The authors have studied five libraries that can be used for multi-thread applications and herein present the results.
Recent years have seen an increase in the popularity of threads, because there are many applications in which threads are useful. In many aspects, threads operate in the same manner as processes, but can execute more efficiently. All modern operating systems today include some kind of support for thread management. Moreover, threads have been standardized by the IEEE Technical Committee on Operating Systems. This standard allows users to write portable multi-thread programs.
As with other operating systems, Linux includes multi-threading capability, and some multi-threading libraries are available for Linux. We will describe a comparative study of five threads packages for Linux: CLthreads, LinuxThreads, FSU Pthreads, PC threads and Provenzano Pthreads. All libraries evaluated make use of POSIX-compliant functionality. The main objective of this study is to evaluate and compare the performance of some multi-thread features to analyze the suitability of these libraries for use in multi-thread applications. Also, we make a comparison with Solaris threads.
A thread is an independent flow of control within a process. A traditional UNIX process has a single thread that has sole possession of the process' memory and other resources. Threads within the same process share global data (global variables, files, etc.), but each thread has its own stack, local variables and program counter. Threads are referred to as lightweight processes, because their context is smaller than the context of a process. This feature makes context switches between threads cheaper than context switches between traditional processes.
Threads are useful for improving application performance. A program with only one thread of control must wait each time it requests a service from the operating system. Using more than one thread lets a process overlap processing with one or more I/O requests (see Figure 1). In multiprocessor machines, multiple threads are an efficient way for application developers to utilize the parallelism of the hardware.
This feature is especially important for client/server applications. Server programs in client/server applications may get multiple requests from independent clients simultaneously. If the server has only one thread of control, client requests must be served in a serial fashion. Using multi-thread servers, when a client attempts to connect to the server, a new thread can be created to manage the request.
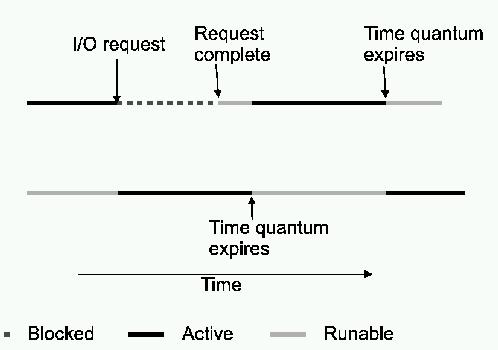
Figure 1. Overlapping Processing and I/O Requests
In general, multi-threading capabilities are of great benefit to certain classes of applications, typically server or parallel processing applications, allowing them to make significant performance gains on multiprocessor hardware, increase application throughput even on uniprocessor hardware, and make efficient use of system resources. Threads, however, are not appropriate for all programs. For example, an application that must accelerate a single compute-bound algorithm will not benefit from multi-threading when the program is executed on uniprocessor hardware.
There are two traditional models of thread control: user-level threads and kernel-level threads.
User-level thread packages usually run on top of an existing operating system. The threads within the process are invisible to the kernel. Threads are scheduled by a runtime system which is part of the process code. Switching between user-level threads can be done independently of the operating system. User-level threads, however, have a problem: when a thread becomes blocked while making a system call, all other threads within the process must wait until the system call returns. This restriction limits the ability to use the parallelism provided by multiprocessor platforms.
Kernel-level threads are supported by the kernel. The kernel is aware of each thread as a scheduled entity. In this case, a set of system calls similar to those for processes is provided, and the threads are scheduled by the kernel. Kernel threads can take advantage of multiple processors; however, switching among threads is more time-consuming because the kernel is involved.
There are also hybrid models, supporting user-level and kernel-level threads. This gives the advantages of both models to the running process. Solaris offers this kind of model.
Threads have been standardized by the IEEE Technical Committee on Operating Systems. The base for the POSIX standard (POSIX 1003.1), The Portable Operating Systems Interface, defines an application program interface which is derived from UNIX but may as well be provided by any other operating system. This standard includes a set of Thread Extensions (POSIX 1003.1c). These thread extensions provide the base standard with interfaces and functionality to support multiple flows of control within a process. The facilities provided represent a small set of syntactic and semantic extensions to POSIX 1003.1 in order to support a convenient interface for multi-threading functions.
The interfaces in this standard are specifically targeted at supporting tightly coupled multitasking environments, including multiprocessor systems and advanced language constructs. The specific functional areas covered by this standard and their scopes include:
Thread management: creation, control and termination of multiple flows of control in the same process under the assumption of a common shared address space.
Synchronization primitives: mutual exclusion and condition variables, optimized for tightly coupled operation of multiple control flows within a process.
Harmonization: with the existing POSIX 1003.1 interfaces.
Multi-threading capability is included in the Linux 2.0 kernel. There is an ongoing effort to refine this and make the kernel more reentrant. The multi-thread capability is offered by the clone system call, which creates a new context of execution. This call can be used to create a new process, a new thread or one of a range of possibilities which doesn't fit into either of these categories. The fork system call is actually a call to clone with a specific set of values as parameters, and the pthread_create function call could be a call to clone with a different set of values as parameters.
