A description of this new technology and its impact on machine performance.
In 1998, AMD (Advanced Micro Devices) released a new family of x86 CPUs that included 3DNow! capability. 3DNow! is designed to deliver enhanced performance for certain multimedia and floating-point operations. Other x86 clone CPU manufacturers, such as Cyrix and IDT (Integrated Device Technology, Inc.), also initially pledged to support 3DNow! in forthcoming CPUs. Currently, 3DNow! support is provided by IDT's most recent generation of processors (WinChip 2) as well as by AMD's K6-2, K6-3 and Athlon (K7) families of processors.
In this article, we'll describe the 3DNow! technology (especially how it impacts performance on the popular K6-2 and K6-3 CPUs) and show how to detect and take advantage of 3DNow! using Linux. 3DNow! is an exciting development; using it effectively can unleash outstanding performance by AMD and IDT processors.
3DNow! builds on the Intel MMX (multimedia extensions to x86) capability. Ariel Ortiz Ramirez described MMX and how to utilize it with Linux in issue 61 of Linux Journal, so we won't go into much detail here about MMX. Briefly stated, MMX adds eight 64-bit “multimedia” registers (MM0 through MM7), and 57 instructions that operate on those registers, to the x86 platform. Multiple short integers can be stored (packed) into each multimedia register, and the MMX instructions allow parallel computations on these packed integers. While MMX is restricted to operation on integers, 3DNow! extends the multimedia registers by enabling multiple (two) single-precision floating-point numbers to be stored (packed) into each of them. The 3DNow! instruction set includes 21 new operations on the multimedia registers. The majority of these instructions provide fast, pipelined single-precision (packed) floating-point computation.
3DNow! capability is well-suited for fast calculation of common graphics operations such as clipping, lighting and 3-D transformations, as well as special effects involving application of physical models (e.g., fog, cloud and gravity effects). However, any application with a fair amount of floating-point computations can benefit from use of 3DNow! When used effectively, 3DNow! can increase the floating-point throughput of an application by a factor of two to four (or even more for some special-purpose applications). The increased performance results because each 3DNow! operation produces two outcomes (packed into each multimedia register), whereas standard floating-point operations by the floating-point unit (FPU) produce only one outcome per operation.
Furthermore, in the AMD K6-2 and K6-3, the MMX and 3DNow! operations have access to dual pipelined execution units, enabling up to two 3DNow! operations to execute simultaneously. Thus, up to four results can be computed per processor clock cycle on the K6-2 and K6-3. (This compares to a maximum of one floating-point result per clock cycle for the Pentium II; thus, a PII/450 has a peak performance of 450 MFLOPS (million floating-point operations per second) while a K6-2/450 has a peak performance of 1800 MFLOPS). The standard floating-point computations on the AMD K6-2 and K6-3 are not pipelined, which means there is a delay of two or more clock cycles between each concluded standard floating-point computation. Using the 3DNow! capability can turbo-charge the floating-point throughput of programs that utilize 3DNow! instructions. For computers equipped with an AMD K6-2, K6-3 or IDT WinChip2, peak floating-point performance is possible only for programs that contain 3DNow! instructions.
Unfortunately, few compilers can generate 3DNow! instructions for compiled code. Thus, to exercise the 3DNow! capability in programs written in high-level languages such as C/C++, FORTRAN or Pascal, it's necessary to include explicit assembly code which has 3DNow! operations. This is not difficult to do, so we will demonstrate how to use 3DNow! in C/C++ programs in Linux.
One way to determine whether a given machine supports 3DNow! is to download and run an application that identifies the processor and checks for 3DNow! capability. AMD has an application of this type that can be downloaded from their corporate web site. A practical solution for determining from within a program whether the host CPU supports 3DNow! is to use the CPUID instruction, which returns information on processor features and is supported by the entire x86 family. If a program determines that 3DNow! support is present, it can exercise the appropriate sections of code which utilize 3DNow! Specifically, 3DNow! support can be determined by calling the instruction CPUID 8000_0001h. This instruction sets flag bits in the EDX register according to the CPU's level of multimedia support. Bit 31 of the EDX register indicates whether there is 3DNow! support; thus, CPUID sets this bit to 1 if the CPU supports 3DNow! If bit 30 is also set to 1, the CPU supports the enhanced extensions to 3DNow! available in the new AMD Athlon processor.
