An introduction to the GNU gettext system for producing multilingual programs.
Linux is becoming increasingly popular each day. Until now, the typical Linux user has been a system administrator, student or UNIX hacker. New projects such as GNOME, KDE and GNUStep are preparing the way for a different, less technically prepared user.
Running software in English is usually not a problem for someone with at least moderate computer skills, but end users need (and want) software that speaks their own language in order to be productive or feel comfortable with the system. Moreover, many programs need to know local conventions for things such as dates or money amounts in order to be useful and complete.
This article is an introduction to the GNU gettext system, a set of tools and libraries for both programmers and translators that enables them to produce multilingual programs with textual messages in specified languages. We will deal with languages that use one of the ISO-8859-X character sets, except for Japanese and Chinese as they require extra care.
Two words appear frequently when talking about support of different languages in programs: internationalization and localization. Since writing these words over and over (without spelling errors) is annoying and time-consuming, people abbreviate them as I18N and L10N. The 18 and 10 indicate the number of letters between the first and the last letter of each word.
Internationalizing a program means taking the necessary steps to make it aware of different languages and national standards.
The process of localization takes place when an internationalized program is given the information needed to behave correctly with a certain language and set of cultural habits.
The first thing to do, for both programmers and end users, is configure the Linux machine to use locales. Most users need only follow the Locales mini-HOWTO downloadable from ftp://sunsite.unc.edu/pub/Linux/docs/ and mirrors. Recent distributions (for example, Red Hat 5.0) include everything to support locales.
Once the system is enabled to support locales, you must specify the particular standards and languages you wish to use. This is done through a set of environment variables. Each one controls a specific aspect of the locale system:
LANG specifies the global locale, but can be overridden by the following variables.
LC_COLLATE specifies the locale used for sorting and comparing.
LC_CTYPE specifies the character set in use, so that isupper('<\#192>') returns true in an Italian locale.
LC_MONETARY provides information about representing money in a specific locale.
LC_NUMERIC gives information about numbers: how digits are divided and separated in groups, what the decimal point is, etc.
LC_TIME specifies which locale to use to represent time: AM/PM or 24-hour values, for example.
LC_MESSAGES indicates the language you prefer for programs' text messages.
LC_ALL overrides any previous indication and sets a global locale.
Examples of values for global locale are:
en_US indicates English in the United States.
it_IT is for Italian in Italy.
fr_CA is for French in Canada.
The locale used by default, unless overridden by the previous variables, is called the C (or POSIX) locale. Thus, it is very easy to illustrate the behavior of a locale-aware program by using date, for example (see Listing 1). First, without setting the LC_ALL variable, the response is in English. Next, LC_ALL is set to obtain an Italian response, a French one (French in Canada is specified), then an English one (English in Canada). The “No such file or directory” for the Italian locale is not translated, which means the Italian information is not available; therefore, the default is used instead.
Let's have a first look at the package GNU gettext. If you don't have it installed on your system, you can download it from ftp://prep.ai.mit.edu/pub/gnu/ or its mirrors.
When writing multilingual programs with this package, strings are “wrapped” in a function call instead of being coded directly in the source. The function is called gettext and accepts exactly one string argument and returns a string.
Despite its simplicity, gettext is very effective: the string passed as an argument is looked up in a table to find a corresponding translation. If a translation is found, then gettext returns it; otherwise, the passed string is returned and the program will continue to use a default language.
Our first, internationalized Hello, world! program could be:
#include <stdio.h>
#include <libintl.h>
void main(void) {
textdomain("hello-world");
printf(gettext("Hello, world!\n"));
}
Always remember to include <libintl.h> in each C program that makes use of the gettext package.
The function textdomain should be called before using gettext. Its purpose is to select the correct “database” of messages (a more appropriate term would be “message catalog”) for the program to use.
Then, each translatable string must be used as a parameter of gettext. Writing gettext("foobar") each time can be annoying. That's why many programmers use this macro:
#define _(x) gettext(x)
By doing so, the overhead introduced by internationalization of messages is quite small: instead of writing "foobar", one can just write _("foobar"). That's only three characters more per translatable string, with the advantage that this macro eliminates the gettext code from the module completely.
Once a program has been internationalized, the localization process can begin. The first thing to do is extract all the strings needing translation from the source code.
This automatic process is carried out by xgettext. The result is an editable .po (portable object) file. xgettext scans the source files passed as parameters and extracts each translatable string marked by the programmer with gettext or some other identifier.