The clone system call has several flags to indicate how much will be shared between threads. Figure 2 lists each flag.

Figure 2. Flags of the clone System Call
Threading capabilities are given by different threads packages. Several threading libraries are available for Linux. All libraries referred to in this article make use of POSIX-compliant functionality; however, at the time of this writing, there are no fully POSIX-compliant multi-threading libraries available for Linux.
The libraries we have evaluated are the following:
Provenzano threads (PT): this package offers a user-level POSIX threads library with thread-blocking system calls (read, write, connect, sleep, wait, etc.) and a thread-safe C library (stdio, network utilities, etc.). This implementation currently supports basic functionality, synchronization primitives, thread-specific data and thread attributes.
FSU_Pthreads (FSUT): this is a C library which implements user-level POSIX threads for different operating systems: Solaris 2.x, SCO UNIX, FreeBSD, Linux and DOS. This implementation supports thread management, synchronization, thread-specific data, thread priority scheduling, signals and cancellation.
PC threads (PCT): this is a user-level POSIX threads library that includes non-blocking select, read and write. This library has runtime configurable parameters, such as clock interrupt interval, default thread-scheduling policy, default thread-stack size and the I/O polling interval, among others.
CLthreads (CLT). CLthreads is a kernel-level POSIX-compliant library on top of Linux. CLthreads uses the clone system call to take full advantage of multiprocessor systems.
LinuxThreads (LT). LinuxThreads is an implementation of POSIX threads for Linux. LinuxThreads provides kernel-level threads: they are created using the clone system call, and all scheduling is done in the kernel. This approach can take full advantage of multiprocessor systems. It also results in a simpler, more robust thread library, especially for blocking system calls.
Solaris supports a hybrid model of threads—user-level and kernel-level threads—and a POSIX-compliant library. User-level threads are supported by the library for their creation and scheduling, and the kernel is not aware of these threads. Solaris defines an intermediate level of threads as well, the lightweight process (LWP). LWPs are between user-level threads and kernel-level threads (see Figure 3). LWPs are manipulated by the thread library. The user-level threads are multiplexed onto the LWPs of the process (each process contains at least one LWP), and only threads currently connected to LWPs accomplish work. The rest are either blocked or waiting for an LWP on which they can run.
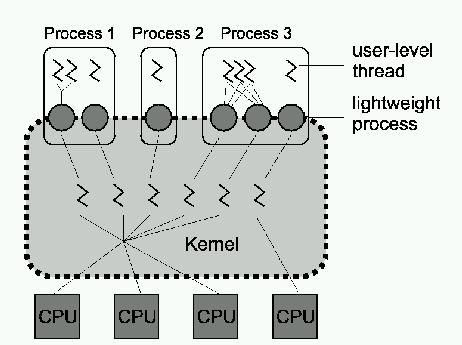
Figure 3. Threads in Solaris
There is a kernel-level thread for each LWP, and some kernel-level threads run on the kernel's behalf and have no associated LWP. Kernel-level threads are the only objects scheduled within the system.
With this model, any process may have many user-level threads. These user-level threads may be scheduled and switched among kernel-supported lightweight processes without the intervention of the kernel. Each LWP is connected exactly to one kernel-level thread. Many LWPs are in a process, but they are needed only when threads need to communicate with the kernel; if one blocks, the others can continue to execute within the process. In Solaris, users can create new threads permanently bound to an LWP.
Figure 4 summarizes the user-level and kernel-level features of the evaluated libraries.

Figure 4. Kinds of Libraries
This section describes performance metrics used to evaluate the POSIX-thread libraries, the results obtained for all, and the hardware platform used in the evaluation.
Performance metrics are an essential element in the evaluation and use of a system. To this end, a set of performance metrics was defined to evaluate and compare the two main features of all POSIX thread libraries: thread management and synchronization management.
The thread management metrics were aimed at evaluating the efficiency of the creation and termination of threads. These metrics are:
Thread creation: measurement for thread creation time, e.g., time to perform the pthread_create operation.
Join a thread: time needed to perform the pthread_join operation on a terminated thread.
Thread execution: time needed to execute the first instruction of a thread. This time includes the thread creation time and the time to perform a seched_yield operation, as shown below:
thread_1()
{ . . .
start_time();
pthread_create(...);
sched_yield();
. . . }
thread_2()
{
end_time();
... }
Thread termination: time interval from when a pthread_exit operation is performed until the pthread_join operation on this thread is finalized, as shown below:
thread_1()
{ . . .
start_time();
pthread_exit(...);
. . . }
thread_2()
{ . . .
pthread_join();
end_time();
... }
Thread creation versus process creation: compares the time needed to create a process with the time needed to create a thread within a process.
Join a thread versus wait for a process: compares the time needed to perform a wait operation on a finalized process with the time needed to perform a pthread_join operation on a finalized thread.