Some assemblers include support for 3DNow! instructions; assembly language modules that include 3DNow! instructions will be assembled without difficulty by such assemblers. However, many assemblers do not include direct support for 3DNow! In many cases, it is still possible to use 3DNow! instructions with those assemblers, although it will be necessary to define the instructions as pseudo-instructions using data blocks or emits. Fortunately, AMD's web site has a C++ header file that contains macro definitions for the 3DNow! instruction set. Inclusion of this header file can enable development of embedded assembly code within higher-level language programs. These macros specify the hexadecimal decoding for the 3DNow! instructions using the emit pseudo-instruction; the header file may need to be modified for certain compilers, as not all of them support emit. Under Linux, we used the freely available Netwide Assembler (NASM) to assemble code. NASM allows pseudo-instruction macros to be built using the db command. We have created a header file that defines the 3DNow! instructions using the db commands. This header file is available for download from http://merlin.cs.uah.edu/visgig/threednow/. However, NASM versions from 0.98 and beyond support 3DNow!, so the header file is needed only with older versions. Incidentally, we found that NASM 0.97 doesn't allow MM2, MM3, MM6, or MM7 to be result registers for 3DNow! operations. NASM 0.98 has no such problem.
Some applications are especially well-suited for 3DNow!, such as graphics rendering. Optimizing applications with a tiny amount of isolated floating-point operations may not be worth the effort, due to the extra time associated with coding in assembly language. There are several criteria to look at before deciding whether to use 3DNow! with the K6-2 or K6-3. First, the application should have at least a few single-precision floating-point computations grouped in one part of the program, as there is some overhead involved in switching into MMX/3DNow! mode. While in MMX/3DNow! mode, standard floating-point operations that use the regular FPU are not possible. Standard integer operations are fine while in MMX/3DNow! mode. The new K7 reportedly won't have this overhead. The MMX mode switch can also break up internal instruction pipelining, which could add overhead. The best way to minimize the impact of the overhead is to use 3DNow! in units that contain several single-precision floating-point operations. Performance will also be improved if the floating-point data is organized in a successive, regular format (such as arrays of floating-point numbers) that enables a series of 3DNow! operations to be performed in sequence.
One application that can be efficiently implemented using 3DNow! is an image gradient calculation (edge detection), especially range image gradients. To illustrate how 3DNow! can enable efficient operations on Linux, we'll be looking at how the gradient calculation can be optimized for range and volume data. In an image collected on a 2-D grid, gradient is a measure of the local change of pixel values (e.g., pixel intensity) at a particular point; in a 3-D volume, gradient measures the difference of intensity between a voxel (volumetric element) and its neighbors. There are a variety of methods for determining the gradient. For an image collected on a grid, one way to compute the gradient is as the directional differences in value of the four immediate neighbors (to the north/south and east/west) of each pixel. When this difference is computed for the entire image, the result is that points that lie on the border between regions usually have strong gradient magnitudes. The gradient magnitudes can be viewed as an image—they look like a collection of region boundaries of the original image. The image in Figure 1 is a range image produced from laser-range data. In a range image, each pixel is a floating-point value which expresses the distance from the viewing plane of the corresponding point on the imaged object. We've displayed the image using intensities where brighter values indicate closer points. Figure 2 shows the computed four-direction gradient for the range image of Figure 1.

Figure 1.
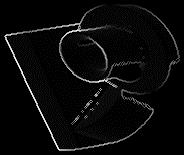
Figure 2.
In general, the gradient magnitude at a particular point is given by the equation
|Gradient|=sqrt((0.5*delta(
where delta(x) is equal to the change in pixel intensity in the x direction and delta(y) is the change in the y direction. We've illustrated the gradient for pixel P1 in Figure 3. P1's gradient magnitude is:
Gradient(P1)=sqrt(0.25*((depth(P2)-depth(P0)) +(depth(P4)-depth(P6))<+>2<+>)).
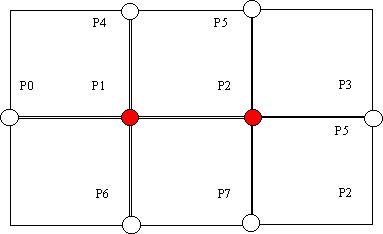
Figure 3.
3DNow! is well-suited to perform this computation for range images. Since range images can be stored as an array, points that lie next to each other on a row will appear consecutively in memory. MMX has an instruction, movq, that moves a “quadword” (four words—two single-precision floats) from memory into a multimedia register. This means consecutive image pixels P4 and P5 can be loaded into a multimedia register with one move. If P6 and P7 are loaded into another MMX register, we can use the 3DNow! operation PFSUB to subtract the contents of pairs of registers. The result of one 3DNow! subtraction will be the delta(y) for both P1 and P2. One more subtraction can yield delta(x) for these pixels. Additionally, 3DNow! operations can be used to square delta(x) and delta(y), to add them together, to apply the multiplicative factor and take the square root. The whole process can be implemented using fewer assembly instructions (and about half the execution time) than would be required for implementations using standard floating-point instructions.
We developed the assembly language function XYGRAD to assist in calculating range image gradients. (The code for this function can be found in the archive file ftp.linuxjournal.com/pub/lj/listings/issue68/3685.tgz.) The function processes a single row of image pixels at a time using 3DNow!. XYGRAD can be called from any C program using the prototype shown in the code. After assembling XYGRAD with NASM, gcc is used to link it with a C program that utilizes XYGRAD.
