways to extend upon the BadRAM efficiency. It is certainly possible to exploit ECC modules, both the ones that have recoverable and unrecoverable errors. Since I lack both types of modules, unfortunately, this is beyond my current ability. Also, it burns CPU cycles and falls into the category of fancy features.
Another option would be to exploit the slab allocator in the kernel. Slabs are small, uniform and reusable memory blocks that the kernel allocates in arrays that span, as closely as possible, an integer number of memory pages. It would be possible to exploit the error address information in more detail by using BadRAM pages for slabs, thereby avoiding the allocation of slabs that overlap error addresses. Ideally this could reduce the memory loss to absolutely zero. In practice, however, it will not be far off the standard BadRAM performance because an average system does not use many slab pages at all. For this reason, I doubt if the additional CPU overhead and coding effort would be worthwhile.
It is my sincere hope that memory marketing companies will pick up this idea and start to publish (cheap) memory modules based on broken memory. I propose a schema to classify such modules with a logarithmical degree of “badness” as part of the in-kernel documentation on the BadRAM patch.
All that remains now is to wish you good luck with your chase for broken memory. Perhaps some befriended user of a less mature operating system could spare it.