Granularity of parallelism: this is the minimum number of iterations of a null loop to be executed in n threads simultaneously before the time needed by the n threads is less than the time needed for a single thread to execute the total number of iterations by itself. The time for the n thread case has to include the time to create all n threads and wait for them to terminate. This number can be used by a programmer to determine when it might be advantageous to divide a task into n different pieces which can be executed simultaneously. This metric is provided for n, with n being the number of processors on the machine.
These metrics are concentrated in the mutex and condition-variables operations performance.
Mutex init: time interval needed to perform the pthread_mutex_init.
Mutex lock: time interval needed to perform the pthread_mutex_lock on a free mutex.
Mutex unlock: time interval needed to perform the pthread_mutex_unlock.
Mutex lock/unlock with no contention: time interval needed to call pthread_mutex_lock followed immediately by pthread_mutex_unlock on a mutex that is being used only by the thread doing the test. This test is shown below:
thread()
{ . . .
start_time();
pthread_mutex_lock(...);
pthread_mutex_unlock(...);
end_time();
. . . }
Mutex destruction: time needed to perform the pthread_mutex_destroy operation.
Condition init: time interval needed to perform the pthread_cond_init.
Condition destroy: time needed to perform the pthread_cond_destroy operation.
Synchronization time: measures the time it takes for two threads to synchronize with each other using two condition variables, as shown below:
thread_1()
{ . . .
start_time();
pthread_cond_wait(c1,...);
pthread_cond_signal(c2);
end_time();
. . . }
thread_2()
{ . . .
pthread_cond_signal(c2);
pthread_cond_wait(c1,...);
. . . }
Mutex lock/unlock with contention: time interval between when one thread calls pthread_mutex_unlock and another thread that was blocked on pthread_mutex_lock returns with the lock held.
thread_1()
{ . . .
pthread_mutex_lock(...);
start_time();
pthread_mutex_unlock(...);
. . . }
thread_2()
{ . . .
pthread_mutex_lock(...); < Blocked >
end_time();
pthread_mutex_unlock(...);
. . . }
Condition variable signal/broadcast with no waiters: time needed to execute pthread_cond_signal and pthread_cond_broadcast if there are no threads blocked on the condition.
Condition variable wake up: time from when one thread calls pthread_cond_signal and a thread blocked on that condition variable returns from its pthread_cond_wait call. The condition and its associated mutex should not be used by any other thread.
thread_1()
{ . . .
pthread_mutex_lock(...);
start_time();
pthread_cond_signal(...);
pthread_mutex_unlock(...);
. . . }
thread_2()
{ . . .
pthread_mutex_lock(...);
pthread_cond_wait(...);
end_time();
pthread_mutex_unlock(...);
. . . }
All results were obtained by running the benchmarks on a PC with a dual Pentium Pro Processor. The Pentium Pro Processor is a 32-bit processor with the RISC technology. This processor uses dynamic execution, a combination of improved branch prediction, speculative execution and data flow analysis. The clock speed of the computer was 200MHz, and it was equipped with 64MB of memory and a 2GB hard disk.
The tests were all performed ten times and the mean of the measurements was taken as the result for the test. This result is an indication of the performance of the function being evaluated. We have considered average values, because they are more representative of the performance the user can obtain from the machine. Other authors consider minimum values, because they are supposed to be free from the influence of the operating system and other users. The tests were taken with only one user on the machine. All tests compared the performance obtained for Solaris threads, Provenzano threads (PT), FSU_Pthreads (FSUT), PC threads (PCT), CLthreads (CLT) and LinuxThreads (LT). Threads created in Solaris are permanently bound to an LWP to take full advantage of the hardware platform used.
The numbers presented in Figure 5 are the results of the thread-management measurements. All values are given in microseconds, except for granularity of parallelism where values are given in number of iterations. In general, it can be seen that user-level packages are more efficient than kernel-level packages and Solaris threads, since the threads are created on top of the operating system and are invisible to the kernel; however, these libraries are not useful for multi-threaded applications running on multiprocessor systems. This is true for Provenzano threads and FSU_Pthreads, although PC threads present more time-consuming results. Results for granularity of parallelism are shown for kernel-level libraries (Solaris, CLthreads and LinuxThreads); user-level libraries cannot execute multiple threads in more than one processor. Figure 5 shows how Solaris can take better advantage of multiprocessor architecture. Comparing thread execution and granularity of parallelism results, we can see that context switching is more time-consuming for Linux threading (CLthreads and LinuxThreads) than for Solaris threading. LinuxThreads can take better advantage of multiprocessor systems than CLthreads can.
Figure 5. Thread Management Results
Figure 6 depicts the results of synchronization management measurements. PC threads (PCT) is less efficient, although it is a user-level library. Results show that Provenzano threads is the best user-level library evaluated, and LinuxThreads is a good kernel-level library for use in Linux machines.
Our objective was to evaluate and compare the performance of five POSIX thread libraries available for Linux and how they compared with other operating systems, such as Solaris. Results were concentrated in thread-management and synchronization-management measurements. Primary results show Provenzano threads to be the best user-level library, and LinuxThreads is a good kernel-level library. Moreover, results show that context switching is more time-consuming for Linux threading (CLthreads and LinuxThreads) than for Solaris threading.