XYGRAD is passed as a pointer to the original image, called img_ptr, along with the size of the row to process. The function steps through each image row four pixels at a time. For a set of four pixels, the change in intensity in the x direction is calculated first. The quadword containing P0 and P1 is moved with movq into MMX register MM0. P2 and P3 are moved into the MM1 register. These registers are then subtracted using the 3DNow! packed subtraction (i.e., PFSUB MM0, MM1). The result is stored in the first operand, MM0, which is later squared using the packed multiplication operation (PFMUL MM0, MM0). Similar steps are followed to calculate the gradient in the y direction, with the squared difference being stored in the MM2 register. MM0 and MM2 are then added to get delta(x)<+>2<+> +delta(y)<+>2<+>, which is stored in the output array referenced by result_img_ptr. After the whole image has been processed, a second 3DNow!-optimized module is called by the C program to calculate the square root of each pixel in the resulting image. This completes the gradient calculation. The complete source code for both the C and assembly modules used in the range image gradient calculation program can be downloaded from http://merlin.cs.uah.edu/visgig/threednow/gradient/.
One thing we kept in mind during the coding process is the ability of the K6-2 and K6-3 CPUs to pipeline instructions in two execution pipelines. Due to the architecture of these processors, certain restrictions apply to the pipelining of 3DNow! instructions. Namely, each 3DNow! instruction belongs to one of two subsets, and two instructions from the same subset cannot be issued in parallel. For instance, the packed floating-point subtraction (PFSUB) and packed floating-point addition (PFADD) both belong to the same subset, and therefore cannot be issued in the same clock cycle. On the other hand, the packed floating-point multiplication (PFMUL) belongs to the other subset of 3DNow! instructions; therefore, PFMUL and PFADD instructions can execute simultaneously, provided there is no operand dependency between them. It's beneficial to interweave instructions from each subset as much as possible to increase the likelihood of parallel computation. Most integer MMX operations do not have such a restriction on the K6-2 and K6-3; achieving optimal floating-point performance does require a little more consideration by the programmer.
Our 3DNow!-optimized gradient-calculation programs delivered excellent performance. We conducted tests of the programs on a dual-bootable PC with a 300MHz AMD K6-2 CPU to determine 3DNow! performance in both Windows and Linux environments. On Linux, we used the Netwide Assembler (NASM) version 0.98 to assemble the assembly modules. We used GNU C (gcc) version 2.7 to compile a C driver and link the driver to the assembly code. On Windows, we used a popular commercial C compiler to assemble, compile and link the assembly and C codes. The Windows assembler/compiler did not recognize 3DNow! instructions, so we had to include the AMD header file that defines 3DNow! using the pseudo-instruction macros. We tested the 3DNow!-optimized gradient calculations on several range images and 3-D volumes.
Tables 1 and 2 show performance results for two representative data sets. In Table 1, the average CPU times for execution of the 3DNow!-optimized range image gradient calculation in Linux and Windows environments are shown. (Times are averaged over 2000 trials for a 240x240 range image.) By comparison, the 3DNow!-optimized code ran about nine times faster under Linux than unoptimized standard C code which computes the data according to the same pattern of pixel access, i.e., the unoptimized code was implemented purely in C without use of 3DNow! and was compiled without any compiler optimizations. When the standard C version of the gradient was compiled with maximal optimizations by gcc in Linux (using optimization switches of -O2 -ffast-math), it was still more than three times slower than the 3DNow!-optimized code. This time, improvement is significant; the 3DNow!-optimized version of the range image gradient calculation can be done in real time at frame rates under Linux. The performance improvement was nearly as impressive for the volume gradient computations—the times shown in Table 2 are for a 72x256x256 volume. The 3DNow!-optimized volume gradient executed more than 2.5 times faster than fully optimized standard C implementation, and better than 4.5 times faster than an unoptimized standard C implementation.
We've also tested the performance of the standard C range image gradient implementation (i.e., the implementation without 3DNow! code) on a Pentium II/333 running Linux. Using full compiler optimizations, the 240x240 range image's gradient was computed in 17% more time on the PII than on the K6-2. Thus, we estimate that the K6-2 can calculate range image gradient under Linux about 30% faster than a comparably clocked PII. Of course, we should add that it's generally easier to develop modules in C than in assembly language.
3DNow! is an exciting development for desktop computing, offering the potential for significantly improved performance for many applications. 3DNow! can be effectively utilized in Linux using NASM and gcc. For applications that involve floating-point calculations, especially those where speed is critical, incorporating modules that utilize 3DNow! instructions can unlock outstanding floating-point throughput in popular CPUs such as the IDT Winchip 2 and the AMD K6-2, K6-3 and Athlon processors.