In our case, we can invoke xgettext in this way:
xgettext -a -d hello-world -k_ -s -v hello-world.c
The resulting hello-world.po is shown in Listing 2.
I suggest you take a look at the gettext info documentation to learn about other useful switches. The ones I used here are defined in this way:
-a extracts all strings.
-d outputs the results in hello-world.po (the default is messages.po).
-k instructs xgettext to look for _ when searching translatable strings (the defaults gettext and gettext_noop are still looked for).
-s generates a sorted output and removes duplicates.
-v tells xgettext to be verbose when it generates messages.
At this point, the translator can simply fill hello-world.po with the messages without any knowledge of the source code. In fact, a program can be internationalized and compiled, before adding the new languages.
A portable object must be compiled into a machine object (a .mo file) to be useful. This is done with the command:
msgfmt -o hello-world.mo -v hello-world.po
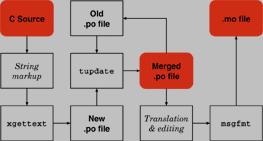
Figure 1
Figure 1. A block diagram representing all the steps necessary to obtain a .mo file from a C source. The most critical part is running tupdate (see below) to merge the new, untranslated strings with the previous work without losing it.
The final step is copying hello-world.mo to a suitable location, where it can be found by the gettext system. On my Linux box, the default location is /usr/share/locale/LL/ LC_MESSAGES/ or /usr/share/locale/LL_CC/LC_MESSAGES/, where LL is the language and CC is the country. For example, the Italian translation should be placed in /usr/share/locale/it/ LC_MESSAGES/hello-world.mo.
textdomain must be called in the beginning of the program, so that the system can select the proper .mo file according to the current locale variables. In order of precedence (higher precedence first), they are LC_ALL, LC_MESSAGES and LANG.
A .mo file can be shared among many programs if the programmers decide to make it so. This is true with GNU fileutils, for example.
If the source code changes, the corresponding .po file should be updated without losing any previous translation. Unfortunately, simply calling xgettext again does not work because it overwrites the old .po file. In this case, the program tupdate comes in handy. It merges two .po files, keeping translations already made, as long as the new strings match with the old. Its syntax is simple:
tupdate new.po old.po > latest.po
New strings will obviously still be empty in latest.po, but already translated ones will be there without the need for reprocessing.
It is not always possible to use the gettext function “straight”. Let's look at the source code excerpt in Listing 3 as an example. Two goals must be reached during the internationalization of this code. First, each translatable string must appear in the .po file. Second, before printing each string at runtime, we must pass it through gettext.
The string "You have %d %s" poses a problem. We cannot simply transform each string declared in item_names in a gettext call, because arrays must be initialized with constant values.
One solution is shown in Listing 4. gettext_noop is a marker used to make the string recognizable by xgettext (that is why it is looked for by default). The translation occurs at run time with the normal gettext call.
The .po files have a very simple text structure and can be modified with any text editor. Among others, Emacs can be put in a special po mode when dealing with them.
Each message file consists of a sequence of records. Each record has this structure:
(blank lines) # optional human comments #. optional automatic comments #: optional source code reference msgid original-string msgstr translated-string
Comments introduced by the translator should have a whitespace immediately following the # character. Automatic comments are produced by xgettext and tupdate to enhance the file's readability and to allow the translator to quickly browse the source code and find the line where a string is used. This is sometimes necessary to produce a correct translation.
Strings are formatted just like C. For example, it is legal to write:
msgid "" "Hello " "world!\n" msgstr "" "Ciao " "mondo!\n"
As you can see, strings may span across lines and the backslash is used to introduce special characters such as tabs and newlines.
No POSIX standard for message catalogs exists—the committee could not agree on anything.
GNU gettext is not the only message catalog system that can be used by an internationalized program. Another library, based on the catgets function call, also exists. The catgets interface is supported by the X/Open consortium, while the gettext interface was first used by Sun.
The main disadvantage of catgets is that a unique identifier must be chosen for each message and passed to catgets each time. This makes it quite difficult to manage a large set of messages, where entries are inserted and deleted on a regular basis. However, GNU gettext can use catgets as an underlying interface on systems that support it.
Linux supports both gettext and catgets interfaces. My personal opinion is the gettext system is much easier to use for both programmers and translators.
All listings referred to in this article are available by anonymous download in the file ftp.linuxjournal.com/pub/lj/listings/issue59/3023.tgz
